哈工大操作系统: 实验lab1~8
前言
Learning operating system by coding it!
实验0 实验环境搭建
reference1
reference2
遇到的问题:在编译linux0.11时,出现fatal error:asm/ioctl.h: No such file or directory,loctl.h这个文件是在库linux-lib-dev中的,而且我已经安装了这个库,但还是有这个错误
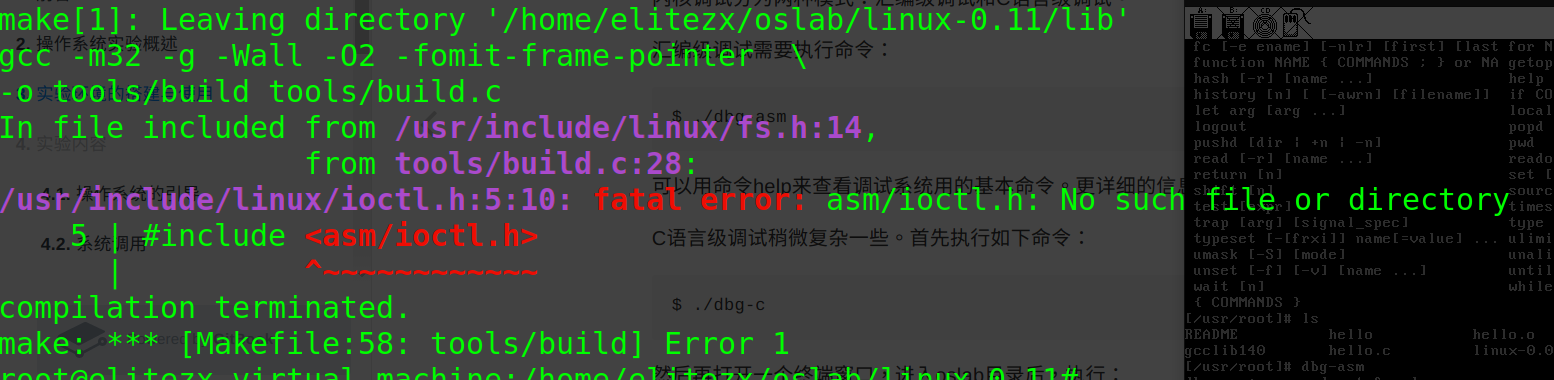
解决方法:使用i386版本的linux-libc-dev
sudo apt-get install linux-libc-dev:i386实验1 操作系统的引导
1. 改写bootsect.s
- 我们只需要
bootsect.s源码中打印字符串的部分,因为不涉及迁移bootsect从0x07c00到0x90000的操作,所以bootsect.s读入内存后还是在0x07c00的位置,因此要添加mov es, #07c0才能使es:bp指向正确的字符串起始位置。此外,cx参数的大小为字符串大小+6,这里的6是3个CR/LF (carriage return/line feed: 13 10)


- 改写
bootsect.s
entry _start
_start:
mov ah,#0x03 ! read cursor pos
xor bh,bh
int 0x10
mov cx,#34
mov bx,#0x0007 ! page 0, attribute 7 (normal)
mov bp,#msg1
mov ax,#0x07c0
mov es,ax ! set correct segment address
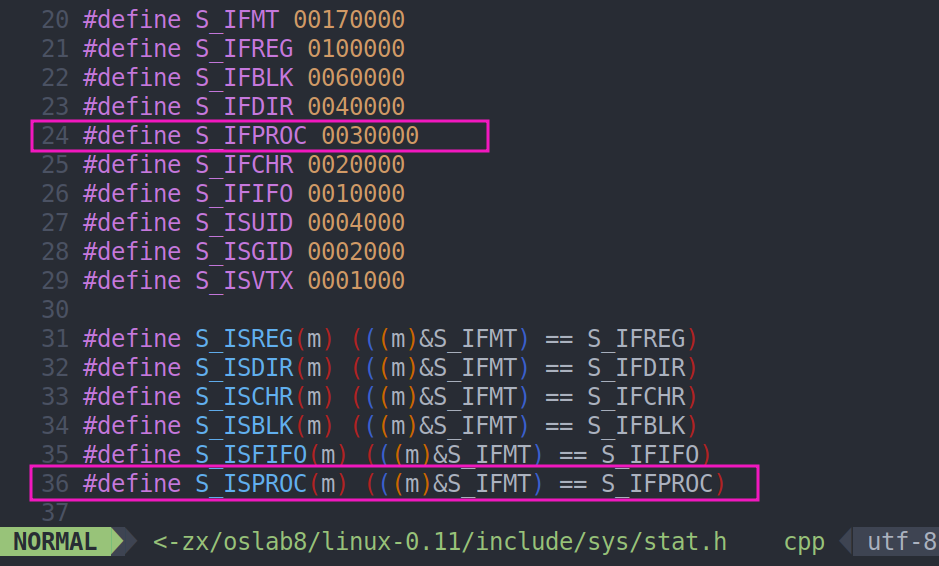
mov ax,#0x1301 ! write string, move cursor
int 0x10
inf_loop:
jmp inf_loop ! keep not exit
msg1:
.byte 13,10
.ascii "EliteX system is Loading ..."
.byte 13,10,13,10
.org 510 ! jump over root_dev
boot_flag:
.word 0xAA55 ! effective sign- 要仅汇编
bootsect.s得到Image,运行以下命令(在实模式下,as86工具用于汇编产生目标代码,ld86工具用于连接产生可执行文件)
as86 -0 -a -o bootsect.o bootsect.s
ld86 -0 -s -o bootsect bootsect.o
dd bs=1 if=bootsect of=Image skip=32- 结果
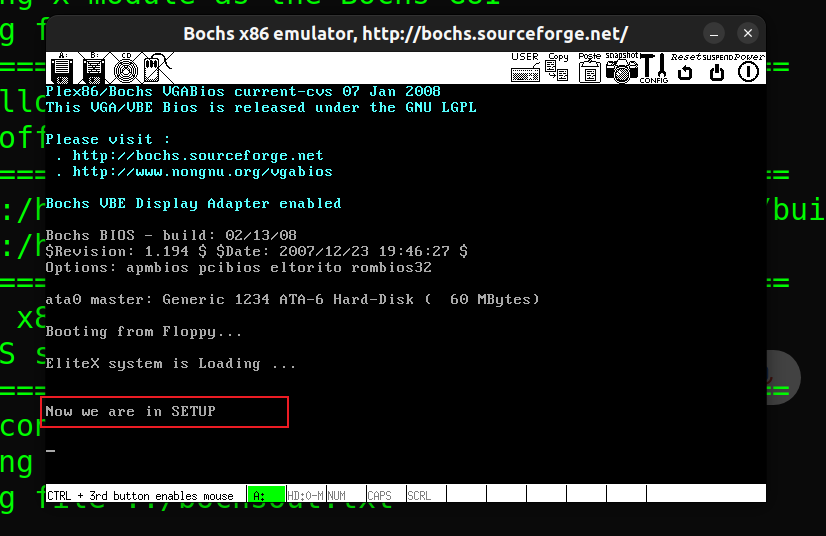
2. 改写setup.s
task1
- 在
setup.s中写入bootsect.s的内容,对字符串信息作修改,修改es为0x07e0,因为setup在内存紧跟bootsect(0x07c00 + 0x200)之后 (这里将cs的值通过ax赋给es,因为此时cs的值就是0x07e0))
entry _start
_start:
mov ah,#0x03 ! read cursor pos
xor bh,bh
int 0x10
mov cx,#25
mov bx,#0x0007 ! page 0, attribute 7 (normal)
mov bp,#msg1
mov ax,cs
mov es,ax
mov ax,#0x1301 ! write string, move cursor
int 0x10
inf_loop:
jmp inf_loop
msg1:
.byte 13,10
.ascii "Now we are in SETUP"
.byte 13,10,13,10
- 在
bootsect.s中添加源码中载入setup的部分,并修改SETUPSEG为0x07e0,原因还是在于我们没有移动bootsect**,**去掉循环并修改SETUPLEN为2,因为对我们的改写后的setup,仅需读入两个扇区就够了(其实一个扇区的大小也够了)
SETUPLEN = 1
SETUPSEG = 0x07e0
entry _start
_start:
mov ah,#0x03 ! read cursor pos
xor bh,bh
int 0x10
mov cx,#34
mov bx,#0x0007 ! page 0, attribute 7 (normal)
mov bp,#msg1
mov ax,#0x07c0
mov es,ax
mov ax,#0x1301 ! write string, move cursor
int 0x10
load_setup:
mov dx,#0x0000 ! drive 0, head 0
mov cx,#0x0002 ! sector 2, track 0
mov bx,#0x0200 ! address = 512, in INITSEG
mov ax,#0x0200+SETUPLEN ! service 2, nr of sectors
int 0x13 ! read it
jnc ok_load_setup ! ok - continue
mov dx,#0x0000
mov ax,#0x0000 ! reset the diskette
int 0x13
j load_setup
ok_load_setup:
jmpi 0,SETUPSEG
msg1:
.byte 13,10
.ascii "EliteX system is Loading ..."
.byte 13,10,13,10
.org 510 ! jump over root_dev
boot_flag:
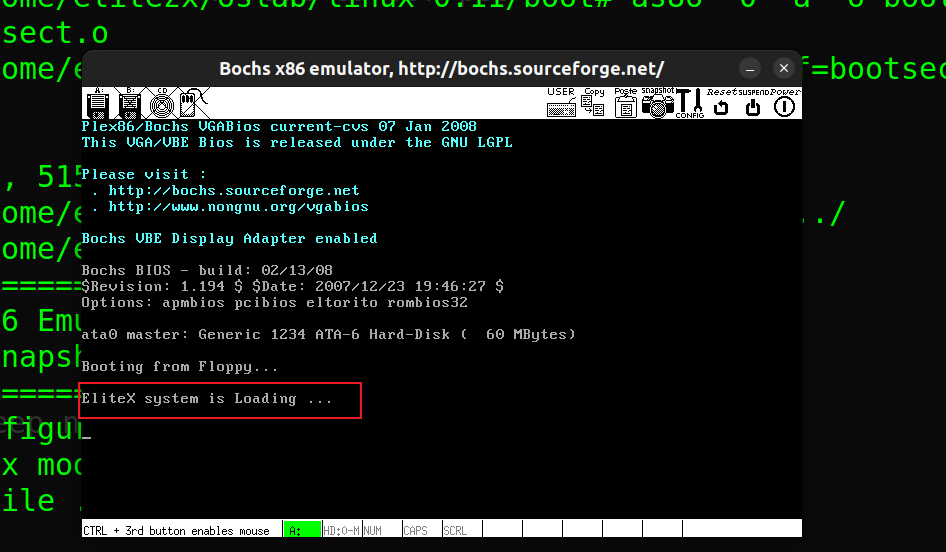
.word 0xAA55 ! effective sign- 修改
linux-0.11/tool/build.c注释掉最后部分,以便我们借助MakeFile编译bootsect.s与setup.s,而不用两个分别手动编译
- 结果
task2
- 我们需要
setup.s源码中获取硬件信息的部分,需要解决的问题是将这些数据打印在屏幕上,利用了功能号为0x0E的0x10号中断,指导书写了一个print_nl来打印回车换行符,而我直接在打印的字符串中加入13 10实现回车换行
INITSEG = 0x9000
entry _start
_start:
mov ah,#0x03 ; read cursor pos
xor bh,bh
int 0x10
mov cx,#25 ; Print "NOW we are in SETUP"
mov bx,#0x0007
mov bp,#msg2
mov ax,cs ; cs: 0x07e0
mov es,ax
mov ax,#0x1301
int 0x10
; Get Cursor Pos
mov ax,#INITSEG
mov ds,ax
mov ah,#0x03
xor bh,bh
int 0x10
mov [0],dx ; store in 9000:0
; Get Memory Size
mov ah,#0x88
int 0x15
mov [2],ax ; store in 9000:2
; Get hd0 data
mov ax,#0x0000
mov ds,ax ; modify ds
lds si,[4*0x41]
mov ax,#INITSEG
mov es,ax
mov di,#0x0004 ; store in 9000:4
mov cx,#0x10
rep
movsb
! Be Ready to Print
mov ax,cs ; 0x07e0
mov es,ax
mov ax,#INITSEG ; 9000
mov ds,ax
; print Cursor Position
mov cx,#18
mov bx,#0x0007
mov bp,#msg_cursor
mov ax,#0x1301
int 0x10
mov dx,[0] ; pass hex number through register dx to function print_hex
call print_hex
; print Memory Size
mov ah,#0x03
xor bh,bh
int 0x10
mov cx,#14
mov bx,#0x0007
mov bp,#msg_memory
mov ax,#0x1301
int 0x10
mov dx,[2]
call print_hex
; print KB
mov ah,#0x03
xor bh,bh
int 0x10
mov cx,#2
mov bx,#0x0007
mov bp,#msg_kb
mov ax,#0x1301
int 0x10
; print Cyles
mov ah,#0x03
xor bh,bh
int 0x10
mov cx,#7
mov bx,#0x0007
mov bp,#msg_cyles
mov ax,#0x1301
int 0x10
mov dx,[4]
call print_hex
; print Heads
mov ah,#0x03
xor bh,bh
int 0x10
mov cx,#8
mov bx,#0x0007
mov bp,#msg_heads
mov ax,#0x1301
int 0x10
mov dx,[6]
call print_hex
; print Secotrs
mov ah,#0x03
xor bh,bh
int 0x10
mov cx,#10
mov bx,#0x0007
mov bp,#msg_sectors
mov ax,#0x1301
int 0x10
mov dx,[12]
call print_hex
inf_loop:
jmp inf_loop
print_hex:
mov cx,#4
print_digit:
rol dx,#4 ; rotate left
mov ax,#0xe0f
and al,dl ; fetch low 4 bits
add al,#0x30 ; 0~9
cmp al,#0x3a
jl outp
add al,#0x07 ; a~f , add more 0x07
outp:
int 0x10
loop print_digit
ret
msg2:
.byte 13,10
.ascii "NOW we are in SETUP"
.byte 13,10,13,10
msg_cursor:
.byte 13,10
.ascii "Cursor position:"
msg_memory:
.byte 13,10
.ascii "Memory Size:"
msg_cyles:
.byte 13,10
.ascii "Cyls:"
msg_heads:
.byte 13,10
.ascii "Heads:"
msg_sectors:
.byte 13,10
.ascii "Sectors:"
msg_kb:
.ascii "KB"- 结果
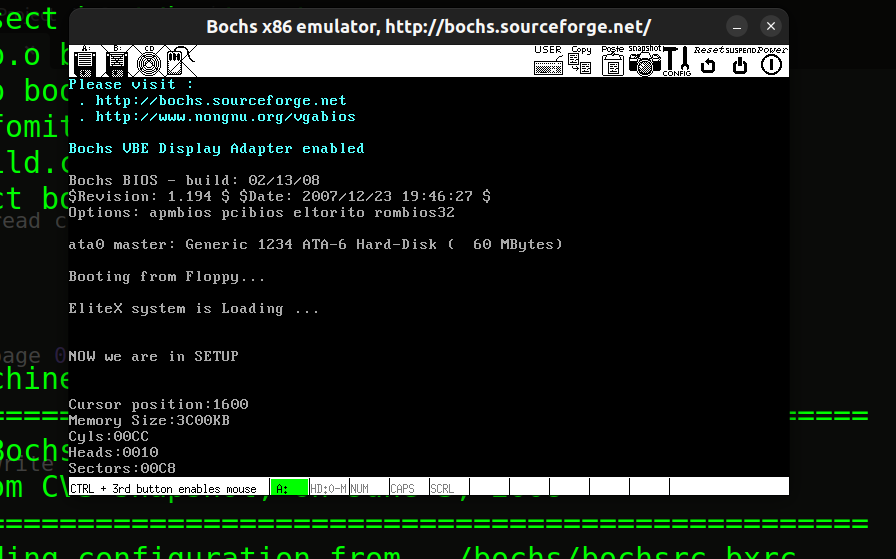
实验2 系统调用
1. 编写接口函数iam, whoami
跟write一样,在接口函数文件内调用宏函数_syscall1或_syscall2(依参数个数而定),程序内包括后续用于测试系统调用的main函数。
iam.c
#define __LIBRARY__ // 定义了这个宏,unistd.h中的一个条件编译块才会编译
#include <unistd.h>
#include <errno.h>
_syscall1(int, iam, const char*, name);
int main(int argc, char* argv[])
{
iam(argv[1]);
}whoami.c
#define __LIBRARY__
#include <unistd.h>
#include <errno.h>
#include <stdio.h>
_syscall2(int, whoami, char*, name, unsigned int, size);
int main()
{
char username[25] = {0};
whoami(username, 23);
printf("username: %s\n", username);
}2. 修改unistd.h
可以跳过这步,因为之后的编译过程所用到的unistd.h头文件并不在这个源码树下,而是在标准头文件/usr/include下。
在linux-0.11/include/unistd.h添加宏_NR_whoami、_NR_iam以在_syscall*函数中传递正确的参数给0x80号中断处理程序

3. 修改_sys_call_table函数表
在linux-0.11/include/linux/sys.h添加函数指针sys_whoami、sys_iam,函数在sys_call_table数组中的位置必须和在<unistd.h>文件中的__NR_xxxxxx的值对应上。在文件开头加上extern是让编译器在其它文件寻找这两个函数
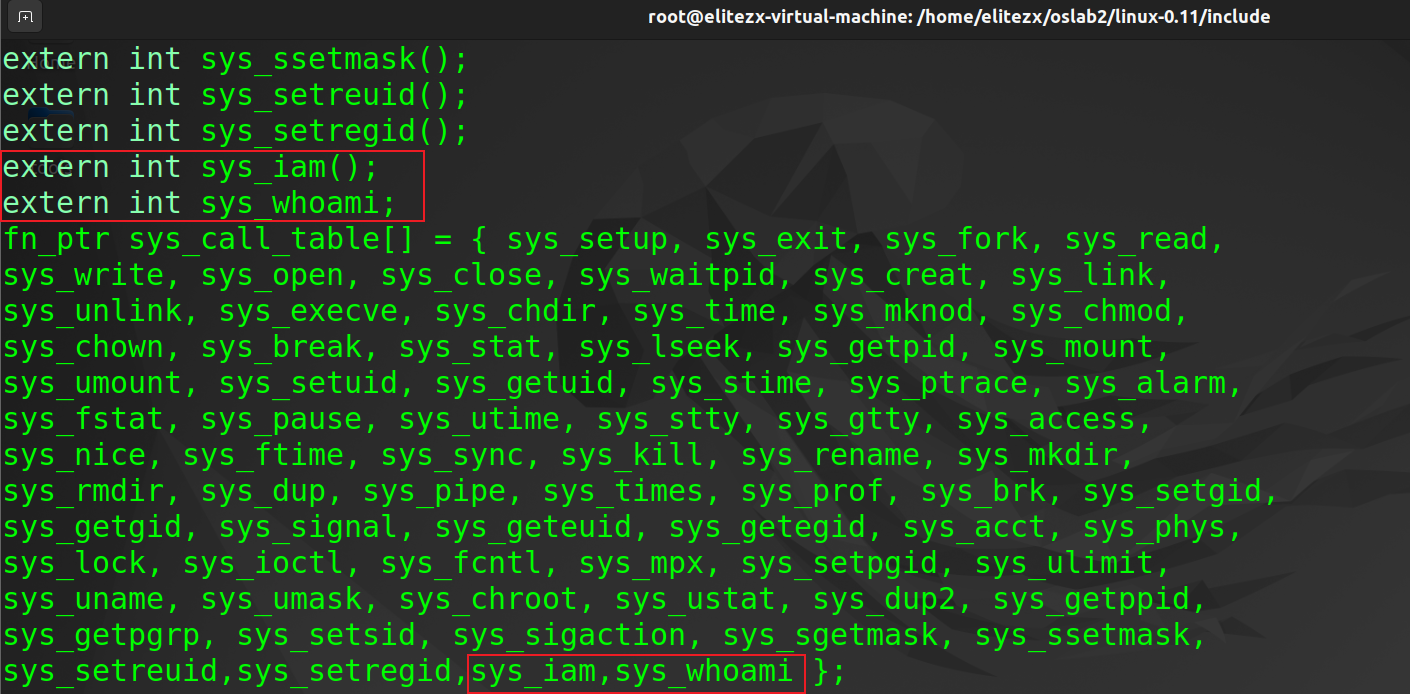
4. 实现函数sys_whoami, sys_iam
在linux-0.11/kernel/iamwho.c中编写最终的执行函数,执行这两个函数是系统调用的最后一步
在 Linux-0.11 内核中,get_fs_byte 和 put_fs_byte 函数用于在用户空间和内核空间之间传输数据。
get_fs_byte 函数从用户空间读取一个字节到内核空间。它接受一个指向用户空间内存地址的指针,并返回从该地址读取的字节。
put_fs_byte 函数则将一个字节从内核空间写入用户空间。它接受一个字节值和一个指向用户空间内存地址的指针。它将字节值写入指定的用户空间地址。
这两个函数在数据传输过程中起到了关键作用,使得内核可以与用户空间的应用程序进行安全地数据交换。
#include<string.h>
#include<asm/segment.h> // get_fs_byte, put_fs_byte
#include<errno.h>
char str_pos[24];
int sys_iam(const char* name)
{
char c ;
int i = 0;
while((c = get_fs_byte(name+i)) != '\0')
{
str_pos[i] = c;
++i;
}
if(i > 23)
{
errno = EINVAL;
return -1;
}
printk("elitezx lab2 string: %s\n",str_pos );
return i;
}
int sys_whoami(char* name, unsigned int size)
{
if(size<strlen(str_pos))
{
errno = EINVAL;
return -1;
}
int ans = 0;
char c;
while((c = str_pos[ans] )!='\0')
{
put_fs_byte(c,name++);
++ans;
}
return ans;
}5. 执行
关于这部分,指导书说的比较详细了,我这里再补充一些:挂载hdc目录到虚拟机操作系统上,实现hdc目录在linux-0.11与ubuntu22.04之间的文件共享,我们把用于系统调用的测试程序iam.c,whoami.c复制到hdc目录就可以在Bochs模拟器下的linux-0.11环境中编译执行这两个文件
sudo ./mount-hdc
cp iam.c whoami.c hdc/usr/root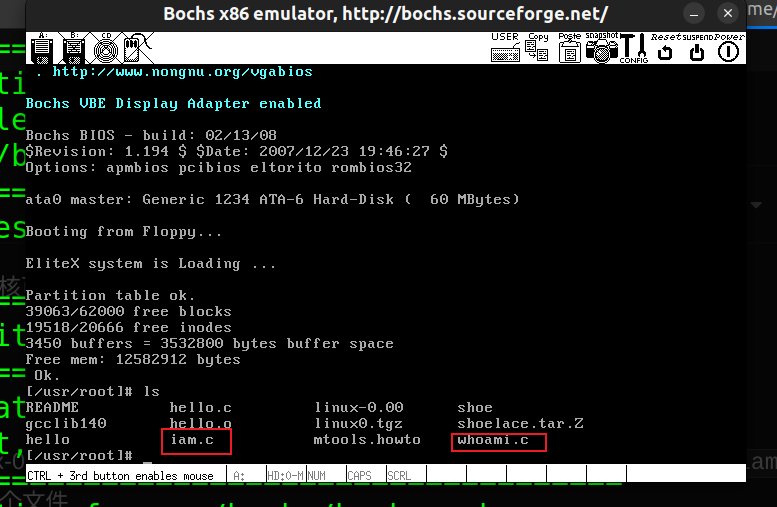
注意在iam.c,whoami.c程序内的头文件<unistd.h>是标准头文件,是由GCC编译器一同安装的,它们通常随着GCC一起打包并分发,通常位于/usr/include目录下,而不是在之前修过的源码树下的include/unistd.h, 因此我们要转入hdc/usr/include下修改<unistd.h>,加入两个宏__NR_iam,__NR_whoami
编译
gcc -o iam iam.c
gcc -o whoami whoami.c6. 验证结果
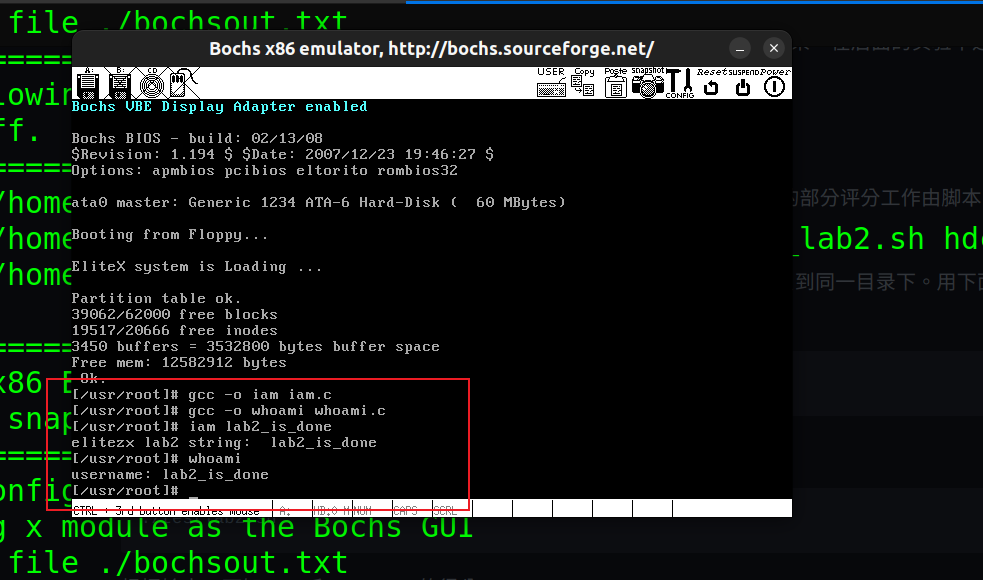
实验3 进程运行轨迹的跟踪与统计
1. 前提
1.1. 系统调用times
times系统调用接受一个struct tms*类型的参数,该结构体用于保存进程和其子进程的 CPU 时间信息,同时 times 系统调用会返回一个滴答数,即时钟周期数,该滴答数表示自OS启动以来经过的时钟周期数。
struct tms类型在include/sys/times.h中定义如下:

tms_stime和tms_utime分别记录了进程在内核态和用户态下消耗的CPU时间总和,它们的和就是进程从开始执行到调用times系统调用所经过的时间。tms_stime和tms_utime并不包括进程在睡眠状态或等待I/O操作中所消耗的时间,因此它们的和也不等于进程的实际运行时间。
注意这里时间的单位是CPU的滴答时间(tick),一个滴答数表示两个时钟中断的间隔。在Linux系统中,时钟中断通常由硬件定时器产生,定时器会以固定的频率向CPU发送中断信号。**每当时钟中断发生时,内核会将当前进程的时间片计数器减 1,内核会检查当前进程的时间片(counter)是否已经用完,如果用完了,就将当前进程放到就绪队列中,然后调用调度函数 schedule 选择一个新的进程运行。**这个频率通常是100Hz,即一秒发生100次,也就是说时间中断的间隔为10ms(1/100s),每隔10ms就发生一次时钟中断,linux内核中的jiffies变量就记录了时间中断的个数,即滴答数。那么可以看出这里的时间单位既然是滴答数,而滴答数10ms产生一个,那么实际时间应该是 (秒),100是常量HZ的值
由此,如果想获取一个进程从开始到结束的CPU使用时间,即用户态下CPU时间和内核态下CPU时间之和,可用如下函数
#include <stdio.h>
#include <sys/times.h>
#include <unistd.h>
int main() {
struct tms t;
clock_t clock_time;
// 获取进程的CPU时间统计信息
clock_time = times(&t);
// 计算进程的总的CPU时间
double cpu_time = (double)(t.tms_utime + t.tms_stime) / HZ;
printf("Total CPU time: %.2f seconds\n", cpu_time);
return 0;
}
用到的clock_t在include/time.h中定义如下
1.2. 系统调用wait
wait 函数是一个系统调用(位于include/sys/wait.h)。在Unix/Linux操作系统中,wait函数可以等待子进程结束,并获取子进程的退出状态。在使用wait函数时,如果子进程已经结束,wait函数会立即返回并返回子进程的退出状态;如果子进程还没有结束,wait函数会阻塞父进程,直到子进程结束并返回其退出状态。具体来说,wait 函数的作用如下:
1 如果当前进程没有子进程,wait 函数会立即返回 -1,并设置 errno 为 ECHILD,表示当前进程没有子进程需要等待。
2 如果当前进程有一个或多个子进程正在运行,调用 wait 函数会阻塞当前进程,直到其中一个子进程结束。当子进程结束时,wait 函数会返回该子进程的进程 ID,并将该子进程的退出状态保存到一个整型变量status中。
3 如果当前进程有多个子进程正在运行,调用wait函数会等待其中任意一个子进程结束,并且无法指定要等待哪个子进程。如果需要等待特定的子进程,可以使用 waitpid函数代替wait函数。
需要注意的是,如果当前进程没有调用wait函数等待其子进程结束,那么当子进程结束时,其退出状态可能会一直保存在内核中,直到当前进程调用wait或waitpid函数获取该状态。如果当前进程没有获取子进程的退出状态,那么该子进程就会成为僵尸进程(Zombie Process),占用系统资源并且无法被正常清理。
因此,在编写多进程程序时,通常需要在父进程中调用wait或waitpid函数等待子进程结束,并获取其退出状态,以避免产生僵尸进程。
对linux0.11 wait函数必须接受一个int参数以保存子进程退出状态,如果你不想保存该信息,可传递NULL。而在现代linux中,该参数为可选参数。
1.3. linux0.11中进程的state值
在Linux 0.11中,进程状态可以被表示为以下几个值:
TASK_RUNNING:进程正在执行,也就是说CPU正在执行它的指令。但是,如果一个进程的状态为TASK_RUNNING,而它又没有占用CPU时间片运行,那么它就是处于就绪态。TASK_INTERRUPTIBLE:进程正在等待某个事件的发生(例如,等待用户输入、等待网络数据等),它已经睡眠,并且可以响应一个信号以退出等待状态。TASK_UNINTERRUPTIBLE:和TASK_INTERRUPTIBLE一样,进程也是正在等待某个事件的发生,但是进程在等待期间不会响应信号,直到事件发生后才会退出等待状态,比如I/O操作。TASK_STOPPED:进程已经被停止,通常是收到了一个SIGSTOP信号。

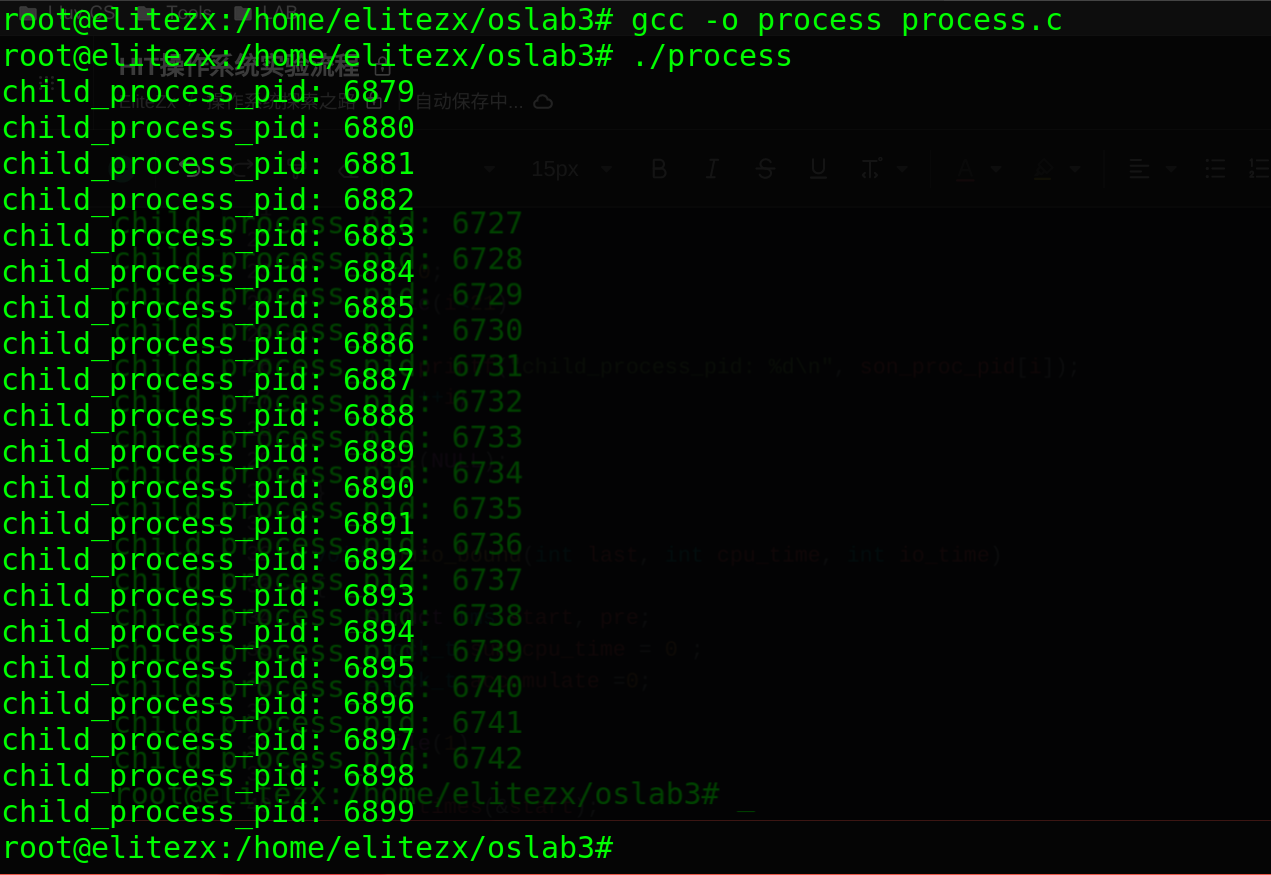
2. process.c
#include<unistd.h>
#include<stdio.h>
#include<time.h>
#include<sys/times.h>
#include<sys/types.h>
#include<sys/wait.h>
void cpuio_bound(int last, int cpu_time, int io_time);
void main(int argc, char* argv[])
{
pid_t son_proc_pid[21];
int i = 0 ;
while(i<21)
{
if(! (son_proc_pid[i] = fork()))
{
cpuio_bound(20,i,20-i);
return;
}
++i;
}
i = 0;
while(i<21)
{
printf("child_process_pid: %d\n", son_proc_pid[i]);
++i;
wait(NULL);
}
void cpuio_bound(int last, int cpu_time, int io_time)
{
struct tms start, pre;
clock_t sum_cpu_time = 0 ;
clock_t accumulate =0;
while(1)
{
times(&start);
while(sum_cpu_time < cpu_time)
{
times(&pre);
sum_cpu_time = (pre.tms_utime - start.tms_utime + pre.tms_stime - pre.tms_stime)/100;
}
if(sum_cpu_time>=last) break;
sleep(io_time);
if((accumulate+= io_time + cpu_time)>=last)
break;
}
}
3. 生成log的前置工作
- 修改
linux-0.11/init/main.c,将文件描述符3与process.log关联。文件描述符是一个非负整数,它是操作系统内部用来标识一个特定文件的引用。
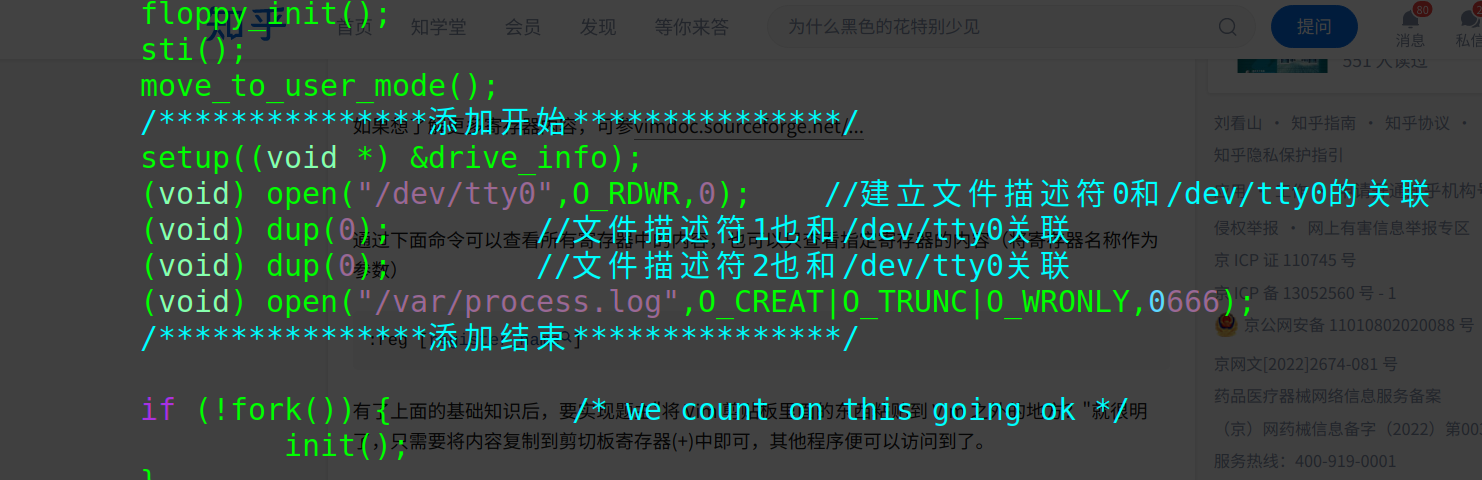
- 在内核中添加
fprintk函数用于在程序中调用以写入log文件
#include <linux/sched.h>
#include <sys/stat.h>
static char logbuf[1024];
int fprintk(int fd, const char *fmt, ...)
{
va_list args;
int count;
struct file * file;
struct m_inode * inode;
va_start(args, fmt);
count=vsprintf(logbuf, fmt, args);
va_end(args);
if (fd < 3) /* 如果输出到stdout或stderr,直接调用sys_write即可 */
{
__asm__("push %%fs\n\t"
"push %%ds\n\t"
"pop %%fs\n\t"
"pushl %0\n\t"
"pushl $logbuf\n\t" /* 注意对于Windows环境来说,是_logbuf,下同 */
"pushl %1\n\t"
"call sys_write\n\t" /* 注意对于Windows环境来说,是_sys_write,下同 */
"addl $8,%%esp\n\t"
"popl %0\n\t"
"pop %%fs"
::"r" (count),"r" (fd):"ax","cx","dx");
}
else /* 假定>=3的描述符都与文件关联。事实上,还存在很多其它情况,这里并没有考虑。*/
{
if (!(file=task[0]->filp[fd])) /* 从进程0的文件描述符表中得到文件句柄 */
return 0;
inode=file->f_inode;
__asm__("push %%fs\n\t"
"push %%ds\n\t"
"pop %%fs\n\t"
"pushl %0\n\t"
"pushl $logbuf\n\t"
"pushl %1\n\t"
"pushl %2\n\t"
"call file_write\n\t"
"addl $12,%%esp\n\t"
"popl %0\n\t"
"pop %%fs"
::"r" (count),"r" (file),"r" (inode):"ax","cx","dx");
}
return count;
}- 修改fork.c
进程在创建后就立马被设置为就绪态TASK_RUNNING
- 修改sched.c
在进程的状态切换点打印进程的状态信息
/*
* linux/kernel/sched.c
*
* (C) 1991 Linus Torvalds
*/
/*
* 'sched.c' is the main kernel file. It contains scheduling primitives
* (sleep_on, wakeup, schedule etc) as well as a number of simple system
* call functions (type getpid(), which just extracts a field from
* current-task
*/
#include <linux/sched.h>
#include <linux/kernel.h>
#include <linux/sys.h>
#include <linux/fdreg.h>
#include <asm/system.h>
#include <asm/io.h>
#include <asm/segment.h>
#include <signal.h>
#define _S(nr) (1<<((nr)-1))
#define _BLOCKABLE (~(_S(SIGKILL) | _S(SIGSTOP)))
void show_task(int nr,struct task_struct * p)
{
int i,j = 4096-sizeof(struct task_struct);
printk("%d: pid=%d, state=%d, ",nr,p->pid,p->state);
i=0;
while (i<j && !((char *)(p+1))[i])
i++;
printk("%d (of %d) chars free in kernel stack\n\r",i,j);
}
void show_stat(void)
{
int i;
for (i=0;i<NR_TASKS;i++)
if (task[i])
show_task(i,task[i]);
}
#define LATCH (1193180/HZ)
extern void mem_use(void);
extern int timer_interrupt(void);
extern int system_call(void);
union task_union {
struct task_struct task;
char stack[PAGE_SIZE];
};
static union task_union init_task = {INIT_TASK,};
long volatile jiffies=0;
long startup_time=0;
struct task_struct *current = &(init_task.task);
struct task_struct *last_task_used_math = NULL;
struct task_struct * task[NR_TASKS] = {&(init_task.task), };
long user_stack [ PAGE_SIZE>>2 ] ;
struct {
long * a;
short b;
} stack_start = { & user_stack [PAGE_SIZE>>2] , 0x10 };
/*
* 'math_state_restore()' saves the current math information in the
* old math state array, and gets the new ones from the current task
*/
void math_state_restore()
{
if (last_task_used_math == current)
return;
__asm__("fwait");
if (last_task_used_math) {
__asm__("fnsave %0"::"m" (last_task_used_math->tss.i387));
}
last_task_used_math=current;
if (current->used_math) {
__asm__("frstor %0"::"m" (current->tss.i387));
} else {
__asm__("fninit"::);
current->used_math=1;
}
}
/*
* 'schedule()' is the scheduler function. This is GOOD CODE! There
* probably won't be any reason to change this, as it should work well
* in all circumstances (ie gives IO-bound processes good response etc).
* The one thing you might take a look at is the signal-handler code here.
*
* NOTE!! Task 0 is the 'idle' task, which gets called when no other
* tasks can run. It can not be killed, and it cannot sleep. The 'state'
* information in task[0] is never used.
*/
void schedule(void)
{
int i,next,c;
struct task_struct ** p;
/* check alarm, wake up any interruptible tasks that have got a signal */
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
if (*p) {
if ((*p)->alarm && (*p)->alarm < jiffies) {
(*p)->signal |= (1<<(SIGALRM-1));
(*p)->alarm = 0;
}
if (((*p)->signal & ~(_BLOCKABLE & (*p)->blocked)) &&
(*p)->state==TASK_INTERRUPTIBLE)
{
(*p)->state=TASK_RUNNING;
/*可中断睡眠 => 就绪*/
fprintk(3,"%d\tJ\t%d\n",(*p)->pid,jiffies);
}
}
/* this is the scheduler proper: */
while (1) {
c = -1;
next = 0;
i = NR_TASKS;
p = &task[NR_TASKS];
while (--i) {
if (!*--p)
continue;
if ((*p)->state == TASK_RUNNING && (*p)->counter > c)
c = (*p)->counter, next = i;
}
if (c) break;
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
if (*p)
(*p)->counter = ((*p)->counter >> 1) +
(*p)->priority;
}
/*编号为next的进程 运行*/
if(current->pid != task[next] ->pid)
{
/*时间片到时程序 => 就绪*/
if(current->state == TASK_RUNNING)
fprintk(3,"%d\tJ\t%d\n",current->pid,jiffies);
fprintk(3,"%d\tR\t%d\n",task[next]->pid,jiffies);
}
switch_to(next);
}
int sys_pause(void)
{
current->state = TASK_INTERRUPTIBLE;
/*
*当前进程 运行 => 可中断睡眠
*/
if(current->pid != 0)
fprintk(3,"%d\tW\t%d\n",current->pid,jiffies);
schedule();
return 0;
}
void sleep_on(struct task_struct **p)
{
struct task_struct *tmp;
if (!p)
return;
if (current == &(init_task.task))
panic("task[0] trying to sleep");
tmp = *p;
*p = current;
current->state = TASK_UNINTERRUPTIBLE;
/*
*当前进程进程 => 不可中断睡眠
*/
fprintk(3,"%d\tW\t%d\n",current->pid,jiffies);
schedule();
if (tmp)
{
tmp->state=0;
/*
*原等待队列 第一个进程 => 唤醒(就绪)
*/
fprintk(3,"%d\tJ\t%d\n",tmp->pid,jiffies);
}
}
void interruptible_sleep_on(struct task_struct **p)
{
struct task_struct *tmp;
if (!p)
return;
if (current == &(init_task.task))
panic("task[0] trying to sleep");
tmp=*p;
*p=current;
repeat: current->state = TASK_INTERRUPTIBLE;
/*
*这一部分属于 唤醒队列中间进程,通过goto实现唤醒 队列头进程 过程中Wait
*/
fprintk(3,"%d\tW\t%d\n",current->pid,jiffies);
schedule();
if (*p && *p != current) {
(**p).state=0;
/*
*当前进程进程 => 可中断睡眠 同上
*/
fprintk(3,"%d\tJ\t%d\n",(*p)->pid,jiffies);
goto repeat;
}
*p=NULL;
if (tmp)
{
tmp->state=0;
/*
*原等待队列 第一个进程 => 唤醒(就绪)
*/
fprintk(3,"%d\tJ\t%d\n",tmp->pid,jiffies);
}
}
void wake_up(struct task_struct **p)
{
if (p && *p) {
(**p).state=0;
/*
*唤醒 最后进入等待序列的 进程
*/
fprintk(3,"%d\tJ\t%d\n",(*p)->pid,jiffies);
*p=NULL;
}
}
/*
* OK, here are some floppy things that shouldn't be in the kernel
* proper. They are here because the floppy needs a timer, and this
* was the easiest way of doing it.
*/
static struct task_struct * wait_motor[4] = {NULL,NULL,NULL,NULL};
static int mon_timer[4]={0,0,0,0};
static int moff_timer[4]={0,0,0,0};
unsigned char current_DOR = 0x0C;
int ticks_to_floppy_on(unsigned int nr)
{
extern unsigned char selected;
unsigned char mask = 0x10 << nr;
if (nr>3)
panic("floppy_on: nr>3");
moff_timer[nr]=10000; /* 100 s = very big :-) */
cli(); /* use floppy_off to turn it off */
mask |= current_DOR;
if (!selected) {
mask &= 0xFC;
mask |= nr;
}
if (mask != current_DOR) {
outb(mask,FD_DOR);
if ((mask ^ current_DOR) & 0xf0)
mon_timer[nr] = HZ/2;
else if (mon_timer[nr] < 2)
mon_timer[nr] = 2;
current_DOR = mask;
}
sti();
return mon_timer[nr];
}
void floppy_on(unsigned int nr)
{
cli();
while (ticks_to_floppy_on(nr))
sleep_on(nr+wait_motor);
sti();
}
void floppy_off(unsigned int nr)
{
moff_timer[nr]=3*HZ;
}
void do_floppy_timer(void)
{
int i;
unsigned char mask = 0x10;
for (i=0 ; i<4 ; i++,mask <<= 1) {
if (!(mask & current_DOR))
continue;
if (mon_timer[i]) {
if (!--mon_timer[i])
wake_up(i+wait_motor);
} else if (!moff_timer[i]) {
current_DOR &= ~mask;
outb(current_DOR,FD_DOR);
} else
moff_timer[i]--;
}
}
#define TIME_REQUESTS 64
static struct timer_list {
long jiffies;
void (*fn)();
struct timer_list * next;
} timer_list[TIME_REQUESTS], * next_timer = NULL;
void add_timer(long jiffies, void (*fn)(void))
{
struct timer_list * p;
if (!fn)
return;
cli();
if (jiffies <= 0)
(fn)();
else {
for (p = timer_list ; p < timer_list + TIME_REQUESTS ; p++)
if (!p->fn)
break;
if (p >= timer_list + TIME_REQUESTS)
panic("No more time requests free");
p->fn = fn;
p->jiffies = jiffies;
p->next = next_timer;
next_timer = p;
while (p->next && p->next->jiffies < p->jiffies) {
p->jiffies -= p->next->jiffies;
fn = p->fn;
p->fn = p->next->fn;
p->next->fn = fn;
jiffies = p->jiffies;
p->jiffies = p->next->jiffies;
p->next->jiffies = jiffies;
p = p->next;
}
}
sti();
}
void do_timer(long cpl)
{
extern int beepcount;
extern void sysbeepstop(void);
if (beepcount)
if (!--beepcount)
sysbeepstop();
if (cpl)
current->utime++;
else
current->stime++;
if (next_timer) {
next_timer->jiffies--;
while (next_timer && next_timer->jiffies <= 0) {
void (*fn)(void);
fn = next_timer->fn;
next_timer->fn = NULL;
next_timer = next_timer->next;
(fn)();
}
}
if (current_DOR & 0xf0)
do_floppy_timer();
if ((--current->counter)>0) return;
current->counter=0;
if (!cpl) return;
schedule();
}
int sys_alarm(long seconds)
{
int old = current->alarm;
if (old)
old = (old - jiffies) / HZ;
current->alarm = (seconds>0)?(jiffies+HZ*seconds):0;
return (old);
}
int sys_getpid(void)
{
return current->pid;
}
int sys_getppid(void)
{
return current->father;
}
int sys_getuid(void)
{
return current->uid;
}
int sys_geteuid(void)
{
return current->euid;
}
int sys_getgid(void)
{
return current->gid;
}
int sys_getegid(void)
{
return current->egid;
}
int sys_nice(long increment)
{
if (current->priority-increment>0)
current->priority -= increment;
return 0;
}
void sched_init(void)
{
int i;
struct desc_struct * p;
if (sizeof(struct sigaction) != 16)
panic("Struct sigaction MUST be 16 bytes");
set_tss_desc(gdt+FIRST_TSS_ENTRY,&(init_task.task.tss));
set_ldt_desc(gdt+FIRST_LDT_ENTRY,&(init_task.task.ldt));
p = gdt+2+FIRST_TSS_ENTRY;
for(i=1;i<NR_TASKS;i++) {
task[i] = NULL;
p->a=p->b=0;
p++;
p->a=p->b=0;
p++;
}
/* Clear NT, so that we won't have troubles with that later on */
__asm__("pushfl ; andl $0xffffbfff,(%esp) ; popfl");
ltr(0);
lldt(0);
outb_p(0x36,0x43); /* binary, mode 3, LSB/MSB, ch 0 */
outb_p(LATCH & 0xff , 0x40); /* LSB */
outb(LATCH >> 8 , 0x40); /* MSB */
set_intr_gate(0x20,&timer_interrupt);
outb(inb_p(0x21)&~0x01,0x21);
set_system_gate(0x80,&system_call);
}sys_pause在Linux0.11中,sys_pause()系统调用的主要作用是让进程暂停执行,直到接收到一个信号。当进程调用sys_pause()系统调用时,它会将自己的状态设置为TASK_INTERRUPTIBLE,并且将其添加到等待信号队列中。然后,进程会进入睡眠状态,直到收到一个信号或者被其他进程显式地唤醒。
这个系统调用通常用于实现等待信号的操作,比如等待一个定时器信号或者等待一个IO操作完成的信号。在这种情况下,进程可以使用sys_pause()系统调用进入睡眠状态,而不必浪费CPU资源等待信号的到来。当信号到来时,内核会唤醒进程,并且将信号传递给进程的信号处理程序进行处理。
需要注意的是,在Linux 2.6以后的版本中,sys_pause()系统调用已经被废弃,被sys_rt_sigsuspend()系统调用所取代。sys_rt_sigsuspend()系统调用可以实现类似的等待信号的操作,并且提供更多的控制选项。

- 修改exit.c
int do_exit(long code)
{
int i;
free_page_tables(get_base(current->ldt[1]),get_limit(0x0f));
free_page_tables(get_base(current->ldt[2]),get_limit(0x17));
for (i=0 ; i<NR_TASKS ; i++)
if (task[i] && task[i]->father == current->pid) {
task[i]->father = 1;
if (task[i]->state == TASK_ZOMBIE)
/* assumption task[1] is always init */
(void) send_sig(SIGCHLD, task[1], 1);
}
for (i=0 ; i<NR_OPEN ; i++)
if (current->filp[i])
sys_close(i);
iput(current->pwd);
current->pwd=NULL;
iput(current->root);
current->root=NULL;
iput(current->executable);
current->executable=NULL;
if (current->leader && current->tty >= 0)
tty_table[current->tty].pgrp = 0;
if (last_task_used_math == current)
last_task_used_math = NULL;
if (current->leader)
kill_session();
current->state = TASK_ZOMBIE;
current->exit_code = code;
fprintk(3,"%ld\tE\t%ld\n",current->pid,jiffies);
tell_father(current->father);
schedule();
return (-1); /* just to suppress warnings */
}旁注:do_exit函数与sys_waitpid函数
在 Linux 0.11 中,
do_exit()函数负责终止一个进程。当一个进程调用do_exit()时,它会执行多个清理操作,包括释放进程持有的任何资源,如打开的文件和内存,并向父进程通知进程的退出状态。如果进程有任何子进程,则do_exit()也通过递归调用do_exit()终止它们。
sys_waitpid()函数用于等待子进程终止并检索其退出状态。当进程调用sys_waitpid()时,它会阻塞,直到其中一个子进程终止。如果子进程已经终止,sys_waitpid()将立即返回该子进程的退出状态。否则,它将继续阻塞,直到子进程终止。
除了等待特定的子进程外,sys_waitpid()还可以用于等待任何子进程终止,方法是通过传递-1的pid参数。当一个进程有多个子进程并且想要等待第一个终止时,这很有用。
4. 生成log
先共享文件
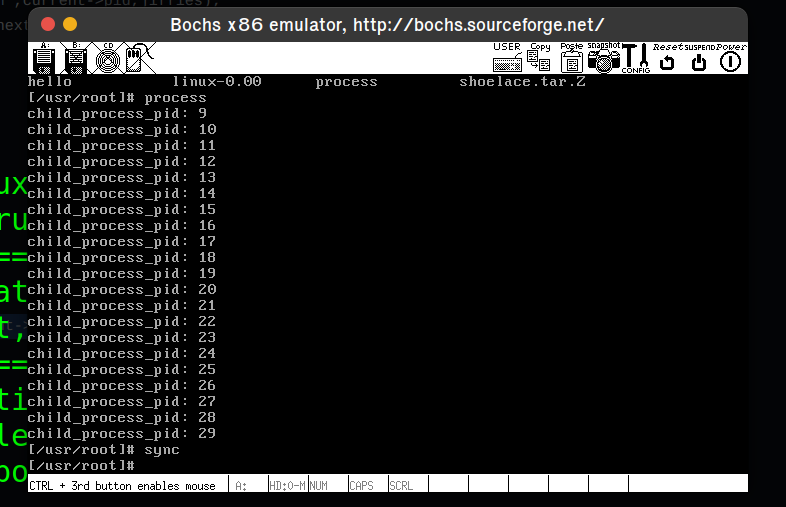
./mount-hdc移动多进程程序process.c到linux-0.11目录下
cp process.c hdc/usr/root编译运行, 最后执行一个sync命令,确保将文件系统中的所有缓存数据写入磁盘
旁注: sync命令
sync 命令是用于将文件系统中的所有缓存数据写入磁盘的命令。在 Linux 中,当一个进程修改了一个文件时,这个修改不会立即写入磁盘,而是会先被写入内存中的缓存,以提高文件系统的性能。然而,如果系统崩溃或出现其他问题,这些修改可能会丢失。因此,为了保证数据的完整性,我们需要将缓存数据定期地写入磁盘中。
sync 命令会将所有的缓存数据写入磁盘中,并将所有被修改的元数据(如 i-node、目录结构等)更新到磁盘中。这样可以保证所有的修改都被写入到磁盘中,从而避免了数据的丢失。通常在关机前执行 sync 命令,以确保所有数据都已被保存到磁盘中。
需要注意的是,执行 sync 命令并不能保证磁盘数据的完全一致性。在磁盘数据的写入过程中,如果发生了异常情况,可能会导致数据的损坏或丢失。因此,在执行 sync 命令后,建议再执行一次磁盘检查命令(如 fsck 命令)来确保文件系统的完整性。
将生成的process.log移动到虚拟机下
./mount-hdc
cp hdc/var/process.log process.log查看process.log,进程0在log关联文件描述符之前就已经在运行,因此未出现在log文件中


5. 分析log
用指导书给的py脚本程序stat_log.py分析log文件,在分析之前将py脚本文件的第一行#!/usr/bin/python改为#!/usr/bin/python2(已安装python2)以适配版本,否则在python3环境下print函数会出错
为该脚本文件分配可执行权限
chmod +x stat_log.py执行脚本,分析进程9、10、11、12的运行情况(多个指标:平均周转时间,平均等待时间)
./stat_log.py process.log 9 10 11 12 -g | less
6. 修改时间片,重新分析log
进程的时间片是进程的counter值,而counter在schedule函数中根据priority动态设置,因此进程的时间片受counter和prioriy两个变量的影响。进程的priority继承自父进程,进而所有进程的priority都来自于进程0 。
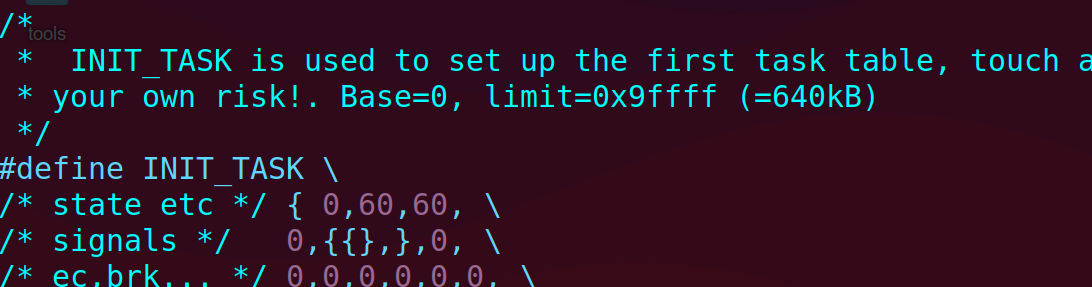
linux0.11中,priority和counter在include/linux/sched.h中定义

我们修改这个值,然后重新执行process程序,分析log。
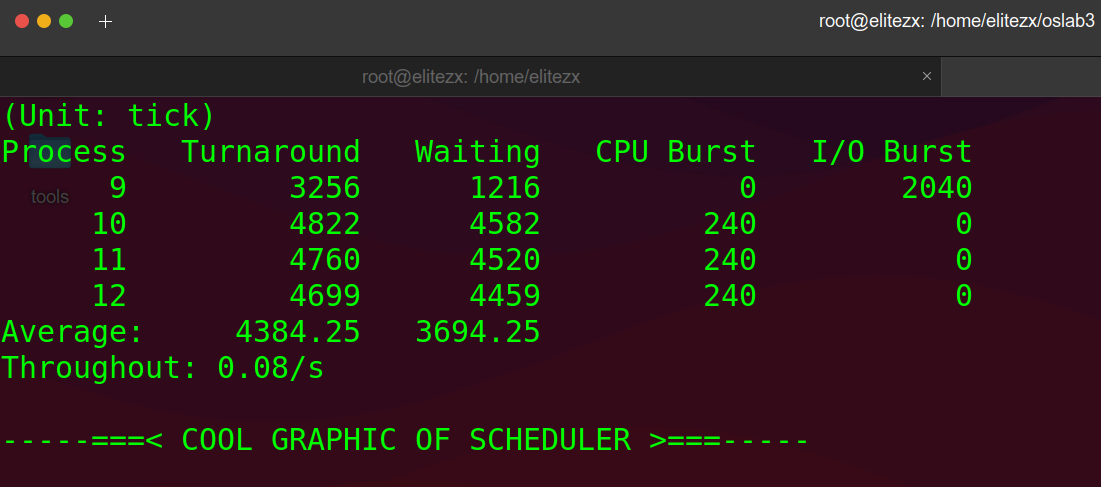
可以看到这里的时间平均周转时间变多了,有以下两种可能:
- 当进程的执行时间很长时,增加时间片大小可能会导致进程在等待时间片结束时的等待时间变长,因为进程需要等待更长的时间才能获得 CPU
- 当进程的数量非常多时,增加时间片大小可能会导致进程在就绪队列中等待的时间变长,因为每个进程需要等待更长的时间才能获得 CPU。
因此,时间片大小的设置需要根据具体情况进行调整,不能简单地认为增加时间片大小一定会减少平均周转时间。需要根据系统中进程的数量、执行时间等因素来选择合适的时间片大小,从而达到更好的系统性能。
实验4 基于内核栈切换的进程切换
我这个实验做的不是很好,建议本实验参考其他的博客
1. 修改schedule函数
在TSS切换中,依赖TR寄存器找到下一个进程的tss,从而实现切换,因此在switch_to中没有next的PCB。要在switch_to函数中,将TSS的切换改为内核栈的切换,首先要在schedule函数中给switch_to函数传入next的PCB。因为这里没有TSS的切换,需要再单独做LDT表的切换。
在函数声明中,参数列表是从左到右依次列出的,而在函数栈帧中,参数是从右到左依次压入的。因此调用switch_to函数后,当前进程的内核中依次压入了LDT(next),pnext和返回地址
因为这里涉及函数调用和栈,所以补充一下%esp和%ebp的知识:
ESP寄存器用于指向当前栈帧的顶部,即栈中当前可用的最高地址。而EBP寄存器则通常用于指向当前函数的栈帧,也称为帧指针。EBP寄存器存储的是当前栈帧的起始位置,也就是栈中当前函数的参数和局部变量存储的位置。在函数执行期间,ESP寄存器的值会随着栈中数据的压入和弹出而不断变化,以保持其始终指向当前栈帧的顶部。而EBP寄存器的值通常不会被修改,以保持其一直指向当前函数的栈帧。这样可以确保函数能够正确地访问和修改栈帧中的参数、局部变量和返回地址等信息,而不会干扰其他函数的栈帧。
在函数调用过程中,处理器会将该函数的参数值和返回地址等信息压入当前函数的栈帧中,并将ESP寄存器的值减少相应的字节数。如果在函数执行期间没有再将其他数据压入栈中,那么ESP寄存器的值将等于EBP寄存器的值,即它们都指向栈帧的底部。需要注意的是,函数栈帧的大小通常是在编译时确定的,因此在函数调用前,编译器就已经为该函数分配了足够的栈空间。如果在函数执行期间需要动态分配更多的栈空间,那么ESP和EBP寄存器的值就会发生变化,以指向新分配的栈空间的位置
因此,ESP指向栈帧的顶部,EBP指向栈帧的起始位置,两者配合使用,能够在函数执行期间正确地访问和修改栈帧中的数据。
旁注:LDT表实现进程间的地址隔离
在x86架构中,进程与LDT(Local Descriptor Table)有密切的关系,LDT可以用来隔离和保护不同进程的地址空间。
LDT是一种描述符表,用于存储局部数据段和局部代码段的信息。与全局描述符表(GDT)不同,LDT表是针对每个进程单独维护的,每个进程都可以有自己的LDT表。LDT表的主要作用是实现地址空间的隔离,以保护、不同进程的内存空间不被其他进程访问或修改。
在x86架构中,进程的地址空间通常被划分为多个段,每个段都有自己的基地址和大小。通过使用LDT表中的描述符,可以将进程的地址空间划分为多个不同的段,并且每个进程都有自己独立的LDT表,这样可以实现不同进程的地址空间之间的隔离和保护。进程中的所有数据段和代码段都必须使用LDT中的描述符进行描述,以便在进程运行时能够正确地访问和修改这些段中的数据。
在Linux 0.11内核中,进程的LDT表存储在进程控制块(PCB)中,每个进程都有自己独立的LDT表。当进程被调度执行时,LDT表的选择子被存储在进程的TSS(Task State Segment)中,用于访问进程的LDT表。通过使用LDT表,可以实现不同进程之间的地址空间隔离和保护,提高系统的安全性和稳定性。
总之,LDT表是实现进程地址空间隔离和保护的重要手段,可以帮助操作系统实现不同进程之间的资源隔离和保护。在x86架构下,LDT表和进程的地址空间划分密切相关,每个进程都有自己独立的LDT表和地址空间划分。
void schedule(void)
{
int i,next,c;
struct task_struct ** p;
struct task_struct *pnext = &init_task.task ; //指向下一个进程的PCB的PCB指针,初始化指向进程0
/* check alarm, wake up any interruptible tasks that have got a signal */
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
if (*p) {
if ((*p)->alarm && (*p)->alarm < jiffies) {
(*p)->signal |= (1<<(SIGALRM-1));
(*p)->alarm = 0;
}
if (((*p)->signal & ~(_BLOCKABLE & (*p)->blocked)) &&
(*p)->state==TASK_INTERRUPTIBLE)
(*p)->state=TASK_RUNNING;
}
/* this is the scheduler proper: */
while (1) {
c = -1;
next = 0;
i = NR_TASKS;
p = &task[NR_TASKS];
while (--i) {
if (!*--p)
continue;
if ((*p)->state == TASK_RUNNING && (*p)->counter > c)
c = (*p)->counter, next = i, pnext = *p;
}
if (c) break;
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
if (*p)
(*p)->counter = ((*p)->counter >> 1) +
(*p)->priority;
}
switch_to(pnext, _LDT(next)); // 传递下一个进程的PCB (切换执行序列)和LDT (切换内存空间)
}2. 修改switch_to函数
switch_to函数是一个宏函数,位于include/linux/sched.h中,我们先注释掉这个原版switch_to,在kernel/system_call.s中编写新的switch_to函数。
ESP0 = 0x04
KERNEL_STACK = 0x0C # kernel_stack变量在task_struct中的偏移量
switch_to:
pushl %ebp # 压入C函数schedule的栈帧
movl %esp,%ebp # 将当前进程的栈顶指针esp拷贝给%ebp,使它指向刚刚压入的esp值
pushl %ecx # 这几个寄存器可能是调用函数schedule中用到的寄存器,因此先保存
pushl %ebx
pushl %eax
movl 8(%ebp),%ebx #取出传入的pnext参数,即下一个进程的PCB指针
cmpl %ebx,current
je 1f # next是否是当前进程,如果是,则向前(Forward)跳转到标号1开始执行,不执行转换
# PCB
movl %ebx,%eax
xchgl %eax,current # exchange value, 切换进程PCB, 此时%eax指向当前进程,current指向下一个进程
# TSS 使用户栈能找到内核栈,借用进程0的tss保存内核栈的esp0信息
movl tss, %ecx # 在kernel/sched.c中定义tss = & init_task.task.tss
addl $4096, %ebx # 让ebx指向页表最高地址处,这里也是内核栈的基址
movl %ebx, ESP0(%ecx) # 修改tss中的esp0(偏移量为4),使它指向内核栈的栈顶位置,此时就是栈基址
# switch kernel_stack 切换的关键
movl %esp, KERNEL_STACK(%eax) # 取出CPU.esp 保存到当前进程的PCB中,task_struct中需要添加kernel_stack变量,并修改INIT_TASK
movl 8(%ebp),%ebx # 重新取出下一个进程的PCB
movl KERNEL_STACK(%ebx), %esp # 将下一个进程的PCB中的内核栈的栈顶信息esp放入CPU中
# switch LDT
movl 12(%ebp), %ecx # 取出传入的 LDT(next)参数
lldt %cx # lldt指令用于将LDT的段选择子加载到LDTR寄存器中,LDTR寄存器是一个16位的寄存器,存储LDT的段选择子,硬件根据LDTR在GDT中查找以获取LDT的地址
movl $0x17,%ecx # 重置 fs寄存器
mov %cx,%fs
cmpl %eax,last_task_used_math
jne 1f
clts
1:
popl %eax # 返回C函数schedule,恢复寄存器(特别是帧指针%ebp)
popl %ebx
popl %ecx
popl %ebp
ret
.align 2
first_return_from_kernel: # 一段包含iret的代码,用于返回用户栈
popl %edx
popl %edi
popl %esi
pop %gs
pop %fs
pop %es
pop %ds
iret

3. 修改copy_process函数
在fork.c的copy_process部分添加以下代码用于设置进程的内核栈, 并注释掉设置tss的部分
/*set up kernel stack */
long * krnstack =(long)(PAGE_SIZE + (long)p);
*(--krnstack) = ss & 0xffff; # 压入SS:SP
*(--krnstack) = esp;
*(--krnstack) = eflags;
*(--krnstack) = cs & 0xffff; # 压入CS:IP
*(--krnstack) = eip;
*(--krnstack) = ds & 0xffff;
*(--krnstack) = es & 0xffff;
*(--krnstack) = fs & 0xffff;
*(--krnstack) = gs & 0xffff;
*(--krnstack) = esi;
*(--krnstack) = edi;
*(--krnstack) = edx;
*(--krnstack) = (long) first_return_from_kernel; // a code segment with iret instruction
*(--krnstack) = ebp;
*(--krnstack) = ecx;
*(--krnstack) = ebx;
*(--krnstack) = 0;
p->kernel_stack = krnstack; # 设置PCB中的内核栈栈顶指针信息为初始化后的栈顶指针实验5 信号量的实现与应用
1. 前提
(1) 系统调用open打开文件
要使用系统调用方式打开文件,可以使用 open 系统调用。该系统调用的原型定义在 <fcntl.h> 头文件中,如下:
#include <fcntl.h>
int open(const char *pathname, int flags, mode_t mode);其中,pathname 参数是要打开的文件名,可以是相对路径或绝对路径,可以包含目录名和文件名;flags 参数是打开文件的选项和标志,比如只读、只写、追加、创建等;mode 参数是创建文件时的权限,仅在创建文件时使用,可以指定文件的读写权限。
常用的打开选项和标志包括:
- O_RDONLY:只读模式打开文件。
- O_WRONLY:只写模式打开文件。
- O_RDWR:读写模式打开文件。
- O_CREAT:如果文件不存在则创建文件。
- O_TRUNC:如果文件已存在则清空文件内容。
- O_APPEND:在文件末尾追加内容。
- O_EXCL:在创建文件时,如果文件已存在则返回错误。
如果成功打开文件,系统调用返回一个非负整数,即文件描述符(file descriptor),用于后续访问文件内容。如果出错,则返回一个负值,表示出错的类型。
对第2个参数flags,可以使用了|运算符将多个选项参数组合在一起。这是因为 open 系统调用的选项参数是一个位掩码,每个选项都有一个对应的位标志,可以使用位运算符组合多个选项。
对第3个参数mode,文件的访问权限是一个八进制数,表示文件的所有者、所属组和其他用户对文件的访问权限。
每个访问权限位的含义如下:
- 读权限:4
- 写权限:2
- 执行权限:1
在使用 open 系统调用创建文件时,可以通过一个八进制数来指定文件的访问权限。通常情况下,可以将三个访问权限位组合在一起,得到一个八进制数,作为 mode 参数传递给 open 系统调用。例如,如果要将文件的访问权限设置为所有用户都有写权限,可以使用以下代码:
int fd = open("file", O_CREAT | O_WRONLY, 0222); // 0开头的数字表示这是一个八进制数(2) 系统调用write写入文件
在 C 语言中,write 函数用于向文件或者文件描述符写入数据,其函数原型为:
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);write 函数的三个参数分别表示:
- fd:文件描述符,它是一个整数,用于指定要写入数据的文件或设备。在 Linux 系统中,标准输入、标准输出和标准错误分别对应文件描述符 0、1 和 2。用户可以使用 open 函数打开其他文件或设备,并获得相应的文件描述符。
- buf:指向要写入数据的缓冲区的指针。在写入数据之前,用户需要将数据存储在缓冲区中,然后将缓冲区的地址传递给 write 函数。
- count:要写入的字节数。用户需要指定要写入数据的长度,以字节数为单位。如果缓冲区中的数据长度小于 count,则 write 函数只会写入部分数据;如果缓冲区中的数据长度大于 count,则 write 函数只会写入 count 字节的数据。
当 write() 函数成功写入数据时,内核会更新文件偏移量,以便下一次读写操作从正确的位置开始。
需要注意的是,write 函数返回值是 ssize_t 类型,表示成功写入的字节数,如果返回值为负数,则表示写入失败。
(3) 系统调用read从文件读取数据
在 Linux 系统中,read() 是一个用于从文件描述符中读取数据的系统调用。该调用的原型如下
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);read() 函数有三个参数:
- fd:要读取的文件的文件描述符。
- buf:用于存储读取数据的缓冲区。
- count:要读取的字节数。
read() 函数会从指定的文件描述符 fd 中读取 count 个字节的数据,并将其存储到 buf 缓冲区中。函数返回实际读取的字节数,如果读取出错,则返回 -1。
read() 函数在读取数据时可能会阻塞进程,直到有数据可读或发生错误。如果读取到文件末尾,函数返回 0。如果读取的字节数小于 count,则可能是因为已经到达文件末尾或者因为发生了错误。
当使用 read() 函数读取数据时,内核会将文件偏移量更新为读取数据后的下一个位置。例如,如果你使用 read() 函数从文件的位置 100 处读取 50 个字节的数据,则文件偏移量会从 100 更新为 150 (100~149)。这样,下一次读取数据操作将从文件位置 150 处开始。使用 lseek() 函数可以显式地设置文件偏移量。
read() 函数可以用于读取文件、套接字、管道等类型的文件描述符。
(4) 系统调用lseek移动文件指针
lseek函数用于在文件中移动文件指针的位置。该函数的原型如下:
#include <unistd.h>
off_t lseek(int fd, off_t offset, int whence); // off_t 是long的别名,在<sys/types.h>中定义其中,fd 是已打开文件的文件描述符,offset 是需要移动的偏移量,whence 则用于指定相对于何处进行偏移,其取值可以为 SEEK_SET、SEEK_CUR 或 SEEK_END。这三个常量在<unistd.h> 头文件中定义

- 当 whence 值为 SEEK_SET时,文件指针将被设置为相对于文件开头偏移 offset 个字节的位置。
- 当 whence 值为 SEEK_CUR时,文件指针将被设置为相对于当前位置偏移 offset 个字节的位置。
- 当 whence 值为 SEEK_END时,文件指针将被设置为相对于文件末尾偏移 offset 个字节的位置。
lseek() 函数返回新的文件指针位置,如果出现错误则返回 -1。通过调用 lseek() 函数可以实现随机访问文件的功能,比如读取文件中的任意部分内容、覆盖文件中的任意部分内容等。
2. 创建semaphore类型
在include/linux/sem.h写入以下内容
#ifndef _SEM
#define _SEM
#include<linux/sched.h> // for task_struct definition
#define SEM_TABLE_LEN 20
#define SEM_NAME_LEN 20
typedef struct semaphore{
int value;
char name[SEM_NAME_LEN];
struct task_struct *queue; // wait queue
}sem_t;
sem_t sem_table[SEM_TABLE_LEN];
#endif
3. 创建信号量相关的系统调用
在kernel/sem.c中写入以下内容,包括信号量的创建sys_sem_open,P操作sys_sem_wait,V操作sys_sem_post,和释放信号量sys_sem_unlink
#include<linux/sem.h>
#include<unistd.h>
#include<linux/tty.h>
#include<linux/kernel.h>
#include<linux/fdreg.h>
#include<asm/system.h>
#include<asm/io.h>
#include<asm/segment.h>
// #include<string.h> // avoid unknowned error
int cnt; // the number of semaphores in sem_table, auto initial to zero
sem_t * sys_sem_open(const char *name, unsigned int value){
int i;
int name_len = 0;
int isExist = 0;
int sem_name_len =0;
char kernel_sem_name[25]={"\0"};
char c;
sem_t * p = NULL;
while( (c = get_fs_byte(name+name_len))!='\0')
{
kernel_sem_name[name_len] = c;
++name_len;
}
// printk("name_len: %d\tstrlen: %d\n",name_len,strlen(kernel_sem_name));
if(name_len > SEM_NAME_LEN) return NULL;
for(i=0; i<cnt; ++i) /*find duplicate*/
{
sem_name_len = strlen(sem_table[i].name);
// printk("%d:%s!\t%d:%s!\n",sem_name_len,sem_table[cnt].name,name_len,kernel_sem_name);
if(sem_name_len == name_len && !strcmp(kernel_sem_name, sem_table[i].name))
{
isExist = 1;
break;
}
}
if(isExist)
{
//printk("i am consumer!\n");
p = sem_table+i;
}
else
{
strcpy(sem_table[cnt].name, kernel_sem_name);
// printk("ID:(%d)\t %d\t%s!\t%d\t%s!\n",cnt,strlen(sem_table[cnt].name),sem_table[cnt].name,strlen(kernel_sem_name),kernel_sem_name);
sem_table[cnt].value = value;
p = sem_table+cnt;
++cnt;
//printk("i am producer!\n");
}
return p;
}
void sys_sem_wait(sem_t *sem)
{
cli();
if(--sem->value < 0 ) sleep_on(&(sem->queue));
sti();
}
void sys_sem_post(sem_t *sem)
{
cli();
if(++sem->value <= 0) wake_up(&(sem->queue));
sti();
}
int sys_sem_unlink(const char *name)
{
int i=0;
int name_len = 0;
while(get_fs_byte(name+name_len)!='\0') {++name_len;}
if(name_len > SEM_NAME_LEN)
return NULL;
char kernel_sem_name[25];
for(i=0; i<name_len; ++i) {kernel_sem_name[i] = get_fs_byte(name+i);}
int isExist = 0;
int sem_name_len =0;
for(i =0; i<cnt; ++i)
{
sem_name_len = strlen(sem_table[i].name);
if(sem_name_len == name_len && !strcmp(kernel_sem_name, sem_table[i].name))
{
isExist = 1;
break;
}
}
if(isExist)
{
int tmp =0;
for(tmp=i;i<cnt;++i)
{
sem_table[tmp] = sem_table[tmp+1]; // overwrite
}
--cnt;
return 0;
}
else
return -1;
}
将sys_function添加到内核的系统调用已在lab2讲解过,这里只上截图
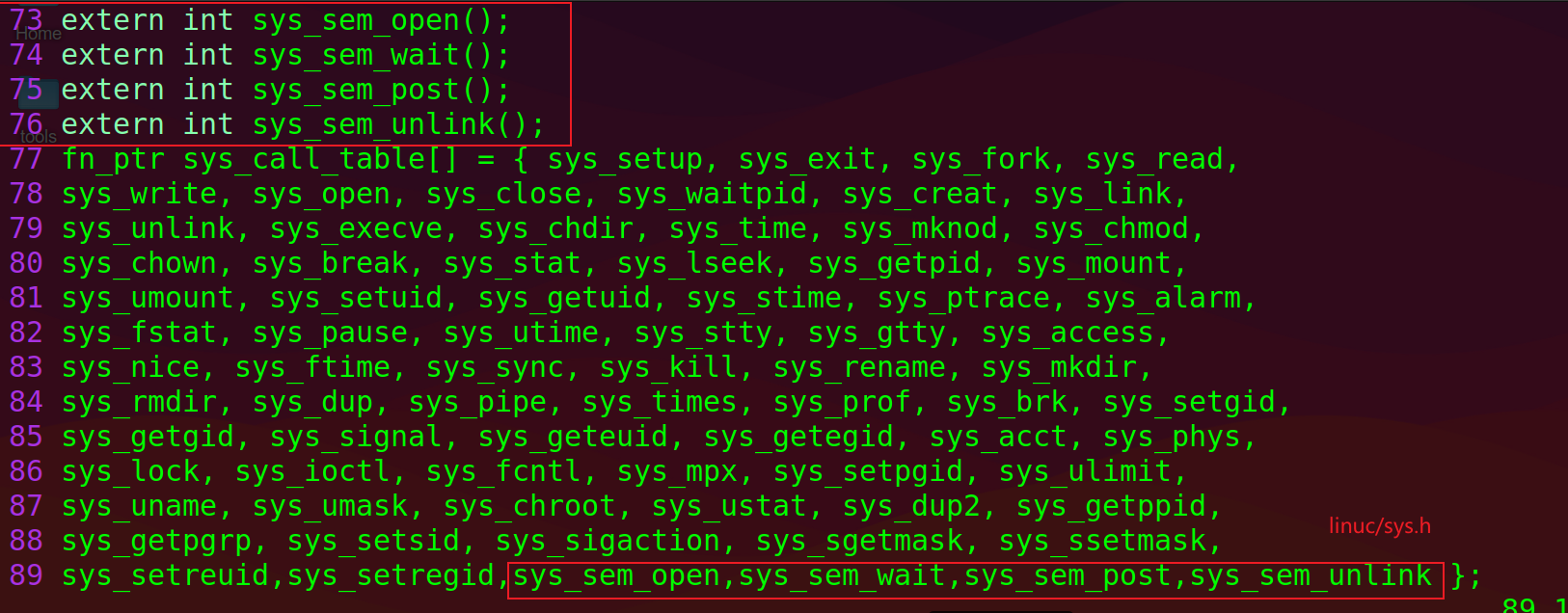
修改Makefile

4. 创建生产者-消费者进程
在pc.c中写入以下内容
#define __LIBRARY__
#include<unistd.h>
#include<linux/sem.h>
#include<stdio.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<linux/sched.h>
_syscall2(sem_t*, sem_open, const char*, name, unsigned int, value)
_syscall1(void, sem_wait, sem_t*, sem)
_syscall1(void, sem_post, sem_t*, sem)
_syscall1(int, sem_unlink, const char*, name)
const int NR_CONSUMER = 5;
const int NR_PRODUCTS = 50;
const int BUFFER_SIZE = 10;
unsigned int pro_nr, csm_pro_nr; /*product number, consumed product number*/
const char* FILENAME = "/usr/root/buffer_file"; /*default buffer file*/
sem_t *mutex, *full, *empty;
int f_in; /* for producer*/
int f_out; /* for consumer*/
int main(int argc, char* argv[])
{
const char * file_name = argc > 1 ? argv[1] : FILENAME;
int pid;
int cnt; /* must declare cnt here */
/*open buffer file */
f_in = open(file_name, O_CREAT|O_TRUNC|O_WRONLY, 0222);
f_out = open(file_name,O_TRUNC|O_RDONLY, 0444);
/*create semaphores*/
mutex = sem_open("MUTEX",1);
full = sem_open("FULL",0);
empty = sem_open("EMPTY",BUFFER_SIZE);
/*parent process as producer*/
pro_nr = 0;
if(fork())
{
pid = getpid();
printf("pid %d:\t producer created!\n",pid);
fflush(stdout);
while(pro_nr < NR_PRODUCTS) /*until product all products then producer exit*/
{
sem_wait(empty);
sem_wait(mutex);
if(!(pro_nr % BUFFER_SIZE)) lseek(f_in, 0, 0); /*10 products per turn*/
write(f_in,(char*)&pro_nr, sizeof(pro_nr));
printf("pid %d:\t produces product %d!\n", pid, pro_nr);
fflush(stdout);
++pro_nr;
sem_post(mutex);
sem_post(full);
}
}
/*child process create child processes to be consumer*/
else
{
cnt = NR_CONSUMER;
while(cnt--)
{
if(!(pid=fork()))
{
pid = getpid();
printf("pid %d:\t consumer %d created!\n", pid, NR_CONSUMER-cnt);
fflush(stdout);
while(1)
{
if(csm_pro_nr == NR_PRODUCTS) goto OK;
sem_wait(full);
sem_wait(mutex);
if(!read(f_out,(char*)&csm_pro_nr, sizeof(csm_pro_nr))) /*end of file,reset*/
{
lseek(f_out, 0, 0);
read(f_out,(char*)&csm_pro_nr, sizeof(csm_pro_nr));
}
printf("pid:%d:\t consumer %d consume product %d\n",pid, NR_CONSUMER-cnt,csm_pro_nr);
fflush(stdout);
sem_post(mutex);
sem_post(empty);
}
}
}
}
OK:
sem_unlink("MUTEX");
sem_unlink("FULL");
sem_unlink("EMPTY");
close(f_in);
close(f_out);
return 0;
}5. 验证结果
#current catalogue: OSLab5
./mount-hdc
#更新标准库
cp include/unistd.h hdc/usr/include
cp include/linux/sem.h hdc/usr/include
#run
cp pc.c hdc/usr/root
./run
#在bochs中执行
gcc -o pc pc.c
./pc > sem_output # 将输出结果重定向到文件sem_output,便于查看
sync #将所有的缓存数据写入磁盘,lab3中出现过
#回到ubuntu执行
./mount-hdc
cp hdc/usr/root/sem_output sem_output
gedit sem_output查看sem_output验证信号量机制的正确性
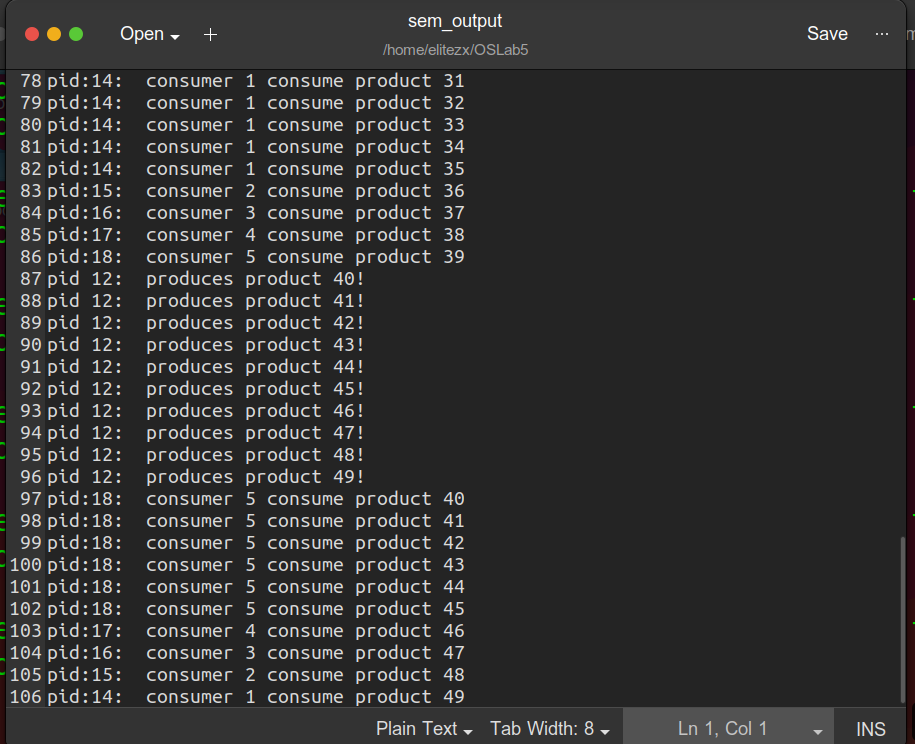
可以看出,producer每生产一轮,即填满容量为10的缓冲区后,5个consumer就开始消耗缓冲区,消耗完后producer又生产一轮,直到达到最大产品数量NR_PRODUCTS = 50(0~49)后退出,consumer在消耗完所有产品后也退出
reference
实验6 地址映射与共享
1. 跟踪地址翻译过程
- 启动调试,获取i的逻辑地址为
ds:0x3004,ds表明该地址属于由ds寄存器指示的段 (后续称ds段)

- 通过段表(LDT),确定ds段的起始地址,进而将逻辑地址转化为虚拟地址。段表由LDTR指示,运行命令
sreg查看LDTR的值,该寄存器用于从GDT中取出进程的LDT地址

LDTR的值为0x68 = 0x0000 0000 0110 1000,取3~15位表示段选择子1101,说明目标LDT在GDT的第13项(从0索引)
GDT的地址已经由gdtr指出为0x00005cb8,因为GDT每项段描述符占8个字节,因此查看GDT的0x00005cb8+8*13处的8个字节,这8个字节就是目标LDT的段描述符
根据段描述符的结构,从0x52d00068 0x000082fd(0~64bits)提取出0x00fd52d0,这就是目标LDT的基地址
ds段的基地址由ds寄存器(段选择子)在LDT中指示,我们先用sreg查看ds的值
段选择子ds的值是0x0017 = 0x 0000 0000 0001 0111 (16bits),根据段选择子的结构
从ds中提取出段选择符的索引0x10,可见ds段在LDT的第3项(从0编号),于是接下来查看目标LDT的前四项(每项占四个字节)
获取了目标LDT中第3个段描述符的数据: 0x00003fff 0x10c0f300,根据段描述符的结构,提取出基地址: 1000 0000,自此我们可以将i逻辑地址转化为虚拟地址(线性地址)了
虚拟地址:
- 将虚拟地址映射到的物理地址
根据虚拟地址结构,可知0x1000 3004 = 0x0001 0000...0000 0011 000..0 0100表示的物理地址在页目录64对应的页表中,页号为3(页号连续,因此由第3个页表项指示),页内偏移为4
内存中页目录表的位置由寄存器CR3指示,使用creg查看CR3寄存器的值

CR3的值为0x00000000,所以页目录表从地址0x00000000开始,我们要获取第64项,页目录表每项占4个字节,因此使用xp /2w 0+64*4查看第64项的内容
得到第64个页目录项的内容为: 0x00fa7027 0x00000000,根据页目录项的结构,前20位表示所指向的页表的地址的高20位 (why)为0x00fa7,因为页表物理地址的低12位为0(对齐到4KB的倍数),因此页表的最终的物理地址为0x00fa7000
一个页表项占4个字节,使用xp /2w 0x00fa7000+4*3查找目标页表的第3个页表项(物理页框)
得到第3个页表项的内容为0x00fa6067 0x00000000
根据页表项的结构,前20项表示物理页框的高20位地址: 0x00fa6 (物理页面大小为4KB,基地址与4KB对齐,为 0x**** **** **** **** **** 0000 0000 0000) ,因此目标物理页框的基地址为0x00fa6000
最后我们加上页内偏移4,得到最终的物理地址0x00fa6004
- 验证
执行xp /w 0x00fa6004查看我们确定的物理地址的数据内容
这个值与i在程序中的值相一致
用命令setpmem 0x00fa6004 4 0将0x00fa6004开始的4个字节(i为int型)全部设置为0,即设置i为0,则程序从原本的无限循环中退出
2. 添加共享内存功能
(1) 前提: 通过brk划分虚拟内存
进程栈和堆之间的内存空间可以映射到共享的物理页面,brk作为指向进程堆的末尾的指针(即下图中处于下方的虚线),将brk加上进程数据段在虚拟内存中的基址,便可以得到brk的虚拟地址,以这个地址为起点,划分出大小为PAGE_SIZE的虚拟内存,再将这部分虚拟内存通过put_page映射到共享内存上

(2) 创建用于管理共享内存的数据结构
linux-0.11/include/linux/shm.h
#ifndef __SHM
#define __SHM
#define SHM_SIZE 32 /*Maximum number of shared pages*/
typedef unsigned int key_t;
typedef struct shm
{
key_t key;
unsigned int size;
unsigned long page; /*shared page address */
}shm;
shm shm_list[SHM_SIZE] ={{0,0,0}};
#endif
(3) 创建共享内存相关的系统调用
linux-0.11/kernel/shm.c
#define __LIBRARY__
#include <unistd.h>
#include <linux/kernel.h>
#include <linux/sched.h> /*for current define*/
#include <linux/shm.h>
#include <linux/mm.h> /* PAGE_SIZE,get_free_page */
#include <errno.h>
/*function: apply for a shared page, return shm_id according to key*/
int sys_shmget(key_t key, size_t size)
{
int i;
void* page;
/*printk("hello, i am here for debug!\n");*/
if(size > PAGE_SIZE) /*size beyond border*/
{
printk("size beyond PAGE_SIZE!\n");
errno = EINVAL;
return -1;
}
for (i=0; i<SHM_SIZE; ++i)
{
if(shm_list[i].key == key) /*constructed before*/
{
printk("constructed before!\n");
return i;
}
}
page = get_free_page();
if(!page) /*no free memory*/
{
printk("no free page!\n");
errno = ENOMEM;
return -1;
}
printk("shmget get memory's address is 0x%08x\n",page);
for(i=0; i<SHM_SIZE; ++i)
{
if (!shm_list[i].key) // record for manage
{
shm_list[i].key = key;
shm_list[i].page = page;
shm_list[i].size = size;
return i;
}
}
return -1; /*shm_list is full and key is invalid*/
}
void* sys_shmat(int shmid)
{
unsigned long data_base;
unsigned long brk;
if(shmid<0 || shmid>=SHM_SIZE || shm_list[shmid].page == 0)
{
errno = EINVAL;
return (void*)-1;
}
data_base = get_base(current->ldt[2]); /*I know get_base from copy_mem() function*/
printk("current data_base = 0x%08x, new page = 0x%08x\n",data_base,shm_list[shmid].page);
/* brk is the end of heap section,
* the virtual memory space between heap and stack can map to shared physical page,
* so slice this part of virtual memory to map the shared page */
/*logic address convert to virtual address by adding base address*/
brk = current->brk+data_base;
current->brk +=PAGE_SIZE;
put_page(shm_list[shmid].page, brk);
return (void*)(current->brk - PAGE_SIZE); /*logic address*/
}
(4) 创建生产者进程
#define __LIBRARY__
#include<unistd.h>
#include<linux/sem.h>
#include<stdio.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<linux/sched.h>
_syscall2(sem_t*, sem_open, const char*, name, unsigned int, value)
_syscall1(void, sem_wait, sem_t*, sem)
_syscall1(void, sem_post, sem_t*, sem)
_syscall1(int, sem_unlink, const char*, name)
_syscall2(int, shmget, unsigned int, key, size_t, size)
_syscall1(void*, shmat, int, shmid)
const int NR_PRODUCTS = 50;
const int BUFFER_SIZE = 10;
const int SHM_KEY = 2023;
int main(int argc, char* argv[])
{
int shm_id;
int* ptr; /*point to the shared memory*/
int i; /* products number */
int buffer_pos = 0;
sem_t *mutex, *full, *empty;
mutex = sem_open("MUTEX",1);
full = sem_open("FULL",0);
empty = sem_open("EMPTY",BUFFER_SIZE);
shm_id = shmget(SHM_KEY,BUFFER_SIZE*sizeof(int));
if (shm_id == -1)
{
printf("shmget failed!\n");
return -1;
}
if((ptr = (int*)shmat(shm_id)) == (void*)-1)
{
printf("shmat failed!\n");
return -1;
}
for(i=0; i<NR_PRODUCTS; ++i)
{
sem_wait(empty);
sem_wait(mutex);
ptr[buffer_pos] = i;
printf("pid %d:\tproducer produces product %d\n", getpid(), i);
fflush(stdout);
sem_post(mutex);
sem_post(full);
buffer_pos = (buffer_pos+1)%BUFFER_SIZE; /*end of the buffer,refresh*/
}
return 0;
}
(5) 创建消费者进程
#define __LIBRARY__
#include<unistd.h>
#include<linux/sem.h>
#include<stdio.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<linux/sched.h>
_syscall2(sem_t*, sem_open, const char*, name, unsigned int, value)
_syscall1(void, sem_wait, sem_t*, sem)
_syscall1(void, sem_post, sem_t*, sem)
_syscall1(int, sem_unlink, const char*, name)
_syscall2(int, shmget, unsigned int, key, size_t, size)
_syscall1(void*, shmat, int, shmid)
const int NR_PRODUCTS = 50;
const int BUFFER_SIZE = 10;
const int SHM_KEY = 2023;
int main(int argc, char* argv[])
{
int shm_id;
int* ptr;
int used_cnt = 0; /*products count*/
int buffer_pos = 0;
sem_t *mutex, *full, *empty;
mutex = sem_open("MUTEX",1);
full = sem_open("FULL",0);
empty = sem_open("EMPTY",BUFFER_SIZE);
shm_id = shmget(SHM_KEY,BUFFER_SIZE*sizeof(int));
if (shm_id == -1)
{
printf("shmget failed!");
return -1;
}
if((ptr = (int*)shmat(shm_id)) == (void*)-1)
{
printf("shmat failed!");
return -1;
}
while(1)
{
sem_wait(full);
sem_wait(mutex);
printf("pid %d consumer consumes products %d\n",getpid(),ptr[buffer_pos]);
fflush(stdout);
sem_post(mutex);
sem_post(empty);
buffer_pos = (buffer_pos+1)%BUFFER_SIZE; /*end of the buffer,refresh*/
if(++used_cnt == NR_PRODUCTS) break;
}
sem_unlink("EMPTY");
sem_unlink("MUTEX");
sem_unlink("FULL");
return 0;
}
(6) 添加到系统调用和修改MakeFile
- 添加到系统调用
如之前的lab一样,验证结果时将unistd.h复制到hdc/usr/include目录下,记得将shm.h也复制到对应目录中

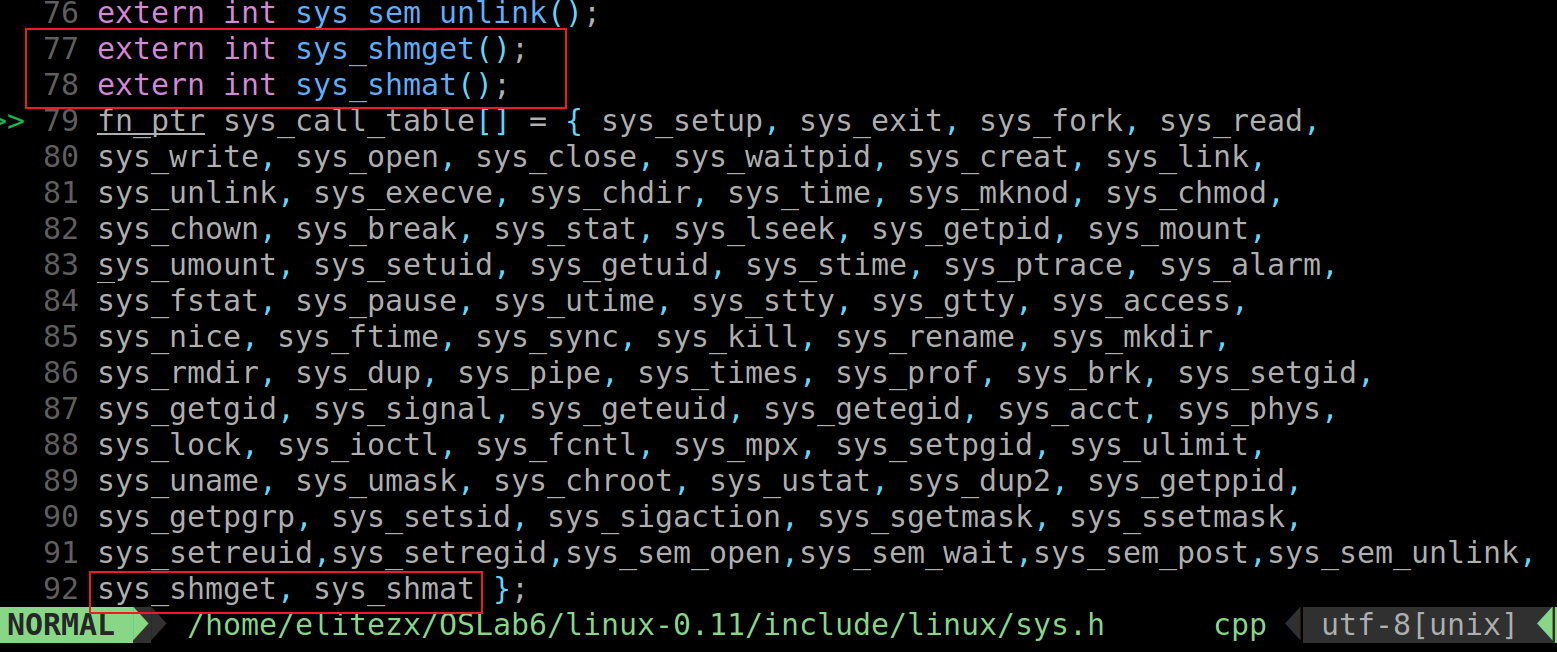
- 修改MakeFile
linux-0.11/kernel/Makefile
(7) 踩的坑
- 编译shm.c时,总是出现
parse error before int的错误,耗时调试了一个小时还是无法解决,Google后发现原因在于linux0.11下的C标准为C89,要求声明变量的语句只能出现在非声明语句的前面 (声明同时又赋值语句的可以) - lab5的sem.c写的有问题,consumer进程一直处于sleep状态,添加了几条打印语句后发现,consumer进程和producer进程未使用同一套信号量,原因在于sem.c的sys_sem_open函数内定义kernel_sem_name未显式的初始化,我以为该变量会默认初始化为0值 (‘\0’),但在c89的标准下,未显式初始化的字符数组不会被默认初始化,这将导致未知的行为,发现这点花了我不少时间。在显式初始化
char kernel_sem_name[25]={"\0"};后结果正确 - consumer进程会出现"kernel panic: trying to free free page",出现这个问题的原因是producer进程和consumer进程共用一个页面,producer生产完全部产品后先退出同时释放共享内存,这将导致consumer进程退出时试图释放已经释放的页面,解决方法是注释掉memery.c文件中free_page函数中的相关panic语句
3. 验证结果
./mount-hdc
cp hdc/usr/root/c_output c_output.txt
cp hdc/usr/root/p_output p_output.txt
实验7 终端设备的控制
1. 添加新的f12响应函数
int switch_by_f12_flag = 0;
void press_f12_handle(void) {
if (switch_by_f12_flag) {
switch_by_f12_flag = 0;
} else {
switch_by_f12_flag = 1;
}
}2. 设置响应函数入口
键盘输入后,操作系统会将键盘扫描码做为下标,调用key_table函数数组中保存的与该按键对应的响应函数,因此要让CPU在按下f12之后跳转到新的响应函数执行需要修改key_table,从该数组一旁的注释就可以看出f12对应的scan code是88D (58H)
3. 修改con_write函数
con_write函数执行最终的输出显示器操作,该函数先用GETCH从输出缓冲区中提取一个字节字符到变量c,再写入显存中。我们根据flag修改变量c的值即可,为了实验结果更可观,我们选择只对字母和数字的输出进行转换
4. 修改tty.h
在头文件中包含switch_by_f12_flag变量和响应函数的声明,以便在其他文件中使用
5. 验证结果
实验8 proc文件系统的实现
前提
vsprintf函数
vsprintf 是一个C库函数,用于将可变参数列表(va_list)中的值格式化为字符串,并将结果字符串存储在指定的字符数组(缓冲区)中。vsprintf 是 sprintf 函数的可变参数版本,通常在需要处理可变数量参数的情况下使用。
vsprintf 函数的原型如下:
int vsprintf(char *str, const char *format, va_list ap);参数说明:
- str:指向目标字符数组(缓冲区)的指针,用于存储格式化后的字符串。
- format:一个格式字符串,它描述了如何将参数列表中的值格式化为字符串。格式字符串可以包含普通字符和转换说明符(例如 %d、%s 等)。
- ap:一个 va_list 类型的参数列表,用于存储需要格式化的值。
返回值:vsprintf 函数返回写入目标字符数组(不包括最后的空字符)的字符数。如果发生错误,返回负值。
因为该函数接受一个va_list类型的参数而不是一个通常使用的可变参数,因此我们要使用va_start函数获取一个va_list的参数
va_start 是C语言标准库中的一个宏,用于处理可变参数列表。va_start 用于在可变参数函数中初始化一个 va_list 类型的变量,使其指向传入的第一个可变参数。通常与 va_arg 和 va_end 宏一起使用,分别用于访问可变参数列表中的参数和完成参数列表的处理 (va_end释放为 va_list 类型的变量分配的资源)。
va_start 宏的原型如下:
void va_start(va_list ap, last_arg);- ap:一个 va_list 类型的变量,用于存储指向可变参数列表的状态。
- last_arg:函数参数列表中最后一个固定参数的名称 (可变参数在固定参数之后)。在初始化 va_list 时,va_start 会找到此固定参数在内存中的位置,从而确定可变参数列表的起始位置。
mknod系统调用
mknod 系统调用用于创建特殊文件(设备文件)在文件系统中。特殊文件通常用于表示设备,如字符设备和块设备。字符设备通常用于表示可逐字符读写的设备,如终端设备;块设备通常用于表示可按块读写的设备,如磁盘设备。本实验用它来创建proc文件。
mknod 系统调用的主要参数包括:
- 路径名(pathname):要创建的特殊文件的路径名。
- 文件模式(mode):描述新创建的特殊文件类型和权限的位掩码。文件类型可以是字符设备(S_IFCHR)或块设备(S_IFBLK)。
- 设备号(dev):设备号用于唯一标识设备。通常分为主设备号和次设备号。主设备号用于标识设备类型或驱动程序,而次设备号用于标识同一类型设备的实例。
当调用 mknod 系统调用时,操作系统会执行以下操作:
- 根据提供的路径名找到目标目录。
- 在目标目录中创建一个新的目录项,设置其文件名和 inode 号(更新目录树)。
- 分配一个新的 inode,并将其与目录项关联。
- 设置 inode 的属性,如文件类型(字符设备或块设备)、权限和设备号等。
- 更新文件系统元数据,如目录和 inode 的更改时间等。
创建特殊文件后,应用程序可以使用设备文件与相应的设备进行通信。例如,通过 open、read、write 和 ioctl 系统调用与设备驱动程序进行交互。这使得设备操作看起来与普通文件操作相似,简化了应用程序的开发。
添加proc类型文件
OS根据文件类型选择不同处理函数,从而实现对不同类型的文件的操作,我们先在linux0.11中添加proc类型文件,之后再编写对应的处理函数就能完成proc文件系统的添加了。
修改mknod系统调用
我们已经提到,mknod用于创建特殊文件,即块设备文件和字符流文件。现在我们要给它添加对proc文件的支持。
创建proc目录文件,proc普通文件
在系统初始化时,根目录文件挂载之后 (这样传递给mknod的路径才有效),创建proc文件系统的目录文件和文件。
因为此时在用户态,因此要通过添加系统调用的方式使用mkdir和mknod,而不能直接使用sys_mkdir和sys_mknod
验证文件是否创建成功
可以看到,我们已经成功在根目录下创建了proc目录文件,并在该文件下创建了proc普通文件,这三个文件分别表示系统进程信息,系统硬件信息,系统存储信息
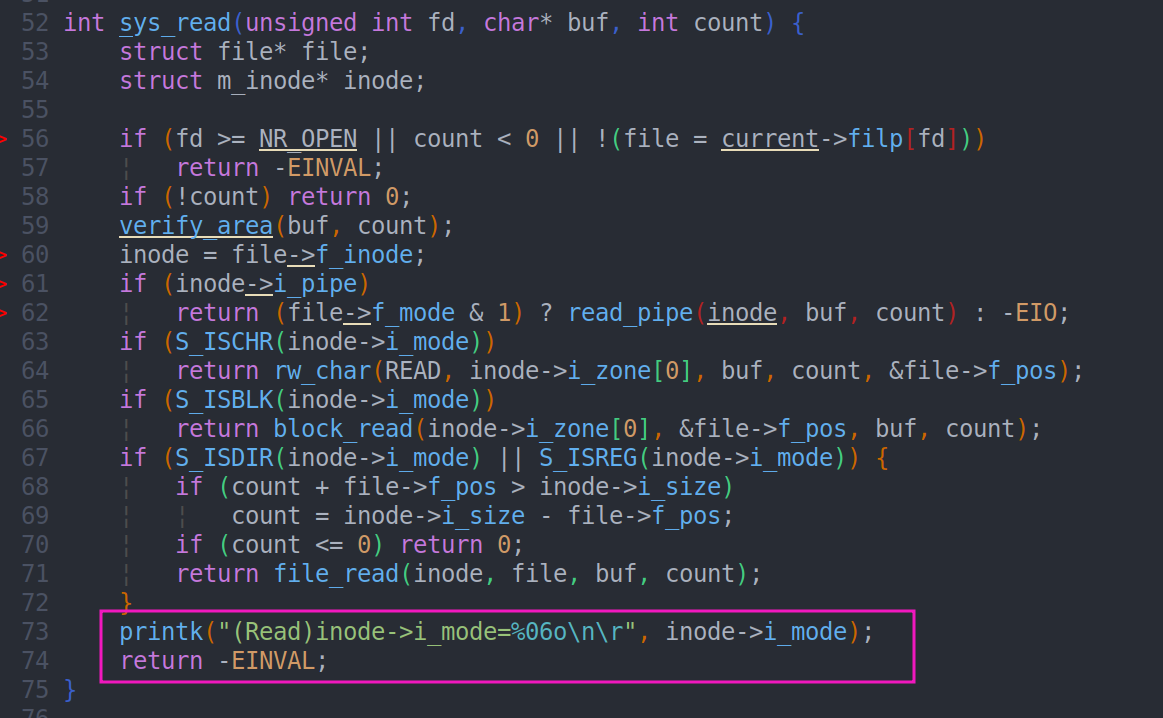
这里使用cat输出了一行信息和一行报错,要明白这两条信息怎么来的,首先要知道cat命令背后执行了什么操作: 用sys_open打开一个文件,用sys_read将文件内容读入缓冲区,最后用printf打印缓冲区的内容到屏幕上
通过查看sys_read的源码,我们可以找到这两条信息的来源。当sys_read打开proc类型文件没有对应的处理函数时,就会出现这两条信息,因此我们接下来为proc类型文件编写对应的处理函数proc_read即可
为proc文件添加处理分支
编写proc文件处理函数
添加linux-0.11/fs/proc_read.c,这里只完成了进程信息的获取
#include <asm/segment.h> // put_fs_byte
#include <linux/fs.h>
#include <linux/kernel.h>
#include <linux/sched.h> // process-related variables: task struct, FIRST_TASK
#include <stdarg.h> // vs_start va_end
#include <unistd.h>
char krnbuf[1024] = {'\0'};
extern int vsprintf(char *buf, const char *fmt, va_list args);
int sprintf(char *buf, const char *fmt, ...) {
va_list args;
int i;
// initalize args to first changeable parameter
va_start(args, fmt);
// vsprintf function returns the number of characters written to the buffer
i = vsprintf(buf, fmt, args);
va_end(args);
return i;
}
int get_psinfo() {
int buf_offset = 0;
buf_offset += sprintf(krnbuf + buf_offset, "%s",
"pid\tstate\tfather\tcounter\tstart_time\n");
struct task_struct **p;
for (p = &LAST_TASK; p >= &FIRST_TASK; --p) {
if (*p != NULL) {
buf_offset += sprintf(krnbuf + buf_offset, "%d\t", (*p)->pid);
buf_offset += sprintf(krnbuf + buf_offset, "%d\t", (*p)->state);
buf_offset += sprintf(krnbuf + buf_offset, "%d\t", (*p)->father);
buf_offset += sprintf(krnbuf + buf_offset, "%d\t", (*p)->counter);
buf_offset +=
sprintf(krnbuf + buf_offset, "%d\n", (*p)->start_time);
}
}
return buf_offset;
}
int proc_read(int dev, off_t *pos, char *buf, int count) {
int i;
if (*pos / BLOCK_SIZE == 0) // already read a whole block, start write
{
get_psinfo();
}
for (i = 0; i < count; ++i) {
if (krnbuf[*pos + i] == '\0') break; // end of message
put_fs_byte(krnbuf[*pos + i],
buf + i + *pos); // synchronous replication
}
*pos += i; // change f_pos
return i; // return the actual number of bytes read
}修改Makefile
验证结果