操作系统真象还原: 从0开始自制操作系统 全过程记录
获取源码:Tiny-OS
1. 部署工作环境,安装并配置bochs
我的系统为ubuntu22.04
1.1. 安装bochs
- 在这里下载好bochs的源码包,我使用的版本是boch-2.7
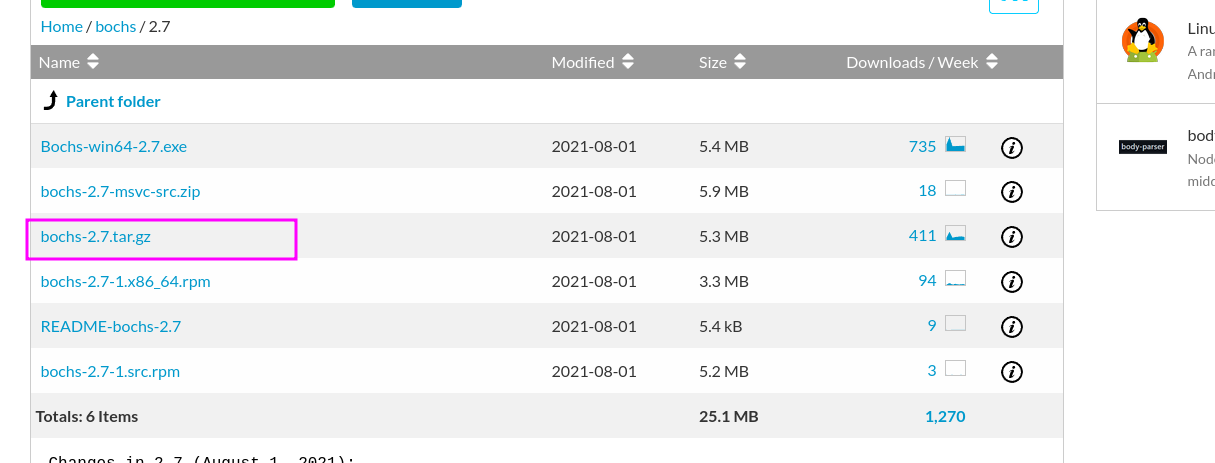
- 构建安装
./configure \
--prefix=/home/elite-zx/bochs \
--enable-debugger \
--enable-disasm \
--enable-iodebug \ --enable-x86-debugger \
--with-x \
--with-x11
make -j $(nproc) && make install安装汇编器NASM
sudo apt update && sudo apt -y install nasm1.2. 配置bochs
根据书在bochsrc.disk中写入以下内容
# bochs configuration file
# bochsrc.disk
# memory size: 32MB
megs: 32
# BIOS and VGA BIOS
romimage: file=/path/to/bochs/share/bochs/BIOS-bochs-latest
vgaromimage: file=/path/to/bochs/share/bochs/VGABIOS-lgpl-latest
# boot from hard disk (rather than floppy disk)
boot: disk
# log file
log: bochs.out
# disable mouse, enable keyboard
mouse: enabled=0
keyboard_mapping: enable=1,
map=/path/to/bochs/share/bochs/keymaps/x11-pc-us.map
# hard disk setting
ata0: enabled=1, ioaddr1=0x1f0, ioaddr2=0x3f0, irq=14
# gdb part setting
#gdbstub: enabled=1, port=1234, text_base=0, data_base=0, bss_base=0
然后运行(为了方便,我把/bin/bochs这个路径加入了环境变量PATH中)
/bin/bochs -f bochsrc.disk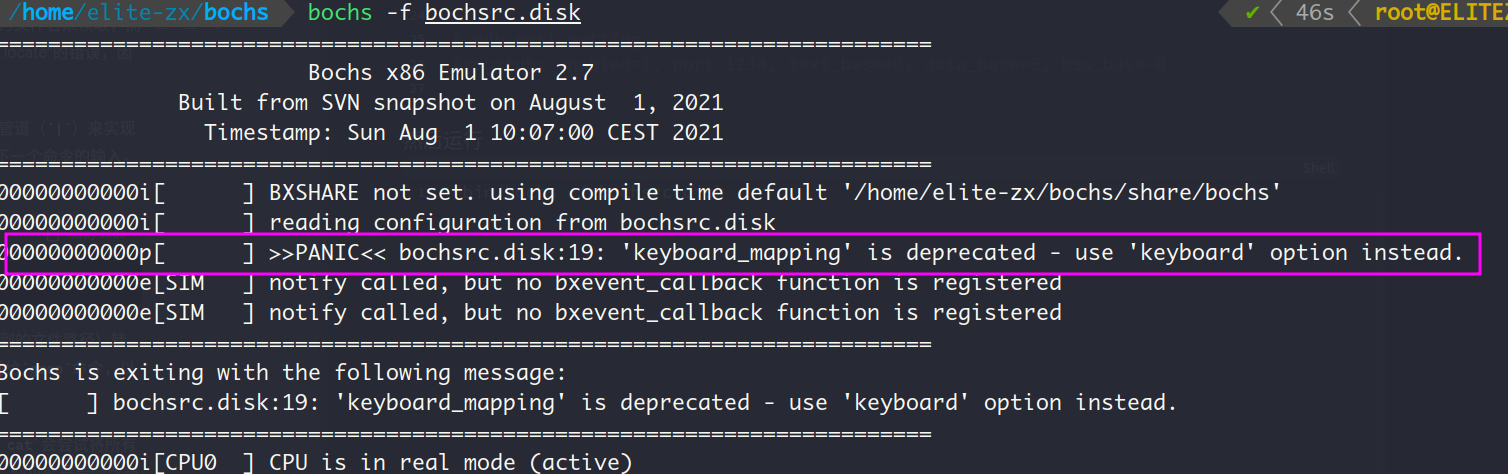
以上输出说明keyboard_mapping的写法已经被淘汰了,于是换成keyboard后再次运行上述命令
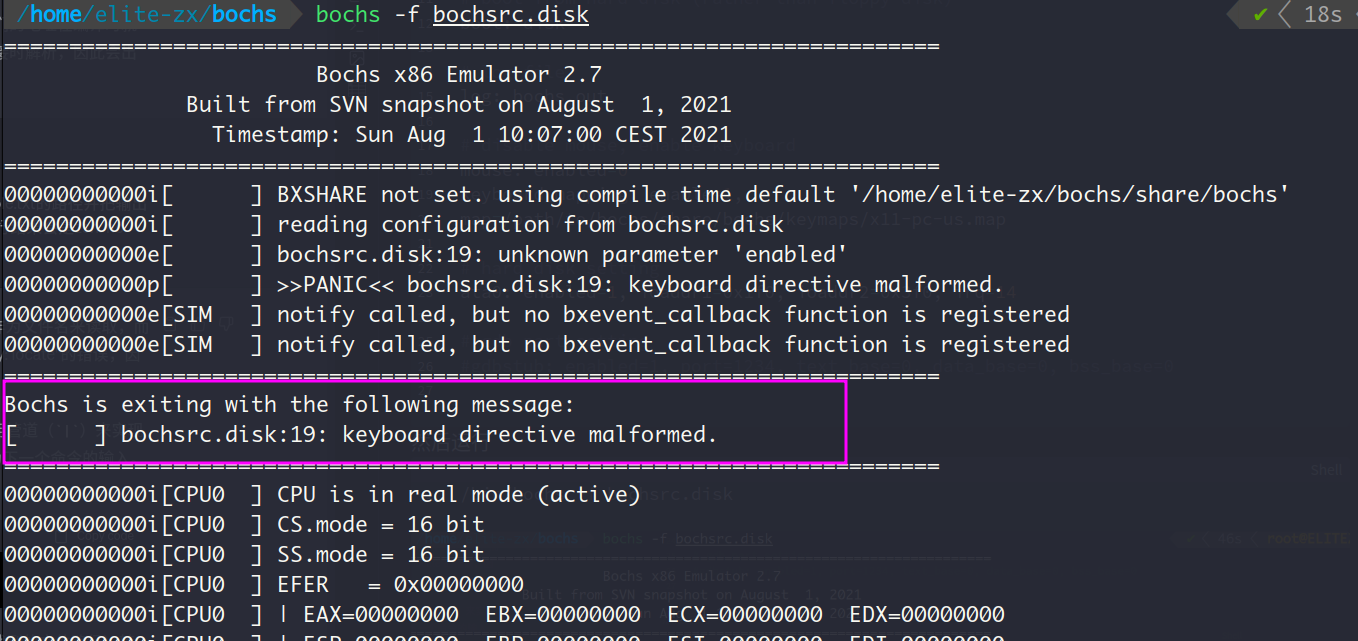
这说明我们有关键盘配置的格式出现了问题,书上的配置已经有些过时了。样本文件中有关keyboard的内容如下,我们以此为依据做修改:
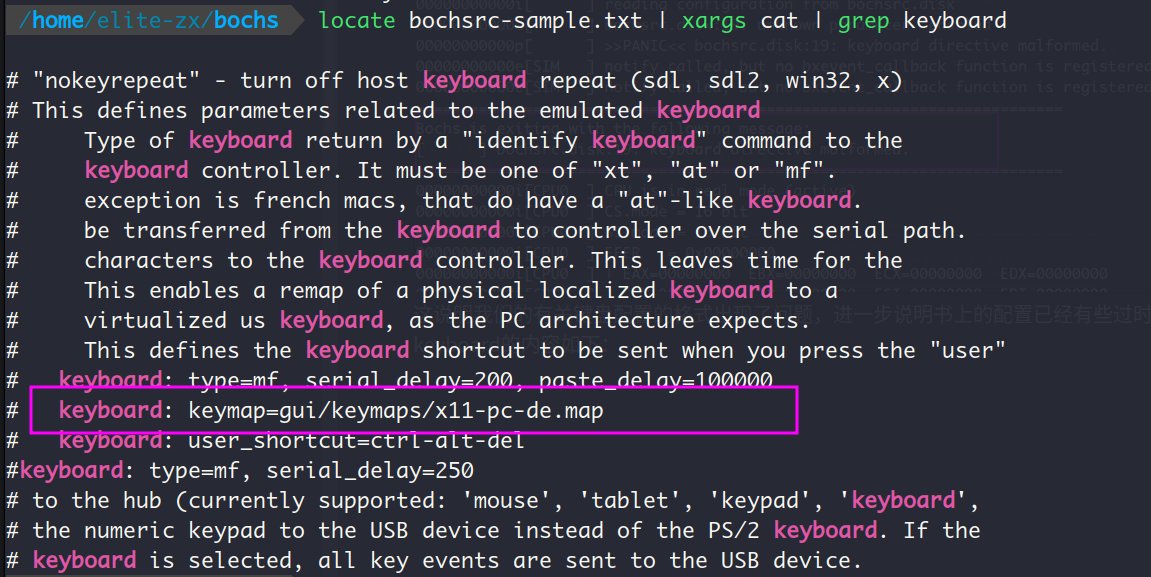
我们将修改后的以下内容写入bochsrc.disk即可
# bochs configuration file
# bochsrc.disk
# memory size: 32MB
megs: 32
# BIOS and VGA BIOS
romimage: file=/home/elite-zx/bochs/share/bochs/BIOS-bochs-latest
vgaromimage: file=/home/elite-zx/bochs/share/bochs/VGABIOS-lgpl-latest
# boot from hard disk (rather than floppy disk)
boot: disk
# log file
log: bochs.out
# disable mouse, enable keyboard
mouse: enabled=0
keyboard:keymap=/home/elite-zx/bochs/share/bochs/keymaps/x11-pc-us.map
# hard disk setting
ata0: enabled=1, ioaddr1=0x1f0, ioaddr2=0x3f0, irq=14
# gdb part setting
#gdbstub: enabled=1, port=1234, text_base=0, data_base=0, bss_base=0最后启动bochs,提示我们缺少启动盘(could not read the boot disk),所以接下来的任务就是创建启动盘(同时在bochs配置文件中指定磁盘映象文件)

工具链配置 (这段内容只面向vim-er):
这部分是我写到第8章的位图的时候补充的,我发现随着文件越来越多,clangd的静态分析总是会出现找不到头文件的错误。解决办法是利用bear工具从makefile文件中提取出编译信息,生成compile_commands.json文件,clangd可以从这个文件中提取出头文件路径 (来源:Other build systems, using Bear)
make clean && bear -- make2. 主引导记录MBR
当计算机加电后,CPU的CS:IP寄存器被强制初始化为, 这是为了让CPU先执行BIOS程序,该程序检测并初始化硬件(通过硬件自己提供的初始化功能调用)。在这个过程中,CPU确实处于实模式(Real Mode),这是一种兼容早期8086处理器的运行模式。在实模式下,CPU能直接访问的内存空间是1MB,地址空间从0x00000到0xFFFFF。 这个1MB的内存空间被划分为多个区域 (详见P.53 表2-1),具体如下:
- BIOS ROM: 通常位于地址空间的高端(),共64KB,包括基本输入输出系统(BIOS)代码。BIOS是存储在主板上的固件,负责初始化硬件并提供操作系统与硬件之间的通信接口。
- RAM: 实际的随机存取存储器(RAM)占据了大部分的1MB地址空间。
- 其他固定映射硬件: 有些特定的内存区域可能被映射到其他硬件设备。
为什么计算机一开始要进入实模式呢? 这又是历史遗留问题了,是8086处理器遗传下来的
地址为的内存中存放了一条跳转指令
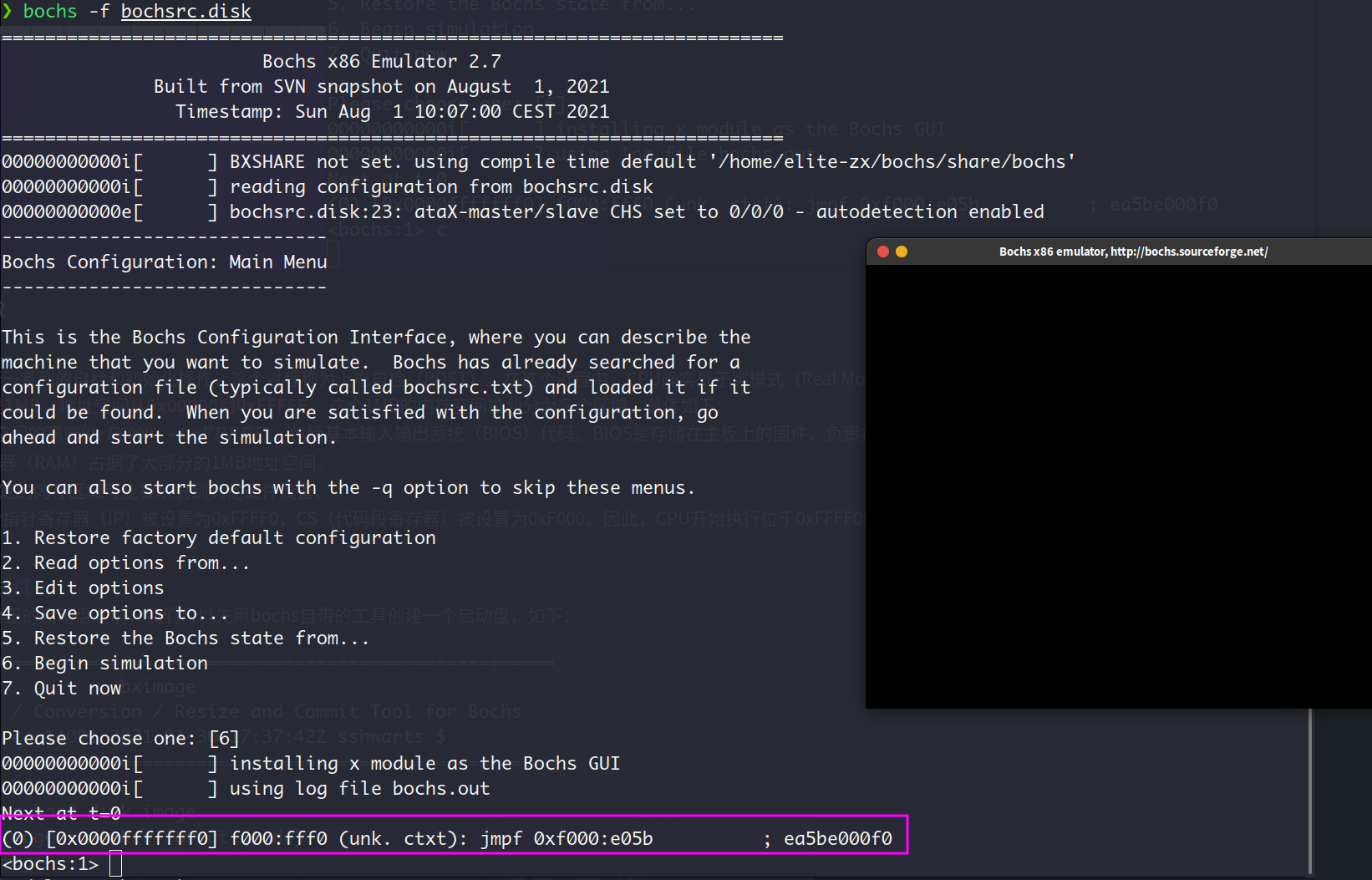
BIOS的主体代码在这个位置:$$0xf000<<4+0xe05b=0xfe05b$$
这才是BIOS真正开始执行的地方
于是CPU开始执行BIOS的代码,完成硬件检测和硬件的初始化,建立中断向量表以便后续可以通过int 中断号来实现相关的硬件调用,最后BIOS检测启动盘的0号盘面0号磁道1号扇面(扇面从1开始编号)的内容,如果此扇区的末尾2个字节是魔数0x55和0xaa,那BIOS就认为此扇区有可执行程序 (即MBR),接着BIOS就会把该扇区的内容加载到物理地址0x7c00处,接着CPU跳转到0x7c00处执行MBR
2.1. 创建一个假的启动盘试试
在编写MBR以创建我们自己真正的启动盘之前,我们可以先用bochs自带的工具创建一个启动盘,如下:
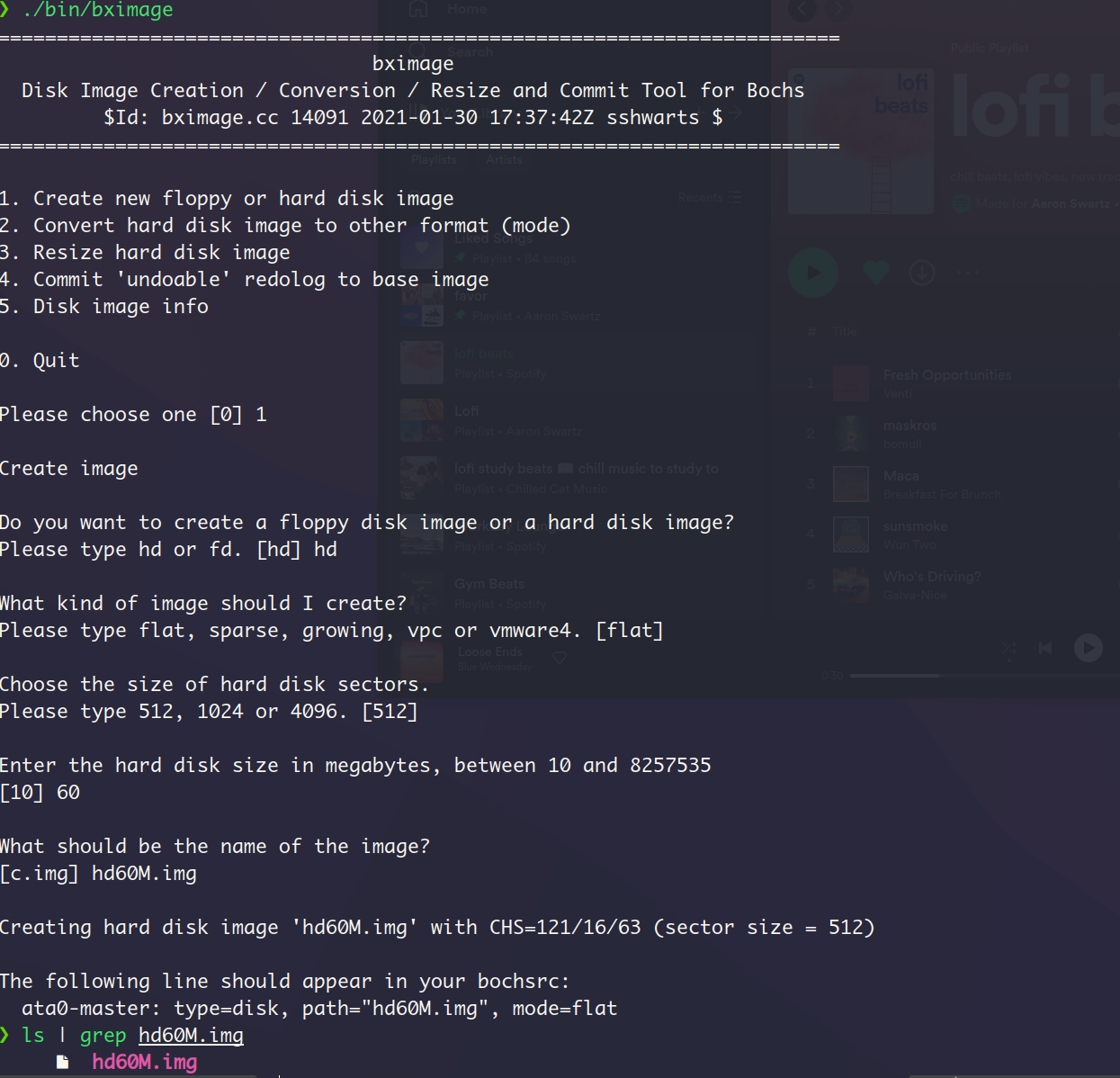
.img 文件通常是一个磁盘映像文件,它包含了一个磁盘驱动器或分区的完整内容,包括文件系统、文件、程序和操作系统。
接着我们把最后的提示信息添加到bochs的配置文件bochsrc.disk中
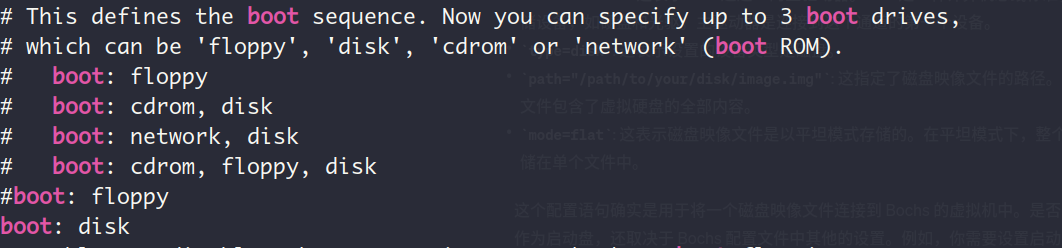
ata0-master: type=disk, path="hd60M.img", mode=flat这个配置语句用于将一个磁盘映像文件连接到 Bochs 的虚拟机中,因为我们在配置文件中设置了 boot: disk,即在启动顺序中只指定了硬盘,因此Bochs将会尝试从这个指定的磁盘映像启动操作系统(即hd60M.img是启动盘),样本文件中关于启动顺序的说明如下:
那么现在的配置文件bochsrc.disk的完整内容是:
# bochs configuration file
# bochsrc.disk
# memory size: 32MB
megs: 32
# BIOS and VGA BIOS
romimage: file=/path/to/bochs/share/bochs/BIOS-bochs-latest
vgaromimage: file=/path/to/bochs/share/bochs/VGABIOS-lgpl-latest
# boot from hard disk (rather than floppy disk)
boot: disk
# log file
log: bochs.out
# disable mouse, enable keyboard
mouse: enabled=0
keyboard:keymap=/path/to/bochs/share/bochs/keymaps/x11-pc-us.map
# hard disk setting
ata0: enabled=1, ioaddr1=0x1f0, ioaddr2=0x3f0, irq=14
ata0-master: type=disk, path="hd60M.img", mode=flat
# gdb part setting
#gdbstub: enabled=1, port=1234, text_base=0, data_base=0, bss_base=0
我们再次启动bochs
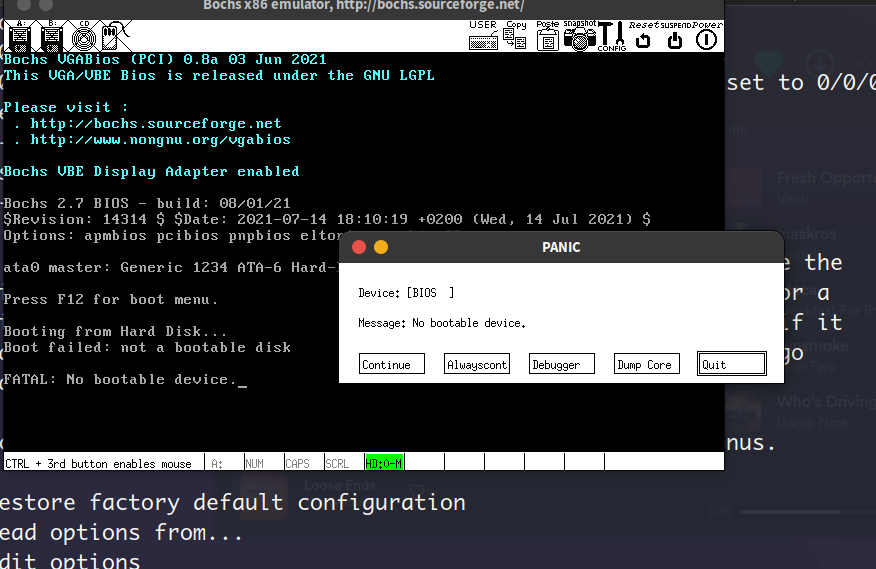
此时提示not a bootable disk的错误,这说明使用bochs创建的盘不是一个真正的启动盘
2.2. 编写MBR创建真正的启动盘
下面我们用汇编语言写一个MBR,并用nasm汇编器生成bin格式(纯二进制)的文件
上面这段代码主要完成了清屏,在光标处打印一个字符串,最后的代码确保了该MBR文件汇编之后(nasm -o mbr.bin mbr.S)是512个字节,最后的2个魔数确保了BIOS会加载这个程序 (56)

因为BIOS最后一个项工作是加载启动盘的0号盘面0号磁道1号扇区(扇区从1开始编号,而非0)中的内容到物理地址0x7c00中,因此我们要把我们的mbr.bin文件加载到该扇区中,通过dd命令:
dd if=/path/to/mbr.bin of=/path/to/bochs/hd60M.img bs=512 count=1 conv=notrunc执行结果如下:

dd 命令会读取 .img 文件中的每个字节,并将其直接写入目标磁盘。这意味着文件系统、引导记录和所有其他数据都会被完整地复制到目标磁盘上。
以上过程,我们先是用汇编语言编写了一个汇编程序,描述MBR要做的事情,接着用nasm汇编器生成了对应的可执行文件,然后用命令dd 将文件mbr.bin的内容写入到磁盘映像文件hd60M.img的第一个扇区(这里没有用dd的seek选项,因此没有跳过任何512字节大小的块,即没有跳过任何扇区,因此写入的是第1个扇区)

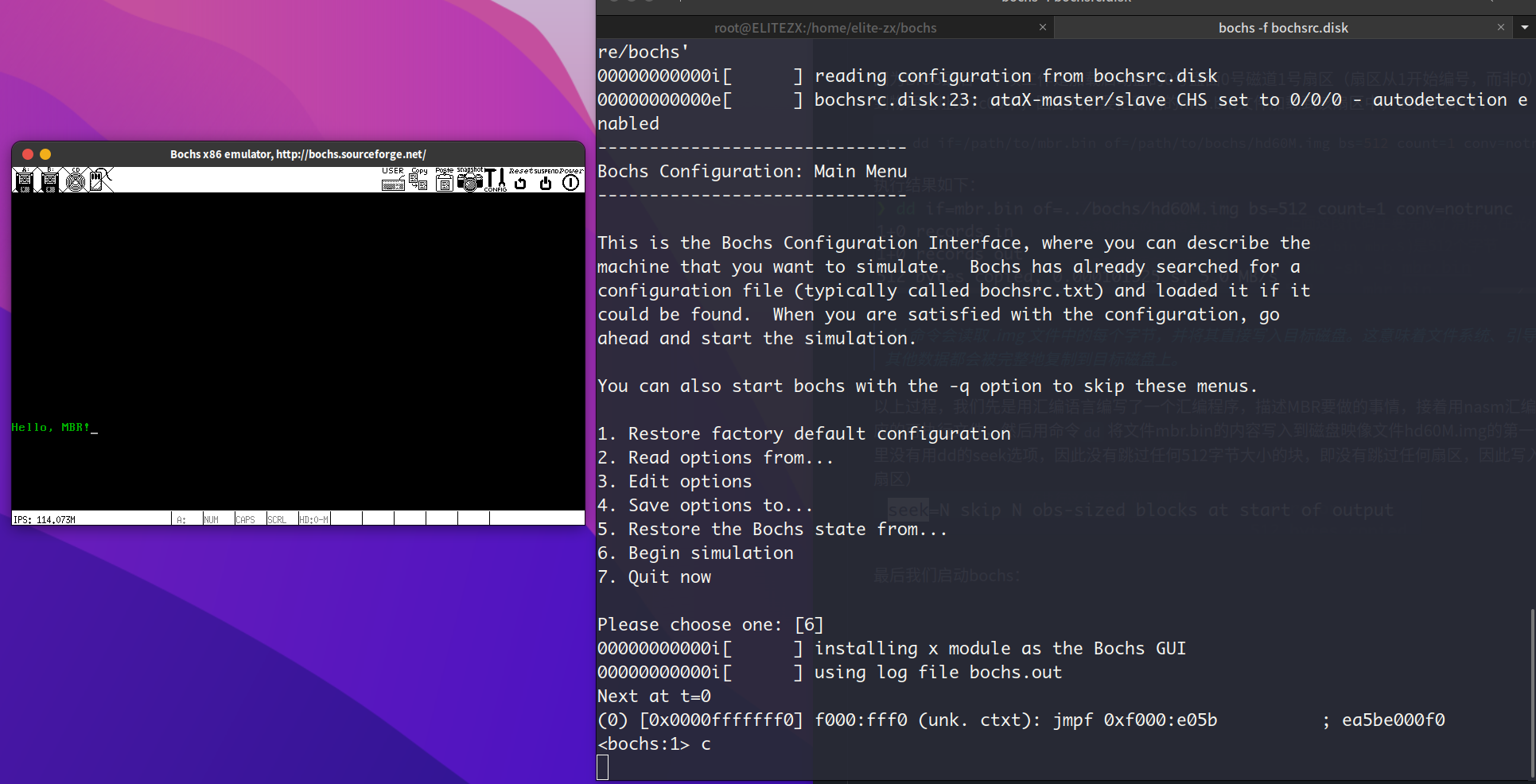
最后我们启动bochs:
MBR被BIOS成功加载并执行
3. 操纵显示器,初探内核加载器
这一节先是花了一些篇幅来讲解汇编的知识,然后描述CPU如何操纵外设。CPU主要通过I/O接口来操纵外设,I/O接口就是CPU与外设之间的中间件。I/O接口通过寄存器(称之为端口)的方式同CPU通信
前一节我们用BIOS的中断调用操纵了显示器的输出,这一节我们通过I/O端口操纵显示器的输出
显卡 (显示适配器) 是显示器的I/O端口,显存是显卡内部的一块内存,显卡就是读取这段内存并把内容发送到显示器上。通过往显存上写入数据,同时遵循ASCII标准,就可以操纵显示器显示我们想要的内容
3.1. MBR V2
先用一个附加段寄存器gs保存显存中用于文本模式的地址以作为段基址,段内每2个字节为一个字符
在bochs上的运行结果:


3.2. 读写硬盘,载入kernel loader
这一节先是介绍了磁盘 (主要指磁盘,另外还有固态硬盘SSD) 的工作原理,再介绍了硬盘对应的I/O接口硬盘控制器中的端口寄存器。我们正是通过读写这些寄存器间接完成CPU与磁盘的交互
计算机加电之后,先执行BIOS,接着BIOS把CPU指挥棒交给了MBR,这是我们之前完成的流程。接下来,MBR要传递CPU指挥棒,传递给谁呢?内核加载器!
那么我们MBR要做的事情,就是把硬盘上的内核加载器读取到实模式的1MB内存的空闲位置中,并跳转到内核加载器去执行
nasm -I include/ -o mbr.bin mbr-v3.S
dd if=mbr.bin of=../../bochs/hd60M.img bs=512 count=1 conv=notruncnasm -I include/ -o loader.bin loader.S
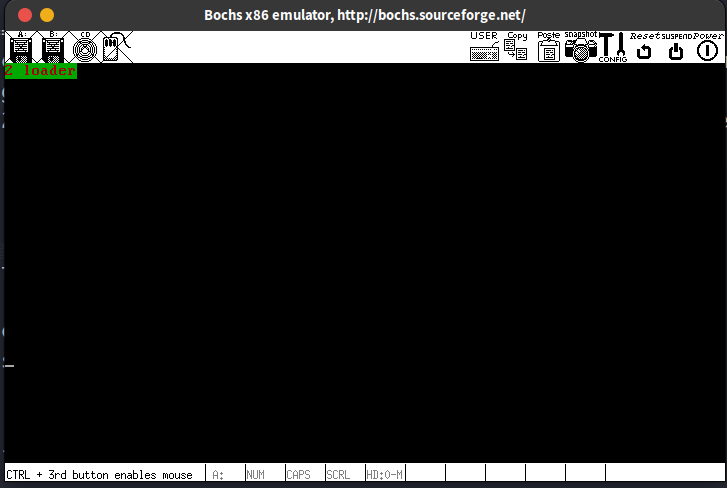
dd if=loader.bin of=../../bochs/hd60M.img bs=512 count=1 seek=2 conv=notrunc # seek=2 means that the file is placed in the 3rd sector of the boot disk这里我们简单的实现了一个内核加载器,它只是简单的向屏幕上打印"2 loader"
4. 从实模式到保护模式
4.1. 由多段模型到平坦模型
这一节主要是修改内核加载器Loader.S的功能,让它能将把CPU从实模式切换为保护模式,要完成这个切换,主要进行以下3个步骤
- 打开A20(157)
- 加载gdt (155)
- 将控制寄存器CR0的pe位置1 (158)
为什么把段基址设为0 :
无论是在实模式还是在保护模式,x86访问内存的机制都是段基址:偏移地址的形式。现在CPU进入保护模式了,寄存器(除段寄存器,现在段寄存器是选择子而非段基址了)和地址总线都拓展到了32位,所以无需设置段基址就可以访问到整块内存(4GB),内存变成了平坦模型(单段),无需再像实模式哪样通过切换段基址来访问整个地址空间,因此我们对段寄存器采取简单的做法:把段基址设为0,所以这里还没有实现对不同段的保护。 而段的长度单位(粒度)我们选择的是4k,所以段界限(limit)为
进入保护模式前为什么有一个jmp指令:
这样做的目的有2个
- 更新段描述符缓冲寄存器的值
- 清空流水线
以上两点在P.172有详细的解释
书上boot.inc部分的代码是有问题的,显卡的段基址的低位不应该是和代码段和数据段一样的0x00,而是应该为0x0b,这样才能和段描述符的低位4字节组成段基址0xb800
此外,因为此时的Loader.bin的大小已经超过一个扇区的512字节:

因此我们要修改之前的MBR-V3.S,让它读取loader起始地址开始的4个扇区(其实2个就足以,不过为了避免将来再过来修改,就多读点咯)
相应的,在用dd命令把loader.bin加载到磁盘映象文件时,count参数要指定为4
dd if=loader.bin of=../../bochs/hd60M.img bs=512 count=4 seek=2 conv=notrunc如果我们的文件大小 (这里是623B) 小于 dd命令指定读取到磁盘映象文件的大小(),那么dd只会复制实际文件大小的数据 (623B)
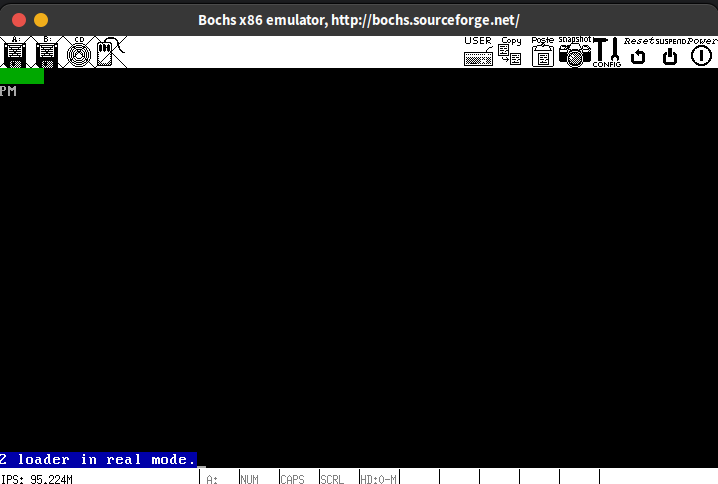
运行结果:
因为loader.S中没有清屏操作了,因此运行结果中保留了MBR模块的字符输出。打印的PM表示现在CPU处于protected mode
现在我们来看看此时的全局符号表GDT:
这与我们在源文件中定义的3个段描述符号一致,此外,bochs调试器获取段描述符条数的方式是读取GDTR寄存器的低位2个字节所表示的GDT界限。这里虽然代码段描述符和数据段描述符对应了同一个段(基址为0, 大小为4GB, 即整个内存空间), 但是当CPU通过不同的段描述符获取该段的信息时,该段就有不同的性质(如代码段 只可执行, 数据段只可读 )
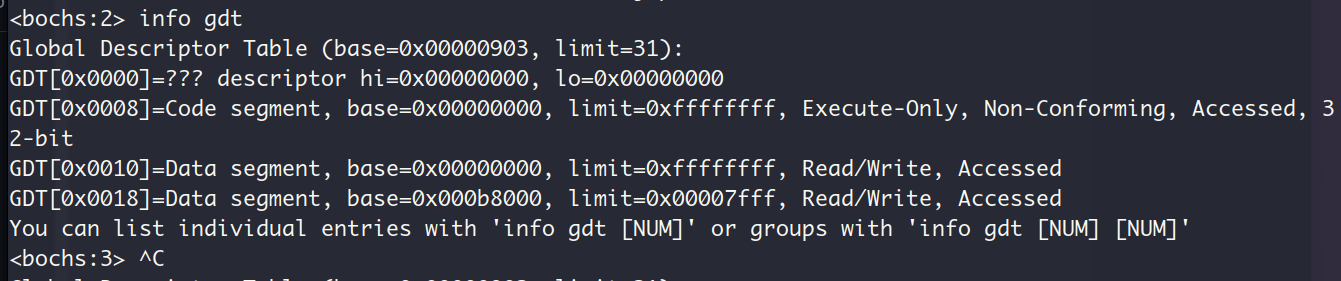
此时的控制寄存器CR0:
PE大写意味着该位已经被置1
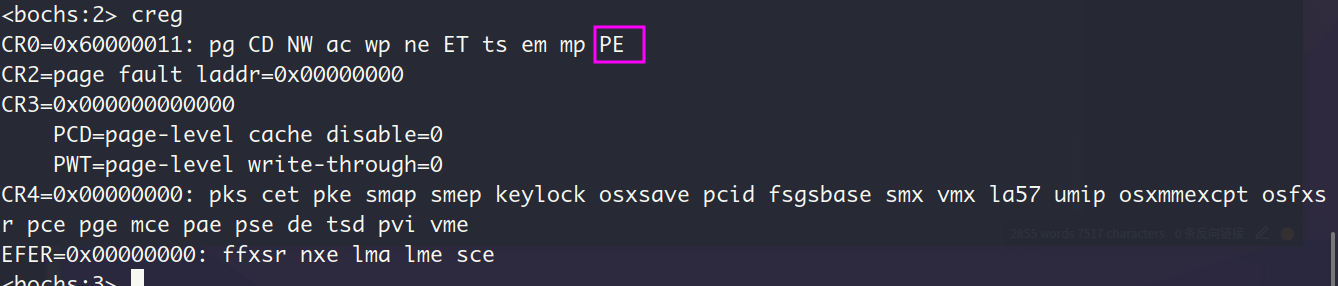
为了进一步验证这是我们的内核加载器loader完成的置位,我们可以在loader的入口地址设置断点,并查看此时的CR0
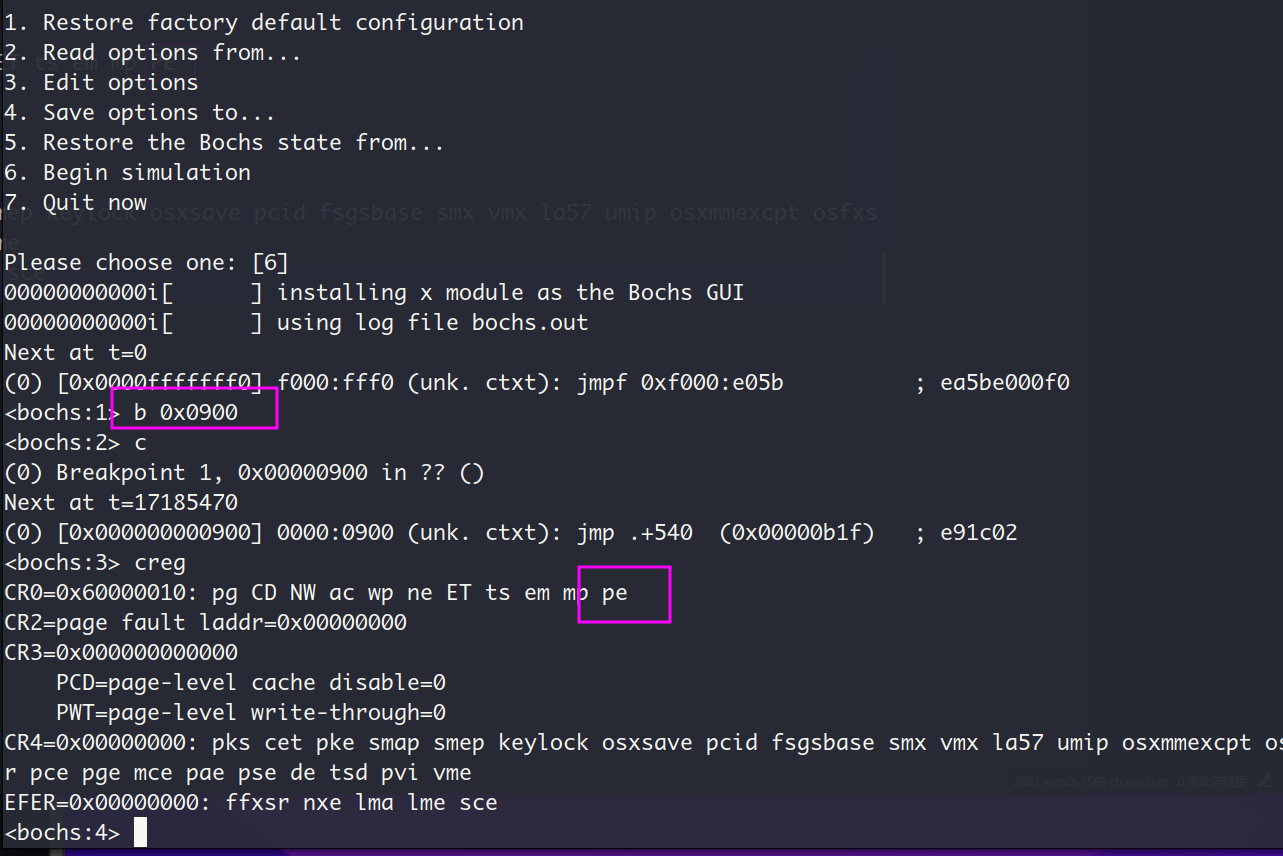
pe小写,说明此时的位pe的值是0,也就意味着此时CPU还是实模式。看样子我们的loader确实正确执行了
4.2. 多次切换从何而来
因为bochs调试器中支持用命令show mode指定bochs在实模式和保护模式之间的切换打印提示信息。出于好奇,我在这一节中使用了这个命令,但是结果出人意料,本该只有一个real mode到protected mode的提示语句,但是实际上却出现了多条:
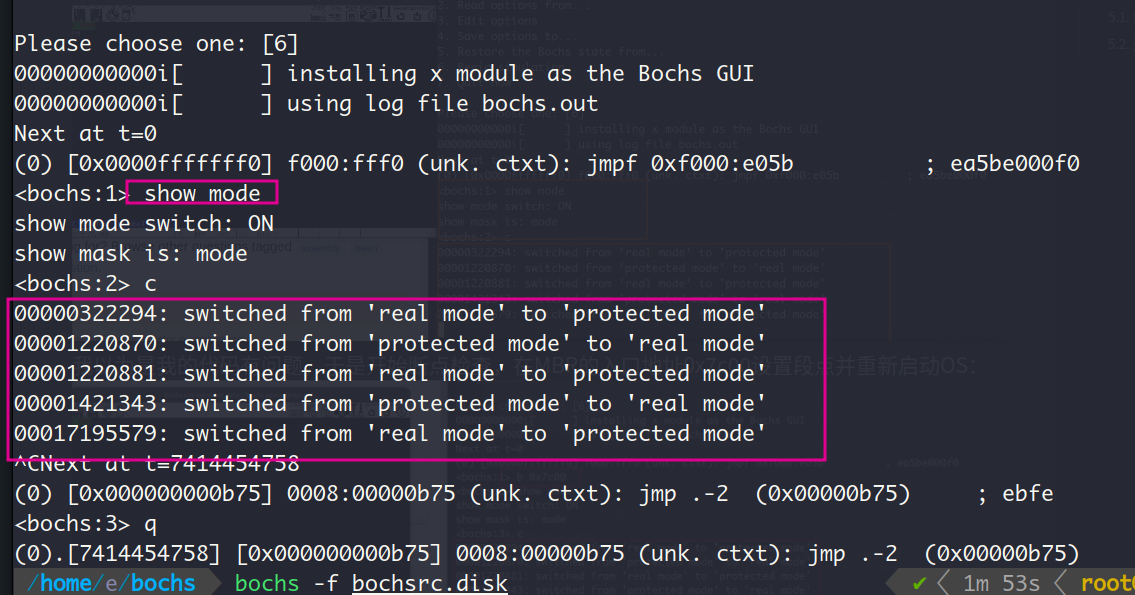
我以为是我的代码有问题,于是开始断点检查,在MBR的入口地址0x7c00设置段点并重新启动OS:
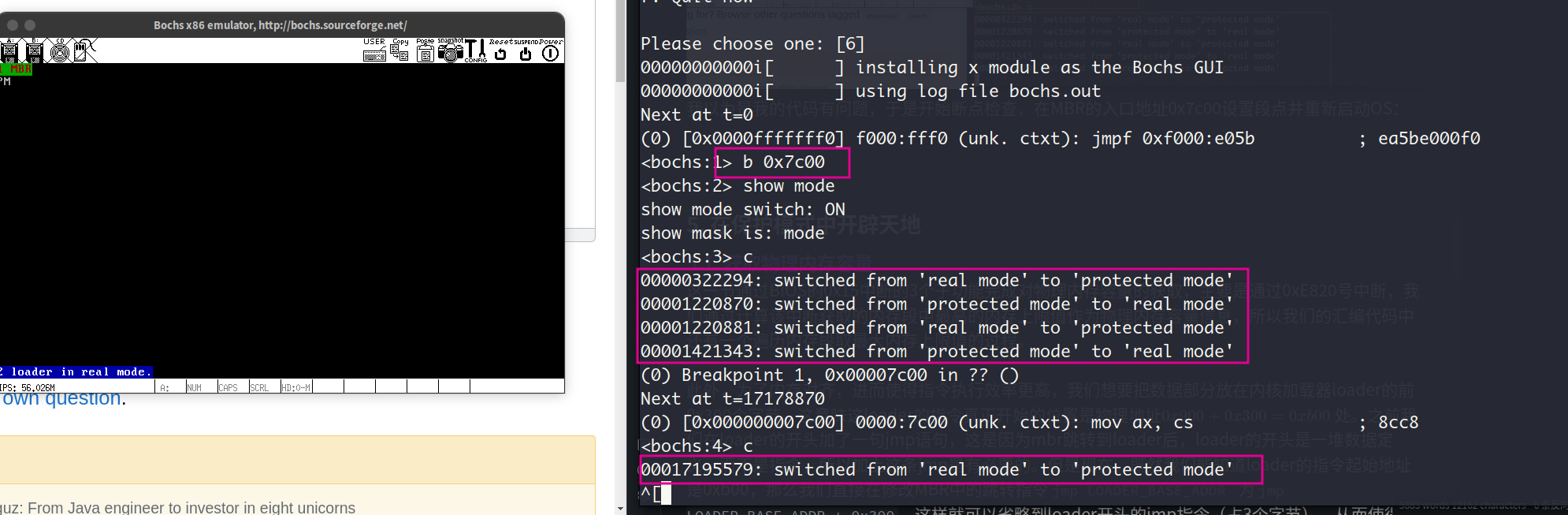
可见除了最后的实模式到保护模式的提示信息是由我的实现造成的以外,之前的提示信息均发生在BIOS执行期间,这可能是BIOS执行硬件检测和初始化导致的。
5. 在保护模式中开辟天地
5.1. 获取物理内存容量
这一节通过BIOS的0x15中断的3个子功能完成对物理内存容量的获取,主要是通过0xE820号中断,我们通过计算该中断获取的内存段中最高的内存上限值作为物理内存容量信息,所以我们的汇编代码中还有一个遍历内存段取最大内存上限值的过程。
此外,为了内存对齐,进而使得指令执行效率更高,我们想要把数据部分放在内核加载器loader的前0x300个字节,这意味这loader的指令真正开始的位置是物理地址 处。之前我们在loader的开头加了一句jmp语句,这是因为mbr跳转到loader后,loader的开头是一堆数据定义,而不是指令,所以加上这条jmp是有必要的。但是现在,既然我们能知道loader的指令起始地址是0xb00,那么我们直接在修改MBR中的跳转指令jmp LOADER_BASE_ADDR 为jmp LOADER_BASE_ADDR + 0x300,这样就可以省略到loader开头的jmp指令(占3个字节),从而使得在它之后定义的数据的地址均对齐到偶数(具体可见P.183)。
这里我其实产生过疑惑,为什么汇编就可以指定数据在指令之前,即我在一堆指令之前用dd,dw指令定义了一堆数据,就可以保证在该程序执行时,数据是在指令之前的。此时就要搬出我们伟大的工具chatgpt来问问了: 这主要是因为汇编语言提供了对计算机硬件的直接控制能力,包括内存地址的直接访问和操作。当你在汇编程序中使用伪指令如 db, dw, dd 等定义数据,它们会按照出现的顺序在生成的机器代码(或对象文件)中占据空间。当你在源代码中书写这些伪指令时,汇编器会按照你的指示将对应的数据字节、字、双字放置在生成的代码中。而类似C语言这样的高级语言,数据(例如全局变量、静态变量和局部变量)和代码(函数)是被编译器和链接器管理的。编译器和链接器会根据操作系统的规范将程序的不同部分放置在不同的内存区域中。
查看物理地址为0xb00的变量total_mem_bytes的值是否为我们bochs配置文件bochs.disk中定义是32MB (0x200 0000):
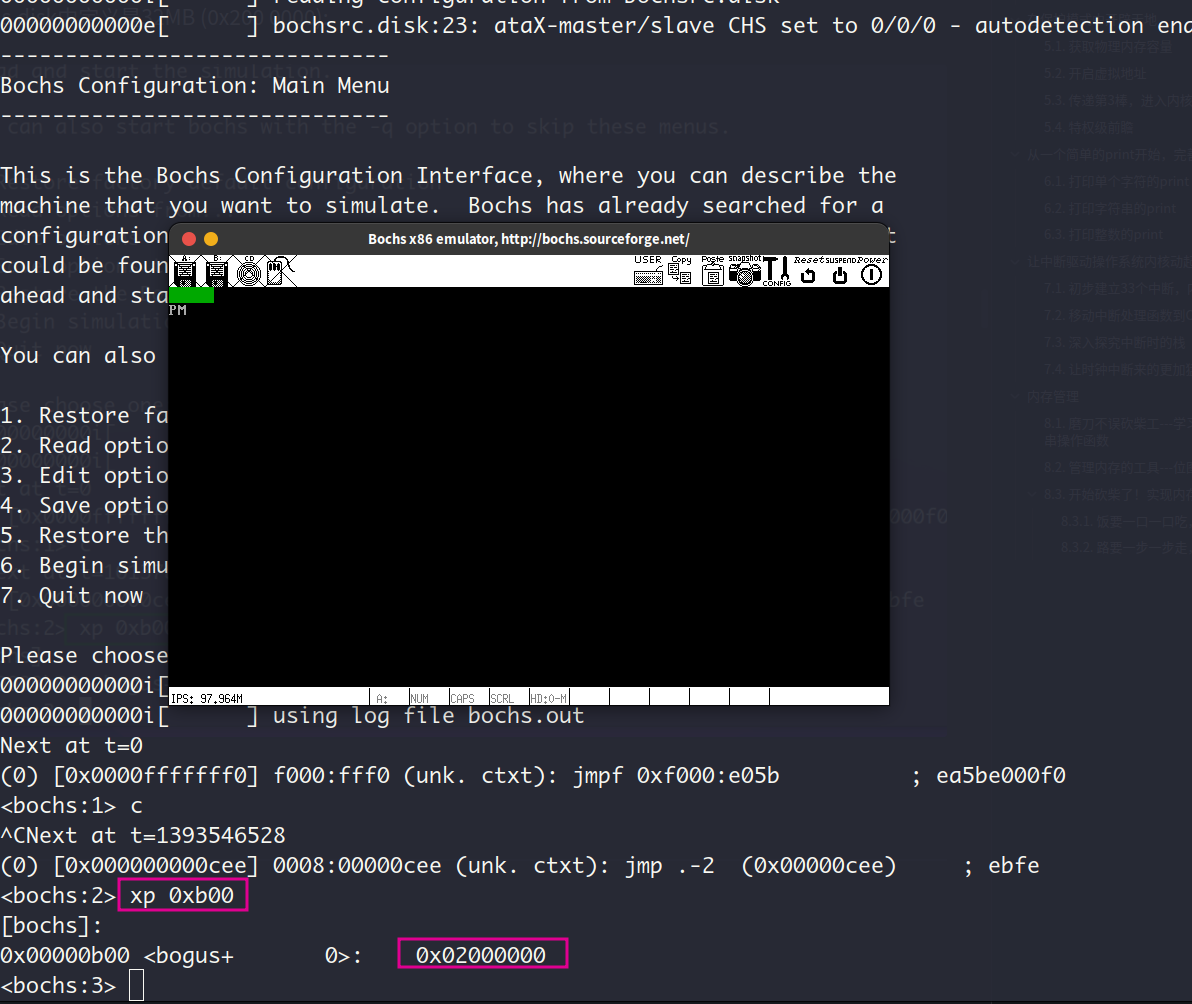
可见检测物理内存容量的结果正确。
5.2. 开启虚拟地址
本节主要通过3个步骤完成了CPU分页机制的启动:
- 准备好分页机制所需要的数据结构—页目录表(PDT)和页表(PT)
- 将页目录地址写入控制寄存器cr,这样CPU的页部件就可以启动页查找
- 把寄存器cr0的PG位置1,这是让CPU进入内存分页运行机制
要了解分页机制,咱们得先把分段机制搞透。分段机制的地址处理由CPU的段部件负责,在分页机制开启之前,段部分输出的线性地址就是物理地址,即线性地址和物理地址是一一对应的关系,就像我们的显存段基址是0xb800,它对应的物理地址就是0xb800。当然了,这里的线性地址,以段基址:段内偏移形式计算出的,但是因为保护模式下寄存器和地址总线都为32位,所以段基址是0。这样一一对应的关系导致内存利用效率低,无法充分利用内存,因为此时线性地址和物理地址都必须是连续的,导致进程必须用一整块物理内存装下。我们想要的是线性地址连续而物理地址不连续,这样就可以用离散的物理内存装载进程。当我们用离散的物理内存装载了进程后,为了让CPU可以正确寻址,就要记录下线性地址和物理地址的映射关系。 此时线性地址和物理地址就不是一一对应的关系了,而是线性地址可以映射到任意一个物理地址。此时的线性地址有了新的名称,叫做虚拟地址
我们要创建页目录表(PDT)和页表(PT)来记录下映射关系。在我们保护模式下,是32位的地址空间,也就是4GB,这也就是说进程可以用的地址空间最大为4GB。在分页机制下,每个进程都有4GB的虚拟内存,但是不具有真正的4GB物理内存,每个进程都有自己的页表。
分页机制下,以4kb为分配单位(即页框/标准页),一个页目录有1KB个页目录项(PDE),一个PDE占4个字节,也就是说一个页目录表的大小是4KB,这正好是一个标准页的大小。页目录项保存着页表的地址,一个页表内含义1KB个页表项(PTE),一个PTE也是4个字节,一个页表页正好是一个标准页4KB的大小。总得算下来,一个填满的页目录和页表所代表的地址为:$$1KB\times1KB\times4KB=32GB$$
这也是32位下的地址空间大小,所以任何一个虚拟地址都可以通过PDT和PT找到对应的物理地址。
其实我不想在这种书上有着详细解释的问题上留下太多额外的描述,上面的内容就当作是我稍微看懂一点之后的足迹吧,不一定准确。
虚拟地址为什么高10位是PDE的索引,中间10位是PTE的索引,最后10位是页内偏移呢?
我认为P.190的地址滑块模型是一个很好说明, 在地址中放一个滑块,滑块左边就是内存块数据,滑块右边就是内存块大小。而且PDT和PT都是含义1KB个项,所以均用10位来确定索引值
创建页目录表时,为什么第768个PDE保存与第1个PDE相同页表地址?
第768个PDE,对应着虚拟地址 3GB (0xc0000001)~3GB+4MB (0xc03fffff),这部分在进程的虚拟地址空间中是OS内核所在的区域(3GB~4GB, 0xc0000000~0xffffffff),而第一个PDE对应的物理地址是物理内存的从0开始的4MB。所以这样做本质上是把进程的高1GB虚拟地址空间中的4MB映射到OS内核所在的物理地址,这样就能实现操作系统在用户进程间的共享(实际上我们的内核大小还不到1MB)。不只是这4MB,我们实际上需要把进程虚拟地址空间中的整个高端1GB都映射到OS内核所在的从0开始的物理地址空间。
如何通过虚拟地址访问到页表本身?
让页目录表的最后一项保存页目录表的起始地址PAGE_DIR_TABLE_POS,详见P.204。这个实现方式十分的巧妙,让我看了连连摇头赞叹,竖起大拇指。简单来说,就是欺骗CPU,让CPU以为它访问到的是页表地址,其实是页目录地址; CPU以为访问的是物理页的物理地址,实际上是页表的物理地址。
为什么要移动GDT到内核空间?为什么要修改视频段的段描述符?
这2者都是因为在分页机制下,内核在虚拟地址空间的高端1GB中,而这2者都属于内核。
GDT是内核空间的东西,而内核空间现在在虚拟地址空间中处于高端1GB,因此要调整之前的GDT地址,把它放入这1GB中。而修改视频段的段描述符中的段基址是因为显存也要在内核中,不能让用户直接控制显存这个硬件,必须通过OS。
在创建页表时,把PDT放在了物理地址0x10000处 (这也是后续填入控制寄存器CR3的值),并将页表紧随其后。因为PDT的大小是4KB,因此第一个页表的地址是 。在页目录项中填入页表的地址,这样页表就创建好了。同样的,在页表项中填入物理页框的地址(不同页框地址相隔4KB,这也是为什么有edx+4096),这样页表项就创建好了
运行结果:
打印V表示OS已经开启分页机制,进程开始使用虚拟(Virtual)地址
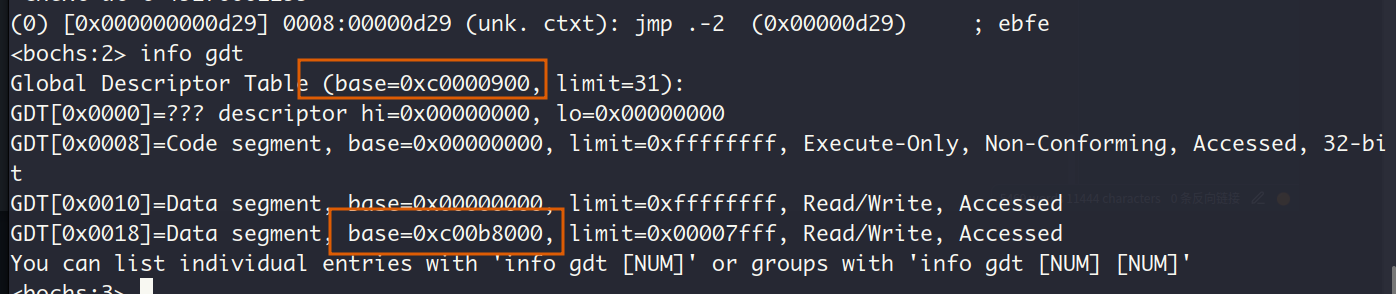
查看GDT起始地址和视频段基址:
查看当前的页表信息:
前2项是PDE第1项和第768项的结果,我们为这2个PDE对应的页表分配了实际的物理内存 (即创建页表项),后3项是为了实现通过虚拟地址访问到页表的结果,书上有着详细的分析 (P.205),我就不多说了
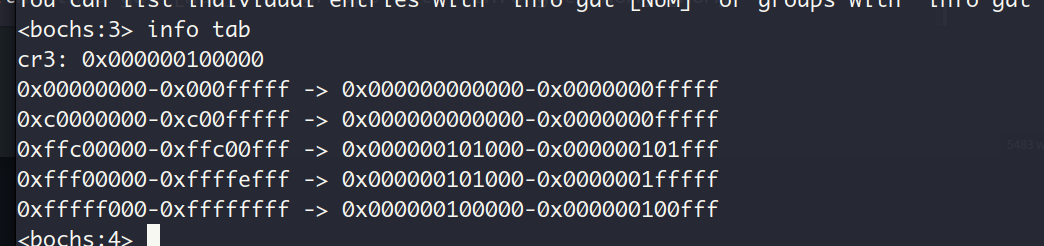
查看cr3的值:
这正是我们放置GDT的物理地址
5.3. 传递第3棒,进入内核
这一节主要在loader.S中完成2件事情:
- 把内核文件kernel.bin(elf格式的二进制可执行文件,同样含有文件头)加载到内存 (elf vs bin, 总的来说就是bin可以直接放入内存执行,而elf需要被解析之后才能执行,我们的第2步就是编写解析elf的程序)
- 根据kernel.bin文件头和segment header table(段头表)中的信息,把kernel.bin中的各个段(segment)拷贝到被编译的目标虚拟地址处(这一坨称为内核映象,即内核的内存映像)
当ELF文件中的segments被加载到内存时,它们形成了程序的内存映像,这个内存映像可以由操作系统或者执行环境来执行
我把内核放在了物理地址的低1MB处,没错,就是BIOS所在的那1MB。这1MB中不仅还有空闲的区域(见P.223图5-43),并且MBR已经完成它的使命了,内核可以覆盖它。所以这1MB中的 可以用来放我的内核(最终的内核大小不会超过1MB)。 在我的实现中,把内核文件kernel.bin放在了0x7000的位置,把内核的内存映像放在了0x1500(即虚拟地址0xc001500, 由链接器ld的-Ttext选项指定,分配虚拟内存地址是链接器的任务。这个物理地址到虚拟地址的转换是我在前一节完成的)的位置。之所以这做,是因为内核的内存映像可能随着执行会变大,需要预留更多的空间,放在低地址处更好。而内核文件kernel.bin是固定的,只需要能放下即可。
关于栈的处理,见P.226图5-44,我们要保证处理内核时用到的栈在内核空间中(即虚拟地址0xc0000000~0xc03fffff,我们在上一节中把物理内存0~4MB映射到了这块虚拟地址,够用)。栈在内存中既然是从高地址向低地址增长的,并且栈底永远不会被访问到(如果对这一点不理解,可见P.226),那么内核的栈最合适的放置位置就应该是内核可用空间的最高地址的下一个地址,即$$0x9fbff+0x1 = 0x9fc00$$
对应到虚拟地址就是$$ 0x9fc00 + 0xc0000000=0xc009fc00$$
但是这里选择了物理地址为0x9f000的地址作为了栈底,这就意味着还有0xc00个字节的位置没用。为什么这么做呢,这里我就不再重复P.228刚哥说的话了,而是提一嘴:P.384讲内存位图基址的时候进一步解释了这个地址的由来,可以结合起来看。归根结底,就是让main线程的PCB占有一个完整的页框
再谈对kernel.bin的解析,这里需要对elf文件的格式比较熟悉,因为我看过程序员的自我修养这本书,所以刚哥讲elf格式的部分我是直接跳过了。主要来看,就是先从头文件中提取出程序头表(program header table)的信息(条目大小,表的起始位置,条目数),并根据这些信息遍历程序头表中每一项,并从这些项中提取出原虚拟地址,目标虚拟地址,大小信息,最后实现一个memcpy函数(这里涉及传递memcpy所需要的3个参数src, dst和size)完成内存映射。
文件头如下:
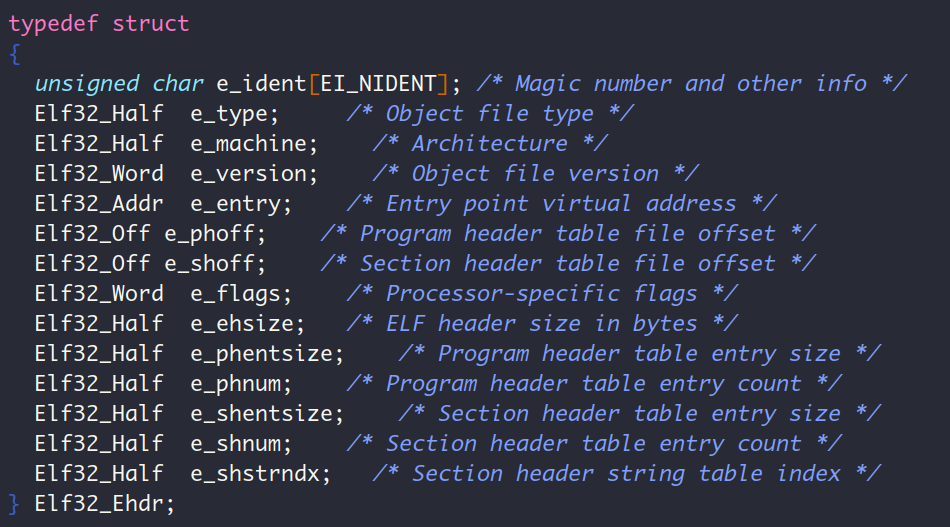
程序头表:
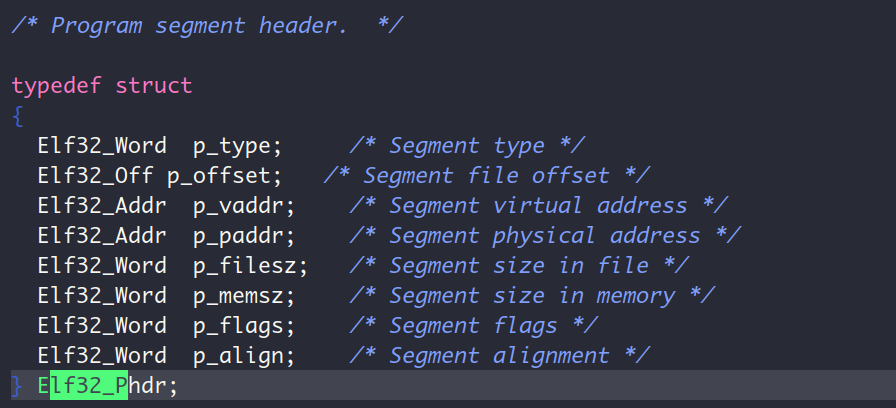
下面说一下我踩的坑,我在参照着书上的代码写好程序后,程序并没有进入理想的无限循环中,而是重新回到了BIOS,这样出人意料的结果肯定是在哪里发生了什么错误。于是我开始断点单步执行,这时候一个困扰了好一会的问题冒出来了,那就是我怎么知道我汇编程序中指定指令的物理地址/虚拟地址呢,因为只有知道这些地址我才能设置断点(bin文件不含有调试信息,因此不能用符号名),最后我探索出一个方法,那就是在我想要设置断点的汇编语句前加一个jmp $语句,这样bochs执行到这里的时候就会停下,并显示地址,于是我就得到需要的地址信息啦。经过调试,我发现我的数据复制小团队出现了问题,即我的rep movsb并不能正常的完成数据复制。
如下,圈出来的指令在程序中是cmp byte [ebx+0], PT_NULL, 按道理说该语句之后继续continues应该会回到这个指令,但是之后的执行就开始乱七八糟了,居然有回到了BIOS。不仅如此我在函数mem_cpy的最后加了jmp $语句,该语句居然也没被成功执行,说明我的数据搬运小团队出现了问题,但是代码和目标磁盘区域是对的,那么就只有一种可能—磁盘内的数据有问题。
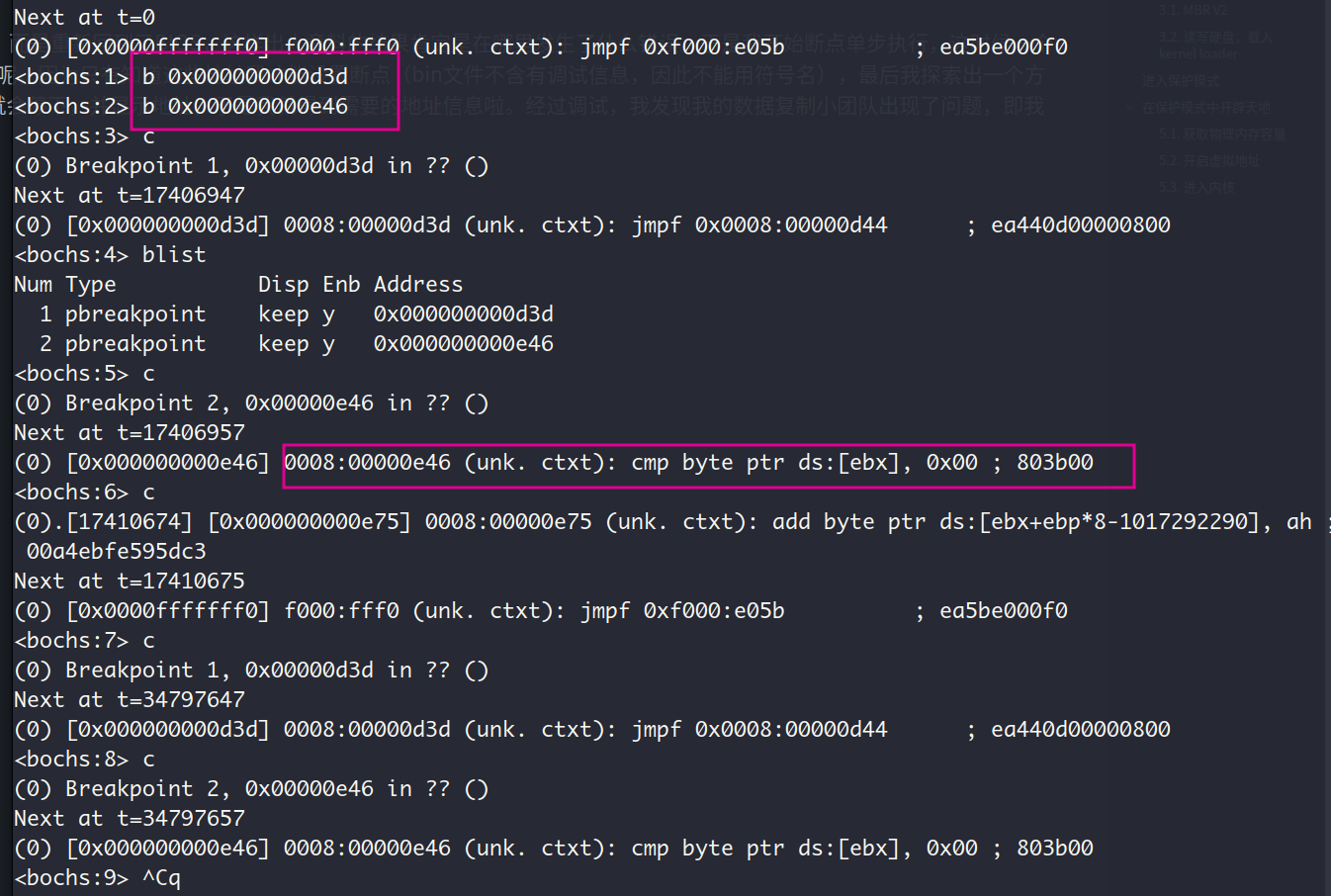
于是我查看kernel.bin的格式,居然是ELF64!问题果然出在这里😦,因为我是64位机器,所以gcc和ld默认以64位方式进行编译和链接。
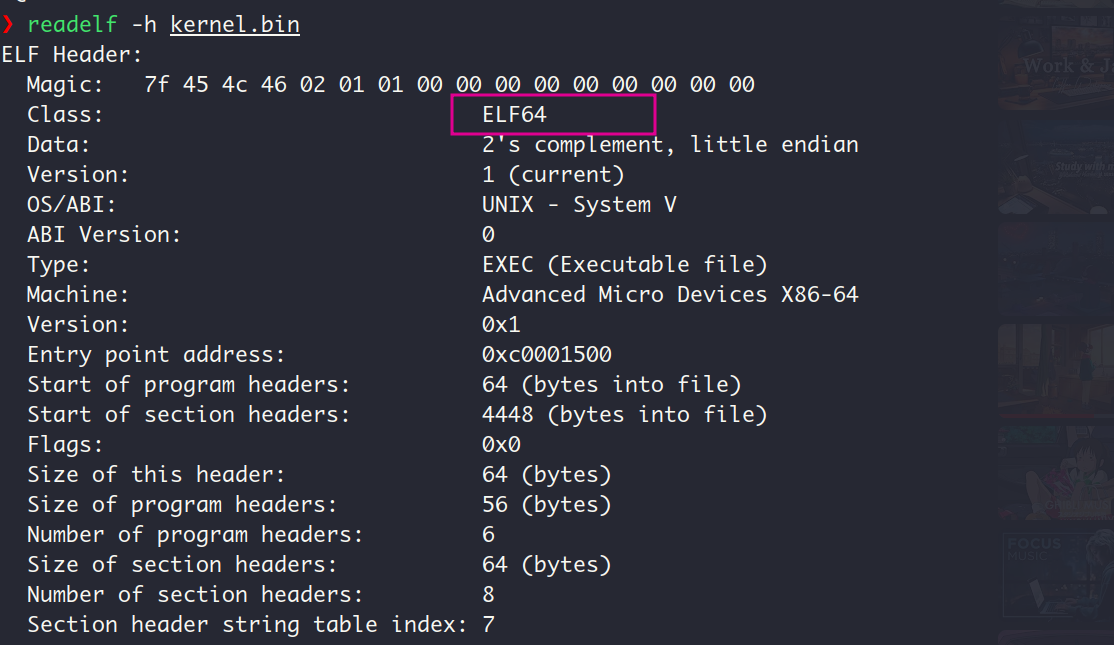
以下面这个方式(写成了一个脚本)生成ELF32格式的kernel.bin之后,程序正常执行。内核文件放在磁盘的第9个扇区 (LHS计数中,以0开始计数),并把划分出200个扇区用来存放内核文件,因为内核文件不会超过100KB,所以是足够的
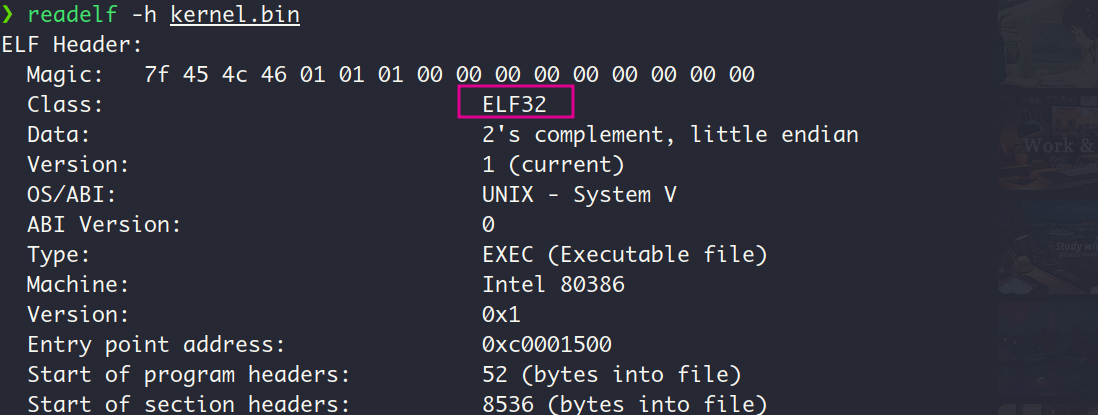
顺便贴一下我用于生成mbr.bin和loader.bin的脚本
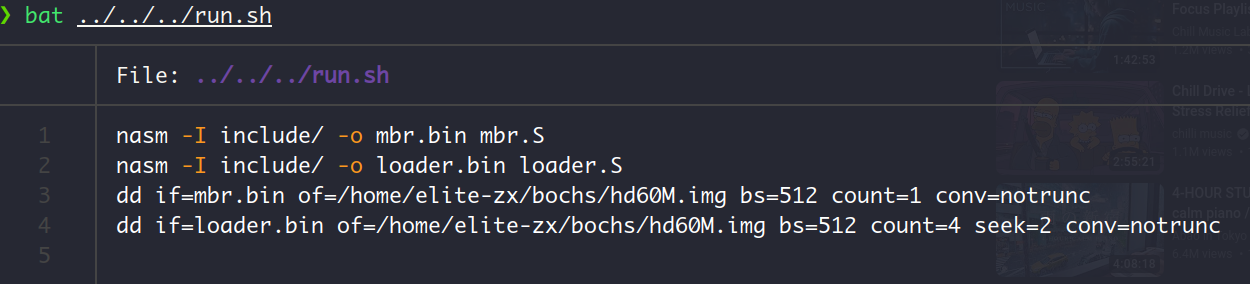
运行结果分析:
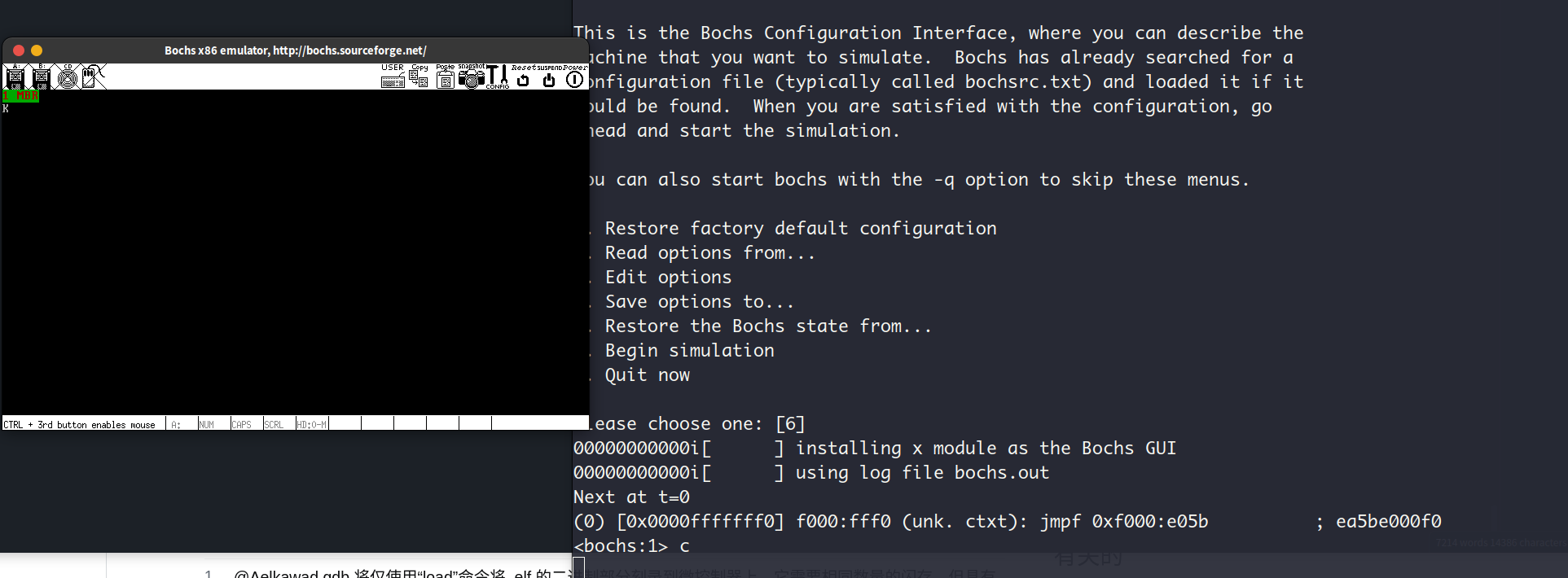
打印K字符,说明我们已经进入内核模式,这个打印语句是我自己在进入内核的相关代码中加的。
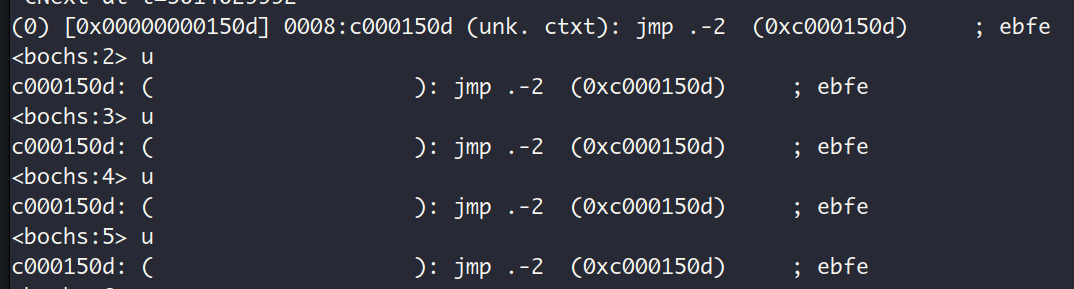
查看当前执行的指令,是指令jmp $,一个死循环,而且地址在我们的内核映象的起始地址0x1500附近,说明正在执行的就是内核中的语句while(1)
5.4. 特权级前瞻
这一节的内容写了很多,也花了我挺长时间看完。日后拾起来的话主要看看最好先看看P.247的例子。
主要的关键内容如下:
CPL(current privilege level)可以就理解为当前(current)CPU所执行的代码段的DPL (descriptor privilege level)。RPL具体指的是选择子的RPL位,它代表了真正的资源请求者的特权。操作系统正是通过RPL才避免了用户程序企图通过内核提供的服务进而恶意访问/修改内核的企图,因为无论用户如何伪造它的特权级,RPL永远代表用户真正的特权级(从用户的CS寄存器中取出,由操作系统修改)。
接下来好好说说特权级检查,CPU执行特权检查的时间点在更新段寄存器的时候,即加载选择子的时候。进一步说,是发生在访问的时候,之所以要加载选择子是因为程序要访问代码/数据了。
先不涉及调用门,当我们访问数据段和代码段(下面称为资源)的时候执行特权级检查,此时会涉及RPL的检查,当我们在请求这些资源的时候,访问者的RPL和CPL与受访者的DPL需要满足下面这个条件:$$CPL\le {DPL}{target};&&;RPL\le{DPL}{target}$$
即访问者的特权级要高于受访者(实际上这对数据段资源成立,对代码段来说,只能平级访问,也就是说要求是相等)。
接下来涉及调用门,用户程序可以通过调用门让CPU进入高特权级。门的作用用P.237的蹦床原理来形容就很形象。这时候的特权级检查就发生变化了,一共有2步检查,第一步与门槛比较,即门描述符,第二步与门框比较,即门描述符对应的内核代码。
6. 从一个简单的print开始,完善我的内核
6.1. 打印单个字符的print
这一节主要是完成一个print函数。要完成这个函数光会往显存上mov数据是不够的,还得学会如何操作显卡的端口(即寄存器)以控制光标的位置,以及处理控制字符,打印的字符超出屏幕时实现滚屏等。显卡的寄存器是目前遇到过的端口中比较特殊的,需要通过类似索引数组的方式完成对指定端口的读写,具体来说就先在Address Register中写好我们需要哪个索引下的端口,然后再通过Data Register完成对索引下寄存器的读写操作。
除此之外,这里实现滚屏的方式也很巧妙,具体体现在处理光标的移动上。这里的滚屏,具体指的就是把当前内容向上滚动一屏,滚动之后的光标应该出现在最后一行(即第24行,行数从0开始)的首位,而这个移动光标的操作正好可以与处理回车符的操作放在一起,也就是说我们可以把这个操作看作是在当前光标下处理一个回车符。在处理回车符时,我们先把bx(该寄存器被我们原来代表光标地址)对80取余,再在bx上减去这个余数,于是bx就指向了行首的位置,接着再add bx, 80那么bx就到了下一行的行首了。
在处理控制字符时,我们只处理了下面这3个控制字符 (line feed and carriage return)
\r— carriage return, ascii值为0xd,含义是把光标移动到当前行首\n— line feed,ascii值为0xa,含义是把光标移动到下一行的行首, 即回车符 (这在linux上才成立,回车符在windows上为\r\n)\b— backspace, ascii值为0x8, 含义是删除当前光标下的字符
具体实现中,把\r和\n统一当作了回车符号处理。处理\b时,先把光标往前移动一个位置,接着在光标原来的指向的字符位置处填上空格,注意这里的字符位置,是通过光标位置乘2之后得到的。
此外,print的实现定义在汇编文件print.S中,调用在C文件main.c中,是高级语言和汇编语言之间的调用。main函数中向print函数传递参数的方式就是把参数压入栈中,这由编译器帮我们完成(即编译器生成相关的机器码),而汇编函数print从栈中拿到对应的参数,这个步骤由我们自己编写。
运行结果:
这里的数字我就没有按照书上输出啦,我换成了我完成这个函数的日期。运行结果与预期一致,backspace被正确的处理了。
6.2. 打印字符串的print
本质上就是多次调用put_char, 通过判断当前字符的ASCII值是否为0(对应字符\0)进而判断字符串是否结束。
运行结果:
加个感叹号让我的内核宝宝看起来更有气势😃

6.3. 打印整数的print
我们同样可以借用put_char完成对整数的打印。关键的步骤就是完成整数到字符的转换。
先说结果,对于每个输入的整数,最终的打印形式都是其对应的16位进制数,比如我输入十进制数数字15到print中,打印的会是十六进制数F。具体的转换怎么实现的呢?参数是一个32位整数,不管我们是传递十六进制的数字还是十进制的数字,在CPU开始都是1和0组成的二进制数字,所以实际上我们要处理的就是这一个32位长的二进制串,把每4位转换为一个十六进制数,一共就是8个十六进制数,接着再把这8个十六进制数转换位对应的字符(即ASCII值),比如十六进制数F就转换为字符F。这里要注意的一点就是,在转换位字符之前,每个十六进制数用4位就可以存下了,但是转为字符之后,此时的值是一个ASCII码了,至少需要7位,因此拿一个字节来存放这个字节结果,这也是为什么在函数开头要申请8个字节的用于存储转换结果的缓冲区put_int_buffer。最后我们还要去除数字高字节中的0,使得打印结果更精简
eg:
0x00001234 \to 0000\_0000\_0000\_0000\_0001\_0002\_0003\_0004 (32bits) \to'1''2' '3' '4'
运行结果:
今年(2023年)快结束了,那么就打印2023吧!
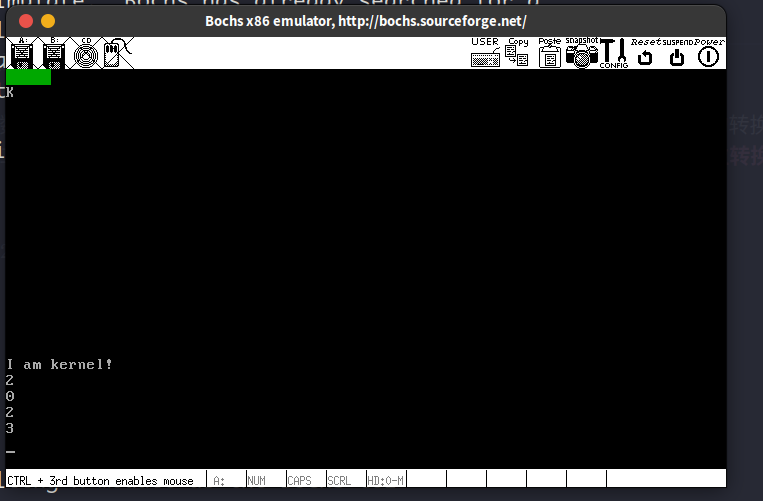
可以在进入put_int时设置断点,查看此时栈的内容

可以看到,函数main传递过来的参数在从栈顶数下来的第9个项的位置 (从0开始计数),前9项是指令pushad压入是8个4字节的通用寄存器和main函数的返回地址,说明代码中从[ebp+4*9]取出参数是正确的
7. 让中断驱动操作系统内核
7.1. 初步建立33个中断,内联汇编开始发挥功效
这一节呢用了比较长的时间,大概有个3天吧。主要是上个周末,休息了一天,也不是完全休息,但是也没搞OS,而是去重新配置了一下vimrc, 加了几个好用的插件,比如vim-surround, vim-which-key等,我就喜欢这种高度自定义并且可扩展的软件 (另一个就是obsidian),只要vim还能满足我的需求,我宁愿花时间去配置它,也不会转去vscode
那么就简单的谈谈这一节吧。 这节我们要做好的事情主要就2件:
- 构造好IDT
- 提供中断向量号
对于第1点,那就是写好中断处理程序并把记录着中断处理程序的地址表(说是表,本质上还是个数组)的地址加载到寄存器IDTR中,这样CPU才知道中断处理程序在哪里
对于第2点,那么就要学习可编程中断控制器8259A芯片,也叫中断代理。我们要初始化好它,并通过它设置好中断向量号的起始值。在实现中,中断向量号的起始值被设置为0x20,也就是32,从0开始计数的话就是第33个项。之所以是这个值是因为,中断向量号的前32个值(0~31)是被CPU保留的(详见P.303 表7-1),提供给CPU内部中断使用的。8259A主片上的第一个引脚被底层电路设计为接受来自时钟的中断信号,为了简单的检测程序是否成功,这一节只让CPU响应这一个外部中断。
这一节的实现中,值得说道的一点是IDTR寄存器的装载,相关代码如下:
uint64_t idt_operand = ((sizeof(idt) - 1) | ((uint64_t)(uint32_t)idt << 16));
asm volatile("lidt %0" ::"m"(idt_operand));其中idt是关于中断处理程序的地址数组的数组名,数组名在C语言中同时也是指向数组首元素的指针(在32位系统上,大小为32个bits)这个简单的知识点大家应该都知道。因为IDTR和GDTR一样,都是48位,高32存储table的基地址,后16表示表的界限。所以要完成IDTR寄存器的装载,就是通过这32位指针得到正确的48位的数据
首先是表界限,因为地址从0开始编址,而表界限要代表表的最后一个字节,所以这里的sizeof(idt) (sizeof运算符得到字节数)值要减去一个字节。CPU通过对比访问的地址是否超过这个表界限值来判断是否越界。例如,如果 IDT 总共有 256 个条目(实际上,在这一节我们创建了33个条目),每个条目 8 字节,那么 sizeof(idt) 将是 256 * 8 = 2048 字节。然而,由于从 0 开始计数,IDT 的最后一个字节实际上是第 2047 个字节(从 0 开始数到 2047 总共有 2048 个字节)。因此,段界限应该是 2048 - 1 = 2047。
其次是对32位指针的处理,因为要左移,有高位数据丢失的风险,所以要先扩容为64位。问题是为什么不直接扩展为64位而是先转为32位无符号数再扩展呢?主要还是因为符号扩展问题,当你直接将一个较小的数据类型(如 32 位指针)转换为一个较大的数据类型(如 64 位整数)时,关键问题在于如何处理额外的位。在某些系统或编译器中,如果源类型是带符号的(如 int32_t),直接转换可能会导致符号扩展 (保持了数值的符号(正或负)),这意味着原始值的符号位(最高位)会被复制到新值的所有额外位上。对于指针来说,这通常不是期望的行为。指针通常应该被视为无符号值,因为它们表示内存地址,不应该有符号扩展的行为。但是由于指针在语义上不是有符号还是无符号,因此编译器可能不会自动将它们视为无符号数进行扩展。所以我们在扩展之前要先把32位指针idt明确的转换为32位无符号数,再进行扩展。因为这部分书上是一笔带过的,可能刚哥认为读者C语言知识都很扎实吧。所以我在这里添上一笔。
还有一个值得说道的一点就是中断程序地址数组的建立,这是在kernel.S中完成的。主要利用的就是编译器(这里说汇编器nasm应该更准确才是)会把属性相同的数据(数据/代码)当在一起,而不会理会程序中的section关键字。具体来说,编译后的目标文件中的段是根据它们的类型和属性(而非在源代码中的物理布局)来组织的。因此,所有的 .data 段都会被合并到目标文件的一个 .data 部分,所有的 .text 段被合并到一个 .text 部分,即使它们在源代码中是交错排列的。所以,在每个中断程序中定义的4字节地址数据intr_%1_entry才能被合并在一起,形成地址连续的数组结构。
从这一节开始,我将在我的代码注释中尽可能的遵循linux内核的注释风格,准则参考:Writing kernel-doc comments
下面来谈谈我踩的坑,这个坑各位大概率不会踩,所以赶时间的各位看官可以跳过。
我在运行启动bochs之后,并没有看见时钟中断被正确的触发(即不停的打印interrupt occur),屏幕上只有几个初始化过程中的提示语句。
而且系统也因为某些错误而被迫重启,又回到了跳转到BIOS的入口地址的jmp语句
于是我开始了我的调试过程,仿造之前在汇编程序中加入jmp $语句以获取指令地址进而设置断点的思路,我首先在main函数中加入while(1),如下:
(这里提一句,clang-format格式化工具哪都好,就是这个单句while的分号它非的给你换行,还不允许你通过配置.clang-format单独修改这个行为😄)
然后运行内核,结果如下:
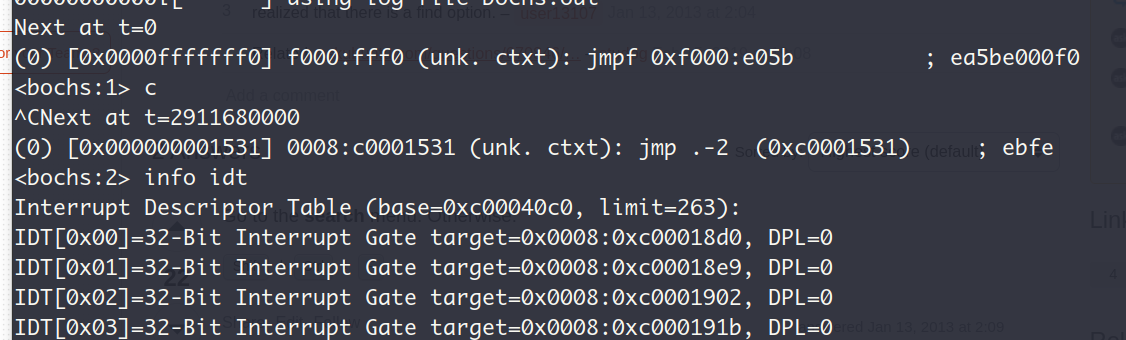
这说明内联汇编语句sti语句的物理地址为0x00001531,虚拟地址为0xc0001531。 下面去掉sti前的while语句,在0x00001531处设置断点,如下:
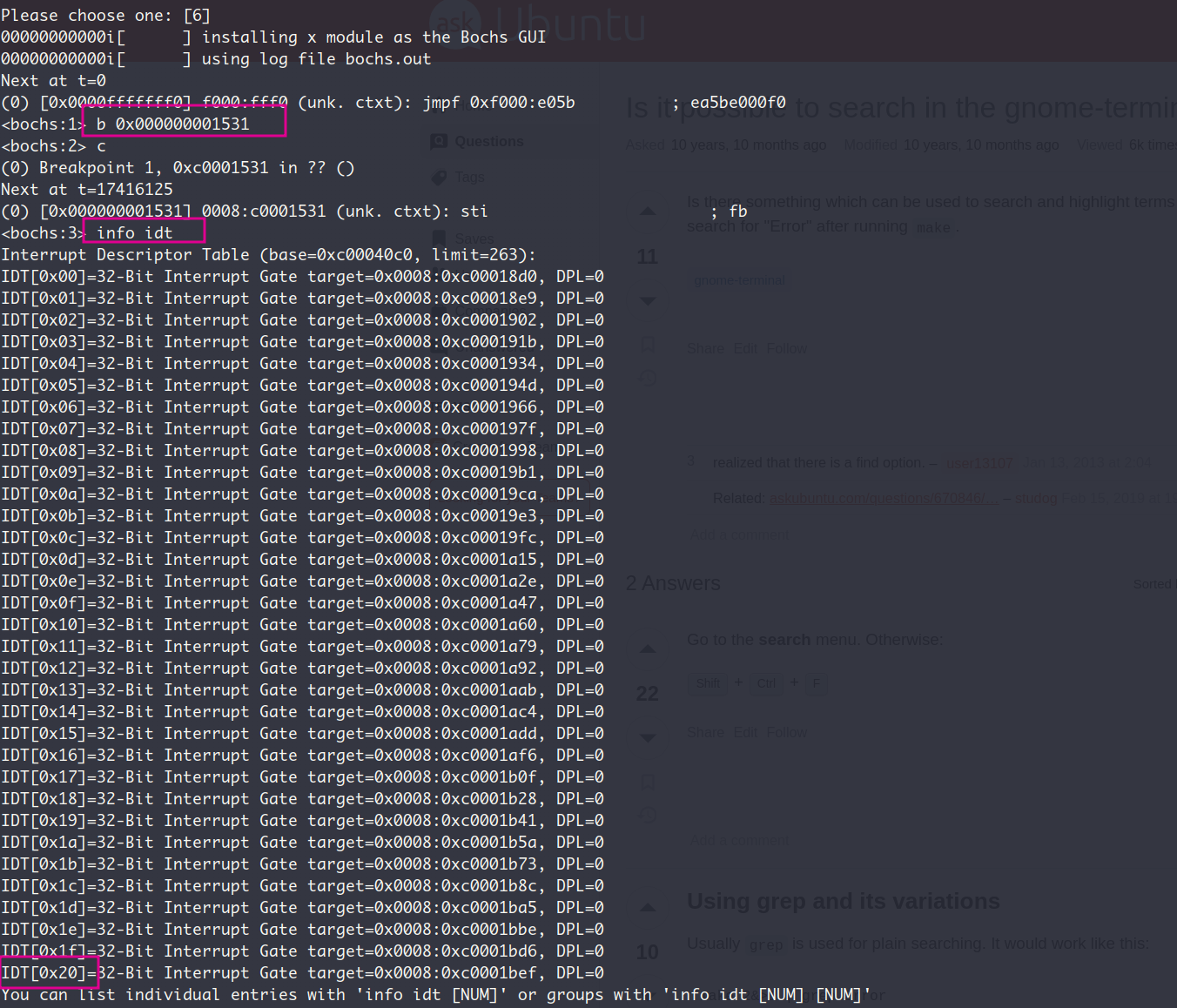

可以看到的是,中断描述符表确实是如预期的建立起来了,LDTR中的内容也与IDT的起始地址一致,但道理来说中断处理程序应该是被能够被正确调用的。在确认了我的中断代理设置无误之后(即只放行时钟中断),我确定出问题的地址在中断处理程序本身!
于是我来到kernel.S, 在中断处理程序中加上了jmp $,结果如下:
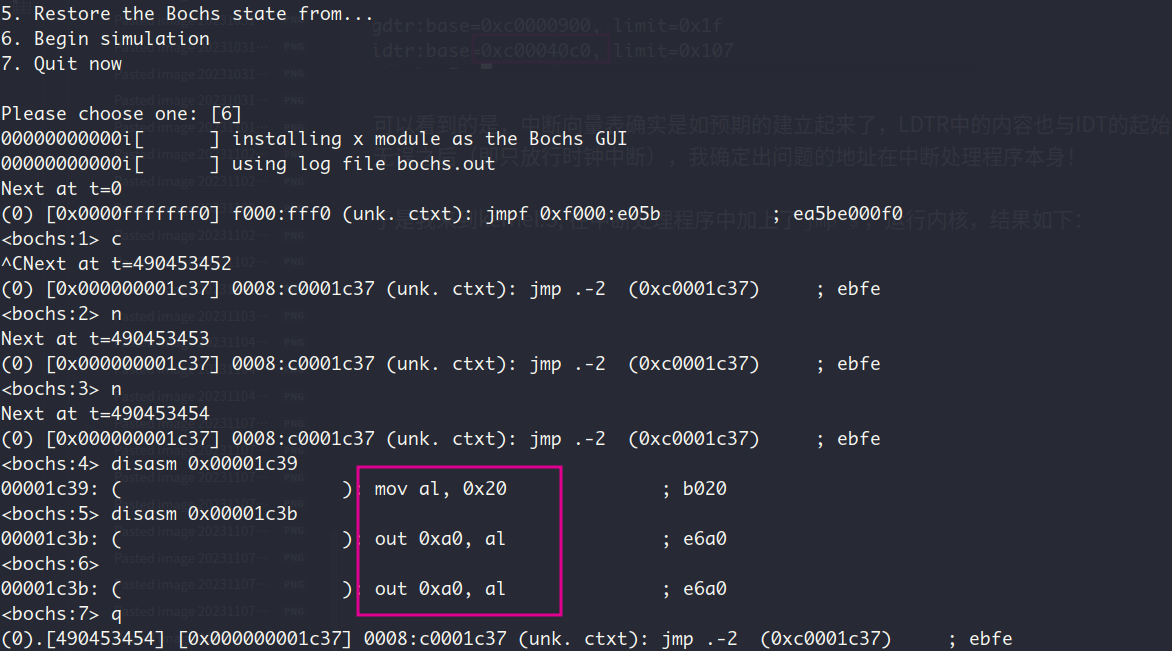
上图可见,通过对比jmp指令后续的的指令和定义的中断程序,可以发现现在就是在执行中断程序,因此中断程序确实是被正确的调用了。那么最终的错误一定就是中断处理程序本身的错误。
因为我把jmp $放在的时call put_str指令之后, 但此时屏幕上并没有正确的打印一条interrupt occur信息,这让我确信了错误出现在上一节完成的put_str函数中。经过对print.S的排查,发现原来是在完成put_char函数的roll_screen操作时,没有正确定义edi的值 (🥲),导致我的数据搬运小团队把数据搬去了一个未知的内存区域。这也可以解释为什么系统被bochs重启了:在多次运行时钟中断的中断处理程序之后,数据搬运小团队移动了一大堆数据到未知的内存区域,最终覆盖了某些关键指令或数据,导致系统被bochs重启。
这也让我认为,今后每次在进入下一章之前,一定就充分的测试当前章节完成的功能点。在上一节中对print.S的检测中就没有检测滚屏操作是否能正常执行,才让我花费了不少时间在这一章找到这个错误。
最终的运行结果:
时钟中断一直在发生,因此不断的打印interrupt occur
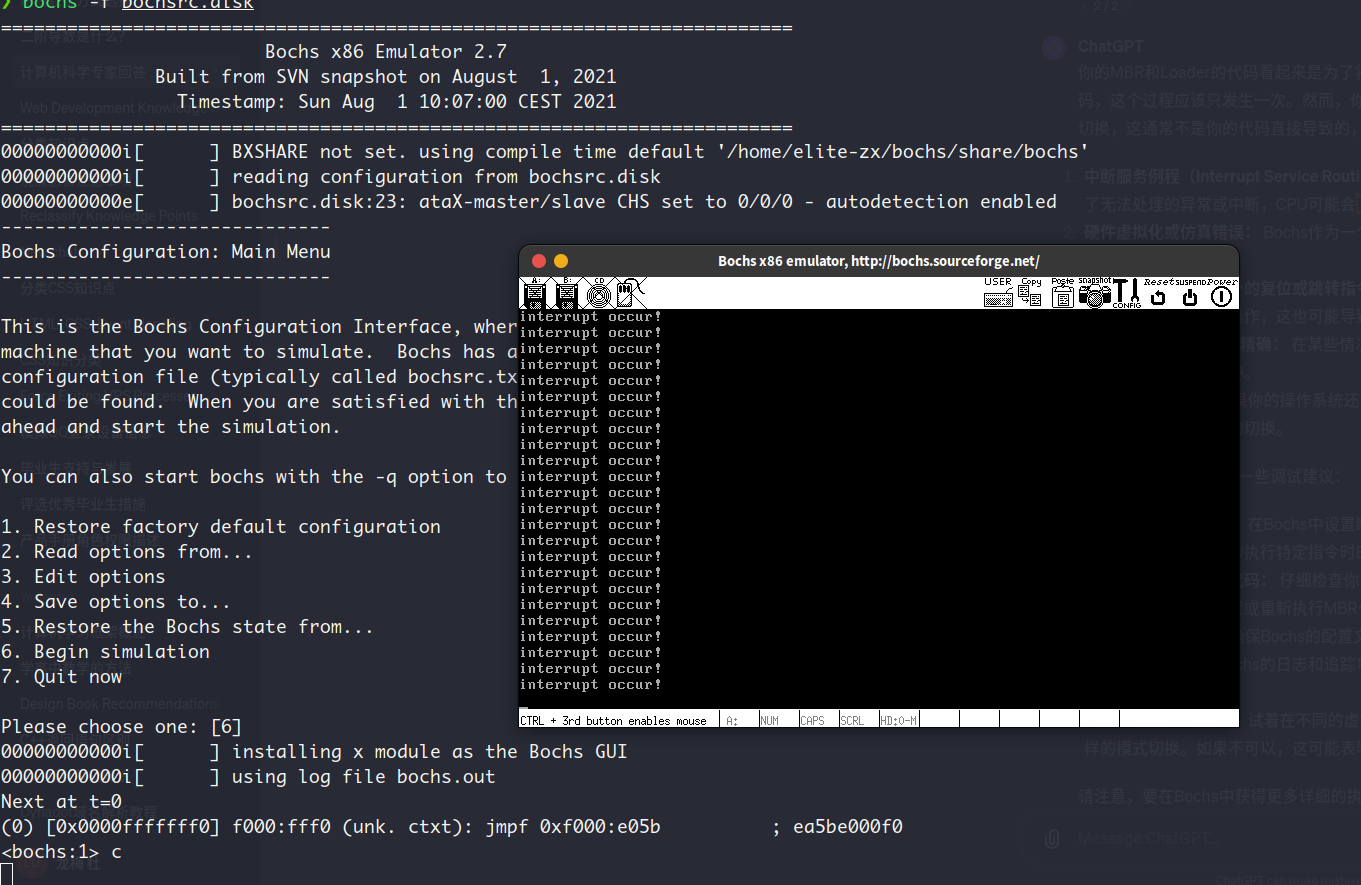
查看中断描述符表:
一共建立了33个中断,最后一个中断为类型是外部中断的时钟中断

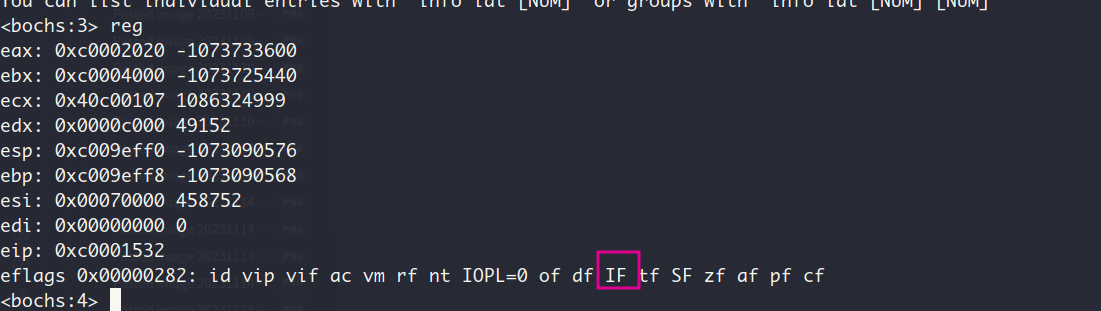
查看标志寄存器eflags的IF位:
sti指令把IF置1, 对CPU执行开中断,使得CPU可以响应中断代理8259A发来的INTR信号和中断向量号信息
7.2. 移动中断处理函数到C程序中
上一小节在汇编程序中完成了中断处理程序,这一节把中断处理程序移到c程序中,毕竟C程序更简洁也更容易编写和维护,而在汇编程序定义中断程序的入口地址。
7.3. 深入探究中断时的栈
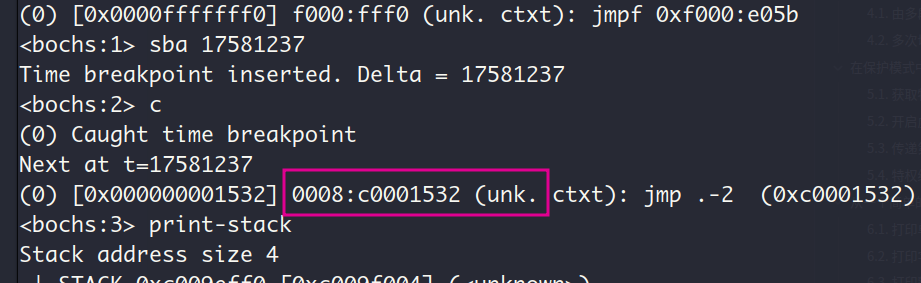
- 通过bochs调试命令(主要是
show int)找到中断入口点
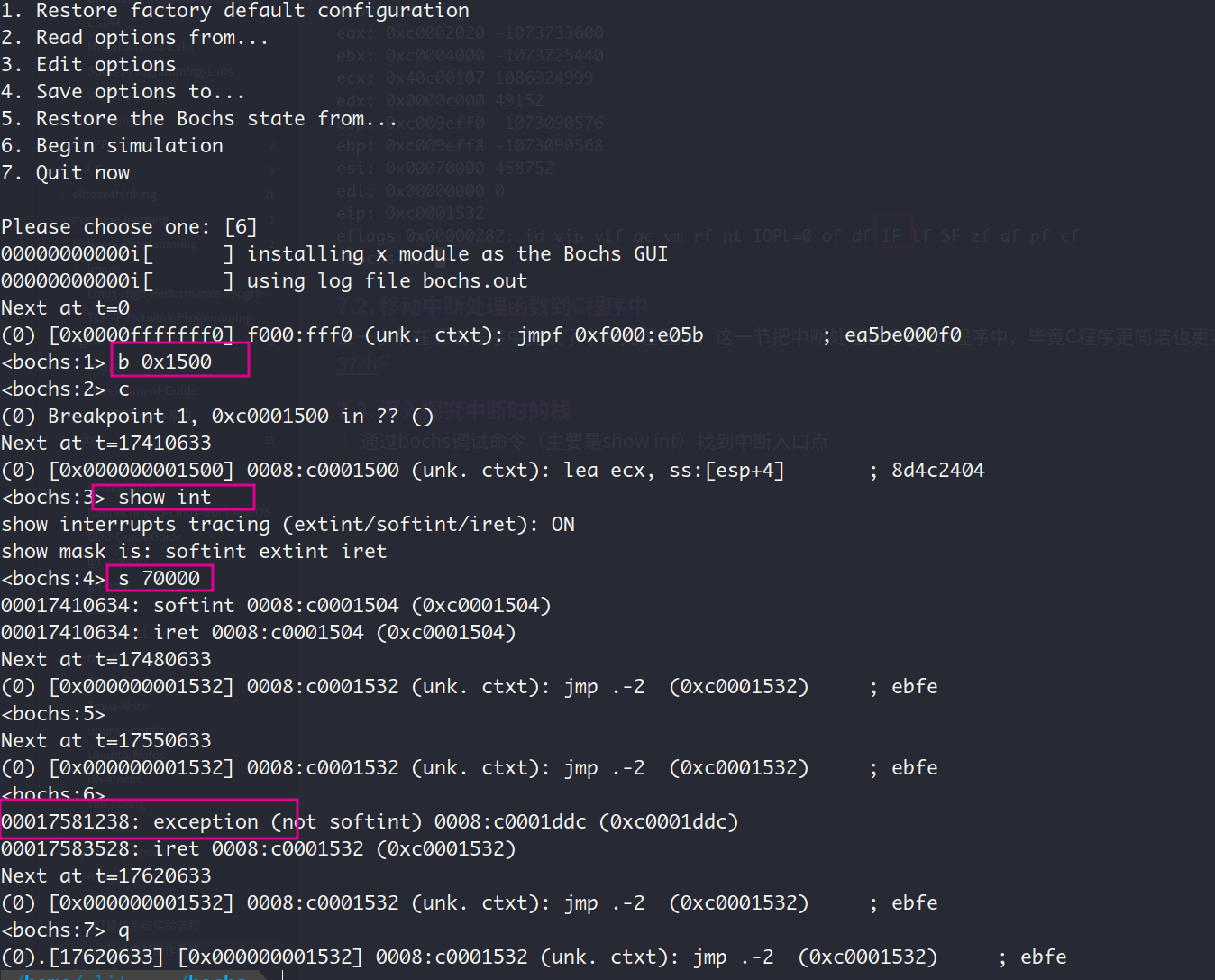
因此可以通过调试命令sba在中断入口点的前一个指令处设置断点,即第17581237条指令。执行print-stack查看此时的栈(也就是即将进入中断前的栈),在上方的是低地址处的栈顶。执行r或reg查看此时的标志寄存器,可见IF位是置1状态,CPU可以响应可屏蔽中断(即响应来自中断代理8259A的INTR信号)
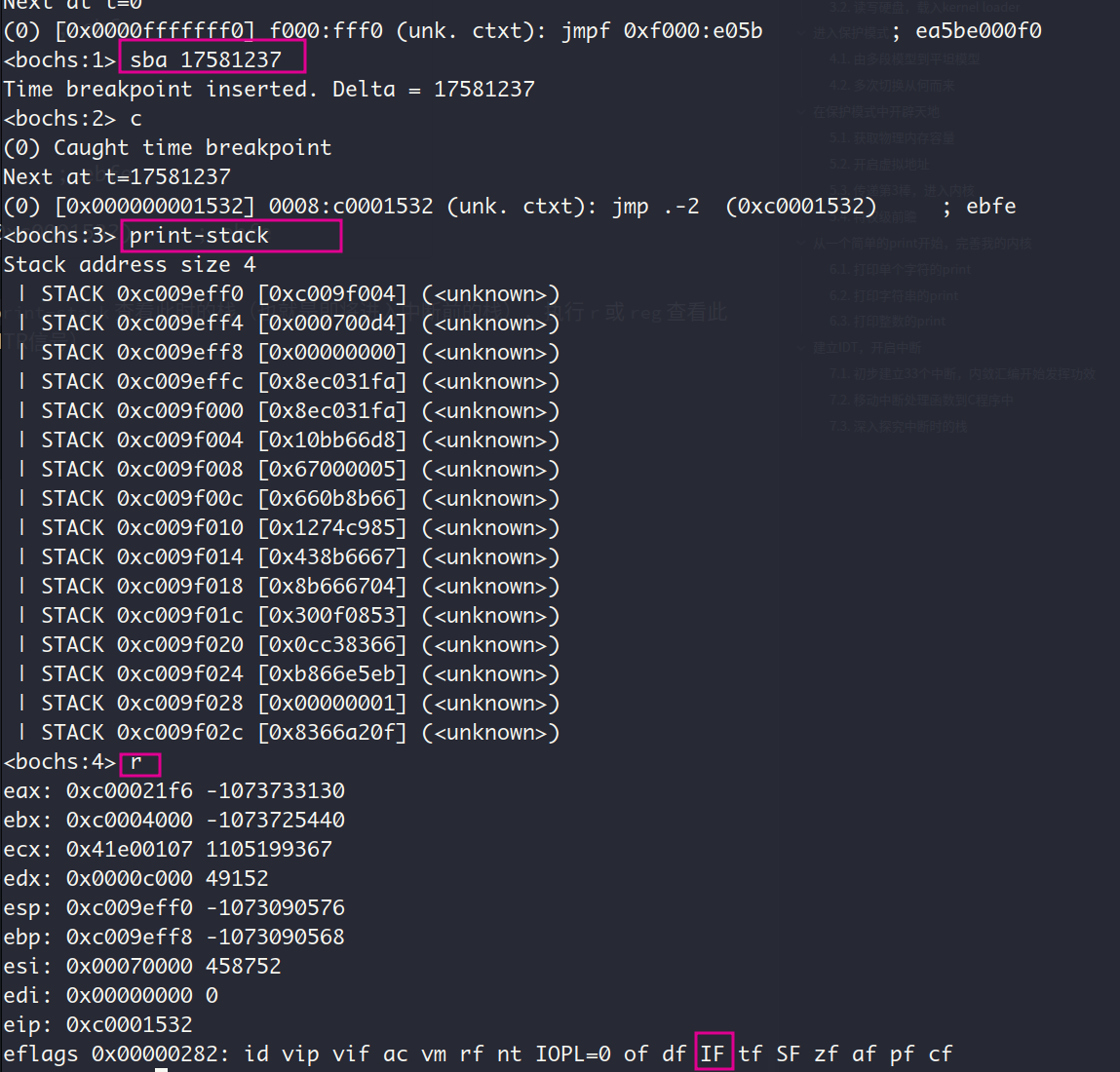
执行s进入中断,下一个指令正是中断处理程序的push ds指令


CPU为了避免嵌套中断,进入中断后会把标志寄存器的IF位置0,我们来验证一下:还是用r命令查看标志寄存器,可见其IF位确实被置0了
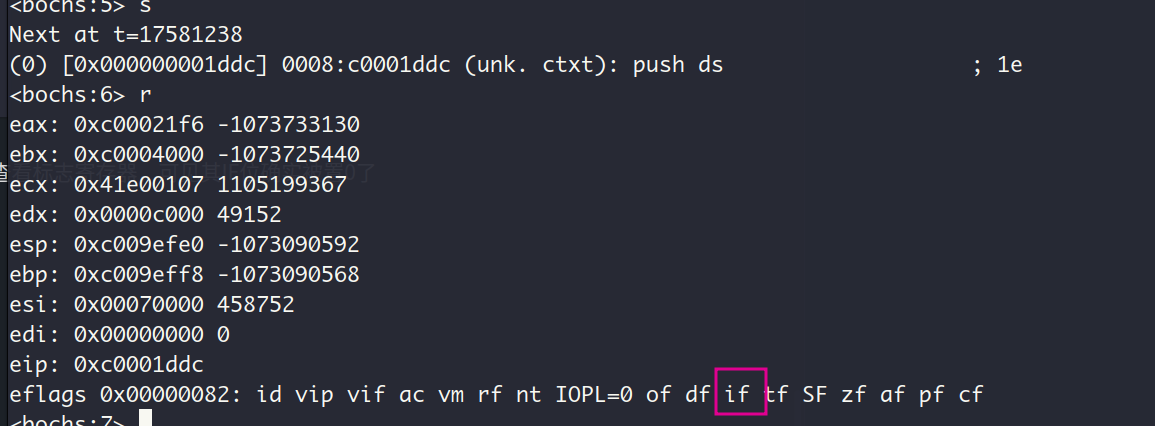
现在查看刚进入中断后的栈:
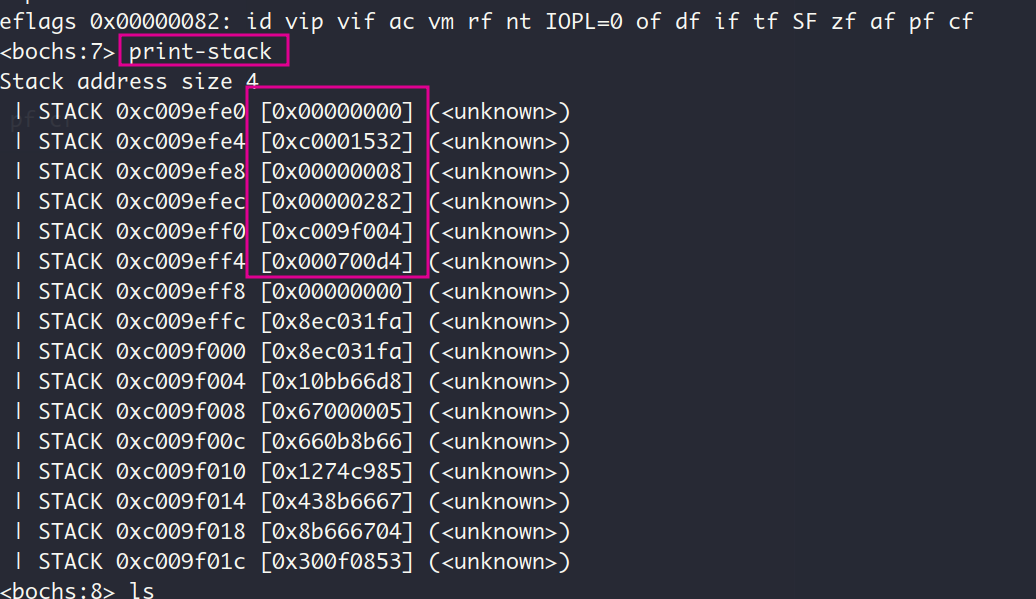
从栈顶的0x0是中断程序的第一条指令push 0执行的结果,依次往下应该是EIP, CS, 标志寄存器eflags, ESP_old, SS_old,还是来验证一下:
- CS : EIP — sba执行完毕后显示的指令地址为
符合✔️
- eflags — 还记得我们刚刚进入中断前查看的标志寄存器:

符合✔️
- SS_old : ESP_old — 对比栈中相应的值和进入中断前的ss和esp的值,发现对不上,我想不应该啊,咋回事呢?原来在我们的实现中发生中断时,CPU是从内核的main函数跳转到中断程序去执行,属于特权级的平级转移,CPU会把这种转移当作普通的直接远转移(即使CS前后一致,还是会压入在栈中CS),因此不会有栈的切换,也就没有在栈中压入ESP_old和SS_old
7.4. 让时钟中断来的更加猛烈些吧
这一节通过设置可编程计时器Intel 8253完成了对时钟信号产生频率的提速
运行结果:
感觉不出来有什么提速,毕竟窗口就这么个大小,奇怪的是这里额外还触发了CPU内部的0xD号中断(General protection fault)
8. 让位图大放光彩,实现内存管理
8.1. 磨刀不误砍柴工—学习makefile, 实现assert断言和字符串操作函数
这一节讲解makefile的部分让我收益颇深,之前学cmake的时候,make和makefile对我来说就是个黑盒子,不知道里面具体是什么东西,只会拿来就用。现在要开始自己手写makefile了之后,也算是看见了makefile的真面目了。在我看来,makefile归根到底还是个脚本文件嘛。
为了后续方便调试程序,这里要求自己实现一个给内核用的ASSERT断言,其中用到的宏函数的可变参数我倒是第一次用,看样子C语言还有很多东西我不知道呢。这里提一嘴makefile的内容,书上要求给gcc指定选项-Wstrict-prototypes和-Wmissing-prototypes,目的是要求项目中的函数都有函数声明并且函数声明中必须带有参数类型,这意味着没有参数的函数也要加上一个void类型说明, 我没这个习惯,而且参照linux内核的代码风格上也没要求这两点,于是这2个选项我是去掉了的。
用刚刚学到的make—gcc—ld工具链生成程序,目标文件和内核文件kernel.bin确实都正确生成在了build目录中,但是我遇到的问题是伪目标hd对应的dd命令看起来是正确执行了,但是实际上bochs下的hd60M.img并没有更新,必须在终端手动执行dd命令才会更新🥲,搜索了一顿没找出原因,暂时还不清楚为什么。
btw,用gpt4给这些功能用途明显的函数生成注释真的很方便,这工具真的极大的减少了我在google搜索的时间,虽然有时候确实会牛头不对马嘴,但是大部分时间还是很可靠呢。有些问题这玩意不能解决的时候,我就只有在google上 do english searching了,找找stackoverflow上的回答或者官方文档什么的
8.2. 管理内存的工具—位图bitmap的实现
刚哥人是真好啊,不像教科书那般给你生涩的下一个位图的定义,而是给你扯了一页的内容告诉你怎么理解这玩意,中国大学的教材但凡能有点这种风格,也不至于那么误人子弟😅。
实现方式上没什么可说的,书上都有,倒是bitmap_scan方法上我自己尝试写了一下,但是博主我怕后续这里出问题,还是按照书上的内容实现了。
8.3. 开始砍柴了!实现内存管理系统
8.3.1. 饭要一口一口吃,先初始化内存池
内存管理系统要管理2块,一个是用户的,一个是内核的,这两者不能相互干涉,毕竟特权级都不一样。在这一小节中,建立数据结构内存池以规划内存,把物理内存分成了2部分,内核和用户各一半,作为各自的内存池,各用各的。同时建立好内核物理内存池和用户物理内存池,分别管理内核和用户的物理内存分配请求。内存池的结构用到了上一节定义的位图,这是内存池管理内存的关键。
此外,不仅需要物理内存池,还需要虚拟内存池。
为什么需要虚拟内存池,我还是简单总结一下,系统运行在分页机制下,不管是内核还是用户程序都是用的虚拟地址。当它们需要申请内存的时候,内存管理系统先是从他们各自的虚拟内存池中分配出一块空闲的虚拟地址,然后再转去物理内存池找到块空闲的物理内存来完成映射,此外还有别的好处,遇到了再提。
在初始化内存池的过程中我是遇到了点小问题的,在这里记录一下,那就是系统运行之后,一直触发0xE号中断,也就是缺页中断,因为之前把这些中断的处理程序都指定为了一个简单的打印中断号的程序,所以运行后的屏幕全是0xE:
我在mem_pool_init中加了几次while(1)之后,发现用于管理内核的可用内存的位图的存放位置MEM_BITMAP_BASE少打了个0,本该是0xc009a000,而我写成了0xc009a00,而这个虚拟地址所在的虚拟页面是没有映射到物理页框的(目前只映射了虚拟内存的0~4MB和3G~3G+4B,这是在开启页表机制的时候完成的),当CPU访问这个地址的时候(执行bitmap_init函数的时候),必然要触发缺页中断啦,而我们的临时的中断处理程序又不能解决这个问题,所以只能一直不断被触发啦。
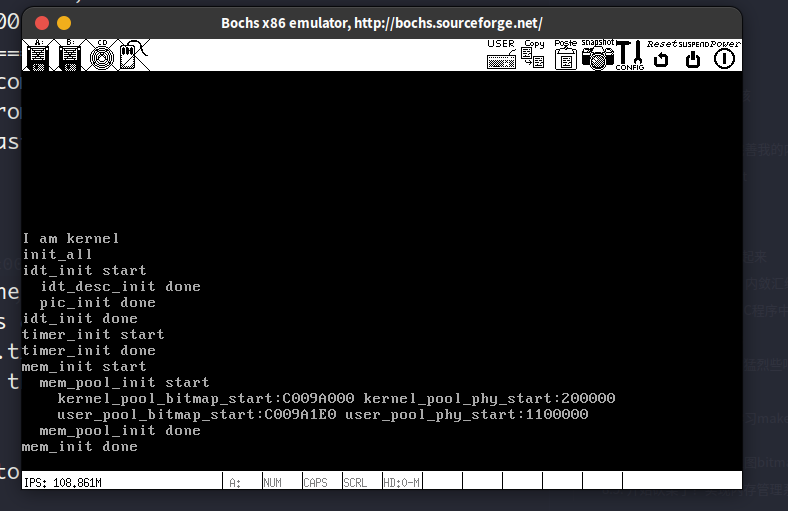
解决掉这个问题之后,运行程序,结果如下:
可用物理内存的起始位置kernel_pool_phy_start是0x200000, 这个值是除去了这2MB的已用内存的结果,这2MB中的低1MB拿来放BIOS和内核,另外1MB用来放PDT和PTs
再多说一句,因为是在编写操作系统内核嘛,所以C语言的系统库肯定是用不了了,而定义在系统库里的关键字bool, NULL, true, false又得在内核程序中用到,所以得在一个头文件中自己定义这些关键字,我选的global.h:

不知道有没有人跟我有一样的问题,这个问题也有点傻傻的,那就是为什么可以用int, unsigned这些关键词呢?答案是:关键字如 if, else, int, double, unsigned 等是 C 语言的一部分,它们是由编译器(如 GCC)本身直接提供和识别的,而不依赖于任何外部库。这些基本的语言结构和类型是编程语言的核心组成部分,编译器在解析和编译代码时直接处理这些元素。因此,即使在不包含标准库的情况下(如在裸机或内核编程环境中),这些基本关键字依然可用。我之所以有这样的问题,还是对编译器不够了解,哪天一定得看看编译原理这本书呢
8.3.2. 路要一步一步走,先支持分配页大小的内存
这一节先实现对页大小的内存的分配,对任意字节尺寸的内存分配在后续实现。
要实现这一点,需要对分页机制了解的比较透彻,我在这里还是简单总结一下。首先吧,现在地址对CPU来说都是虚拟地址了,操作系统总不能直接把物理页拿给进程吧,它也用不了,因为cpu看到的都是虚拟地址,此时已经开启分页机制了,如果进程用物理地址,那cpu也会用页表机制给它一顿转换,变成另外一个物理地址。那么对进程中提出的页分配请求呢,操作系统首先得分配给进程虚拟页,这样一进程才晓得能用的地址是什么,但是这个地址是否真正有效呢?还取决于这虚拟页到底是否跟物理页对上了,进程总不能拿着个虚无的虚拟页往里面倒腾数据吧,如果确实存在它的本体—物理页,那这个虚拟页就可以被进程拿去用,于是乎,操作系统要完成的关键2步已经显现出来了: 1. 分配虚拟页 ,2. 分配物理页。 别急别急,还有第3步,别忘了我们现在是在分页机制下呢,所以还得 3. 建立PDE和PT以完成虚拟页和物理页的映射。
这一节的难点就是下面这2个函数:


这2个函数都接受一个虚拟地址vaddr,并返回一个新的虚拟地址new_addr, 这个new_addr可不是一个普通的虚拟地址了,经过分页机制下的CPU的一顿转换 (其实就3个),new_addr最终能变成vaddr对应的页目录项PDE/页表项PTE的物理地址。这部分得把分页机制玩的明明白白的才能彻底理解呢,简单说一下核心思想就是利用虚拟地址的高10位是虚拟地址对应的pde在页目录表的索引,中间十位是pte在页表中的索引,靠着CPU对虚拟地址的3步转换,凑出一个目标虚拟地址。书上P.391~P.393刚哥已经说的很清楚了,这里就不在赘述,
还有一点就是用bitmap_scan函数查找位图以确定可用的页面数量时,对物理页来说,一次查找一个,如果需要多个物理页,那么就循环的调用bitmap_scan; 对虚拟页,调用一次bitmao_scan分配多个虚拟页就行。原因是虚拟页是连续的,而物理页不是,物理页是可以分散在内存中的,这也是页表机制能提供内存利用效率的原因,如果我们在向物理页申请物理页时要求连续,即给bitmap_scan的pg_cnt参数传递大于1的值,那么分页机制的意义不就没了吗。
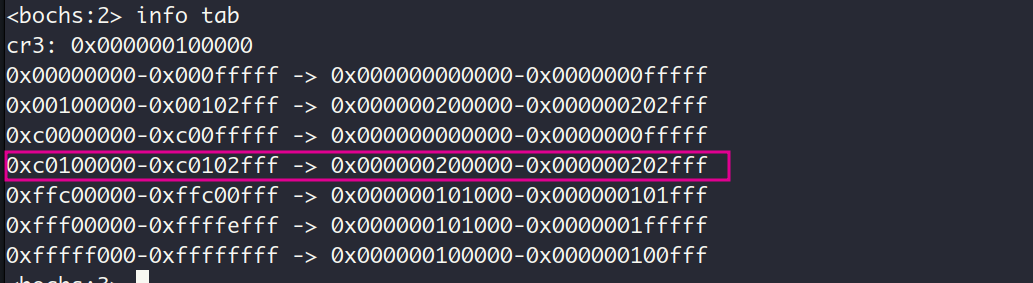
在第5章,我们把虚拟地址0x00000000~0x000fffff 和虚拟地址 0xc0000000~0xc00fffff (即低位1MB和3GB~3GB+4MB) 映射到了物理地址 0x00000000~0x000fffff, 对内核来说呢,它存在与虚拟地址空间的高1GB(3GB~4GB)中,那么从0xc0100000开始的内核虚拟地址 (内核虚拟内存池的起点是0xc0100000)也要映射到0x00010000开始的物理地址吗 ?不行哦,在0x00010000开始的物理地址中,0x00100000~0x001fffff (共1MB)已经被拿来放最初的页目录表和页表了,咱们得保证这部分物理内存不能被占用,所以在实现中是把这部分物理内存归为了used_mem的,物理内存池管理的物理地址的起点在0x00200000。
下面来测试一下,在内核的main函数申请3个页面,运行结果如下:

嗯,很好,分配的虚拟页面的起始地址正好是虚拟物理池中第一个空闲虚拟页的地址,看样子我们的位图管理内存机制是正确运行了的。
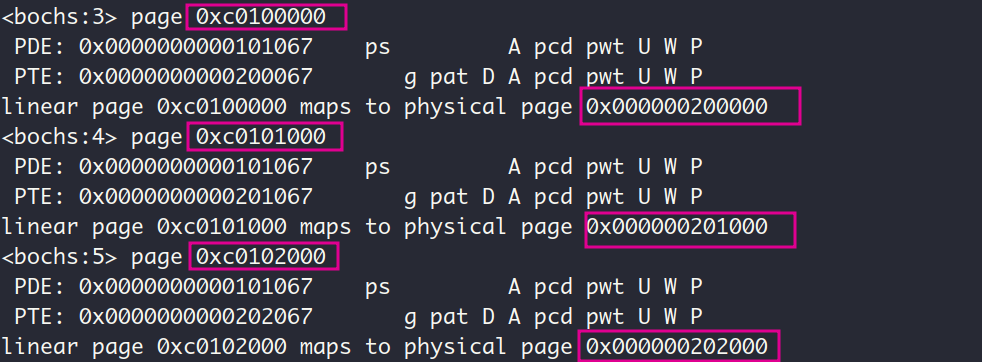
再用看看页表,验证一下这3个虚拟页是不是虚无的,内核可不需要虚无的东西呢
看样子这3个虚拟页已经成功映射到从0x200000开始的物理内存了, 不确定的话可以用page命令单独查看下这3个虚拟页的映射情况:
最后查看物理内存的位图,位图的起始虚拟地址被设置为0xc009a000, 因此用命令x 0xc009a000查看该虚拟地址处的内容即可查看位图

开头的2个字节内容是0x00000007, 即0x0111, 也就是说位图的低3位被置1了,表示3个物理页被分配出去了,符合预期。
9. 单线程进程的光荣进化—多线程机制的建立
这一节呢,先是花了不少的篇幅来说清楚进程和线程的关系,刚哥是真贴心啊。归根结底,进程=线程+资源,CPU执行的就是线程。如果你要说你压根不晓得线程啊,难道我写的hello world程序执行的时候也叫线程?那么我要说如果进程中没有创建线程,那么这个进程就视为单线程的进程。哈哈哈,所以说概念这种东西真没必要隔那咬文嚼字的,没啥意义,在我看来能自圆其说,又符合实现的方式即可。
说到这里,在讲述这一章内容之前,我想反思一下过去的学习方式。各位看官不感兴趣的可以移步到下一个段落哈。过去的我呢,其实也没有多旧,就在我看这本书之前吧,我看书总习惯写点什么,比如我看程序员的自我修养这本书的时候,硬是闲的蛋疼的非要把每一章讲的知识点总结下来,好像不用自己的话说一遍就不爽似的,现在我觉得这样的做法极其的浪费时间,而且效益也不好。我为什么会有这样的思想改观呢?因为我有一天意识到,我又不是要出书,我干嘛要费心思把这些东西重新写一遍,我理解力又没那么差,而且这种行为真的无异于中学时代靠记笔记安慰自己的做法,真的没意义。从另一个角度出发,作为一个初学者,刚学习完某一章,你又能写出个什么东西呢?表达上绝对是有失偏颇的。不得不说,这样的学习方式,是我上大学以来学什么东西都很慢,学什么东西效果都不好,学完了还没有任何成品的根本原因。 现在我认为学某个科目,某个领域,最好的做法就是快速过一遍知识点,千万别搁那咬文嚼字的,看懂个七七八八就行了,然后立马实践,实践才能让你真正记住知识,自己折腾过的过程,绝对比那枯燥的文字更能在你脑中留下印象,最后实践完了,既能收获个成品,并且还可以带着实践的经验重新审视这些知识,总结出一些领悟和心得,这样的领域和心得才是唯一有价值记下来的。这里贴一个博客链接,讨论的就是学计算机科学是否要记笔记,我认为博主说的就很好,还留下了评论。这部分就写到这。
这一节算是比较有难度的了,整体我都来来回回看了很多遍才开始实现。其实本章围绕的一个核心问题就是:执行中的线程cur_thread遇到时钟中断(陷入内核),并在时钟中断中发现该线程时间片到期了(即cur_thread.ticks==0),那么该线程就要被内核中的调度器schedule函数和切换器switch_to换下,并让CPU执行新的线程。要怎么保证线程还能恢复! 是的,我认为最关键的问题就是,怎么让线程恢复执行。这主要依靠一个switch_to中的ret指令和中断入口程序(kernel.S)中的一个iret指令,操作系统要组织好栈使得这2个指令的运行后能够恢复线程。
简单用drawio(btw:向开源软件的作者们respect🫡)画了个草图以描述PCB/TCB的结构 ,其中intr_stack栈用来存储中断时任务的上下文,thread_stack原来存储在中断处理程序中任务切换时 (switch_to)的上下文。( ps: 看到11章的时候发现关于这部分P.509有更好的的图示)
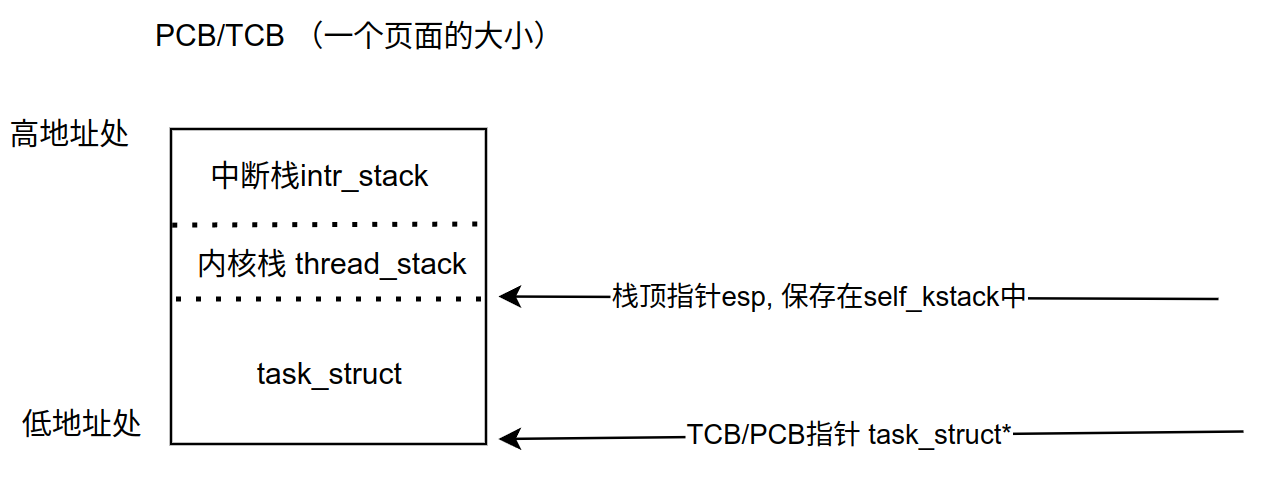
PCB和TCB这里没有各自单独定义,而是统一定义成task_struct, 其中包含pgdir成员用以表示进程的页表信息,所以当task_struct表示线程的时候,pgdir是置为NULL值的。因为PCB/TCB是严格按照页大小分配的,所以PCB/TCB的起始地址一定是0x*****000的形式,即低12位一定为0,基于这一点我们就能通过esp的高20位获取当前的线程的PCB起始地址,这也是函数running_thread实现的逻辑
线程被切出去之后,线程栈的地址即esp, 被保存在PCB的self_kstack成员中,该成员位于PCB结构体的开头,即第一个成员,所以可以用PCB的起始地址 (即running_thread的返回值) 作为self_kstack的地址。
下面好好说道说道switch_to函数栈的ret指令:
在switch_to函数中,完成PCB的切换之后, 在函数末尾执行ret指令的时候,会把当前线程的内核栈(即thread_stack)的栈顶元素填入eip (见P.85 )。如果这个线程是首次执行,那么栈顶的值就是线程对应的函数kernel_thread。该函数实际上调用了我们在thread_state中传入的参数function。为什么它在栈顶?这是我们在thread_create函数中初始化内核栈时设计的:

于是cpu接着就开始执行这个函数,也就意味着CPU转到新的线程开始执行。如果线程不是首次执行,那么栈顶的值就是函数schedule (该函数调用的switch_to,当然它的返回地址就在栈顶) 的返回地址,ret指令之后回返回schedule,schedule再返回到时钟中断的处理函数intr_timer_handler (schedule的主调函数),接着再从这个中断函数中退出,回到kernel.S的intr_exit (intr_time_handler的主调函数),在Intr_exit中完全退出中断并完成线程的寄存器环境的恢复。(写完这部分才发现刚哥在P.434中说了同样的话,不过没事, 我自己分析出来也不错🧐)
别的就不多说了,这一章确实比较杂,如果不把代码整体拉出来分析,是看不出怎么实现的。我建议看到这章的看官,先快速过一遍,把代码组合起来,再跟着代码的逻辑看懂实现过程。
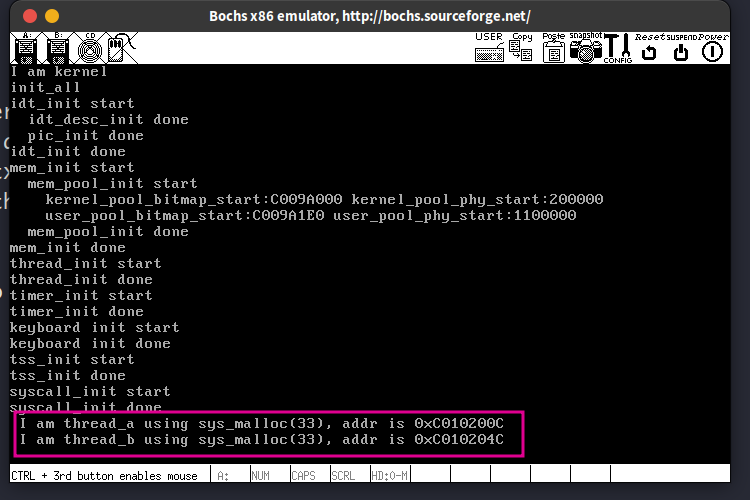
线程的创建部分的运行结果:
线程a创建并运行成功,此时还没实现调度机制,因此线程a不停的运行
任务调度机制部分的运行结果:
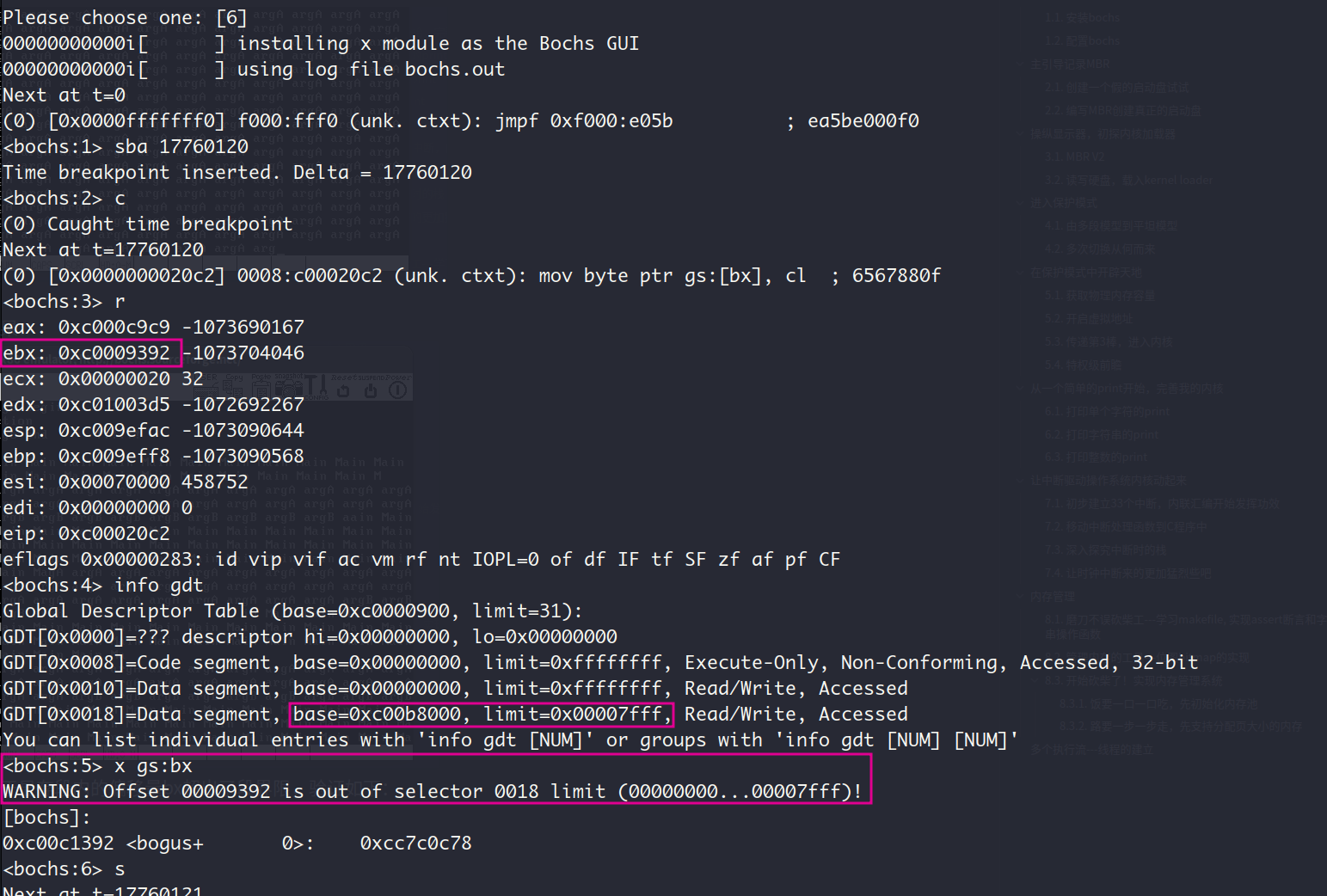
我给主线程main,线程a和线程b的优先级分别设置的是:36, 32 , 4,即9:8:1。 下面的显示的比例也差不多是这个值, 打印的值有空格且有的值不完整,这是因为线程的put_str还没执行完就被调度,以及多个线程在没有锁的情况下访问公共资源—光标寄存器导致的,下一章将解决这个问题
这里我遇到了一件奇怪的事情,就是如果我把main的优先级改为32,即跟线程a一样的值的时候,运行结果会变成下面这个样子
目前不是很清楚为什么打印的语句变少了,GP中断似乎也没有被提前触发了,下一章锁机制学完了再回来看看。
把主线程main和线程a的priority换成跟书上一样的31, 输出就符合了
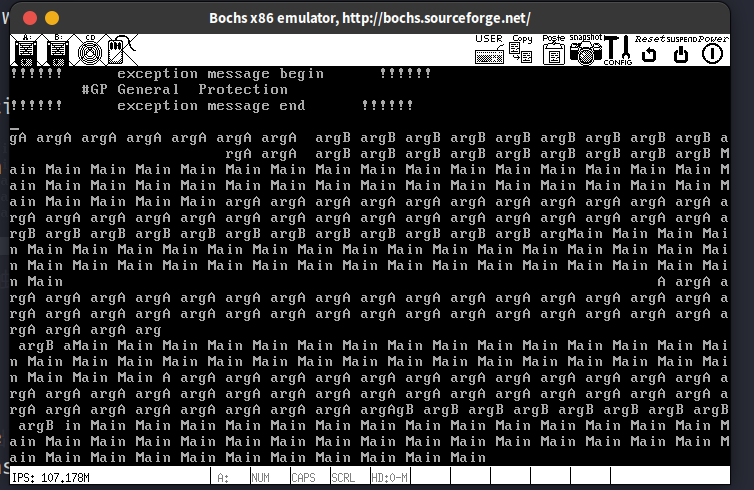
运行结果的顶部显示的一般保护性中断是由于显存段内的偏移量bx超出了段界限,验证如下:
10. 让终端不再静态,建立输入输出系统
10.1. 引入锁机制,修复破碎的终端
上一节中破碎的终端主要源自于多个线程对公共资源—显卡和光标寄存器的访问冲突了,解决这个问题的办法就是给终端上锁,上锁啥意思?就是一个线程进入临界区的时候,意味着它要访问某个公共资源了,它把门锁上,其他线程看见门锁了,就把自发的把状态转为blocked并加入等待队列waiter中。等进去的线程出来的时候,就会把锁打开,其他线程(在等待队列writer中的线程)就可以进去了。
信号量和锁是什么联系?我觉得吧,信号量拿来就是实现锁的。在我们的实现中,锁是封装了信号量的,锁的结构体中除了信号量,还有表示锁的当前持有者的信息holder。所以锁是包含信号量的,锁机制的实现是靠信号量实现的。
当我们把终端视为一个公共资源console的时候,把对它的操作都用锁机制限制起来,即每个线程要操作终端的时候都得看看通往终端的大门上有没有上锁,如果有锁,就说明正有线程在里面挥斥方遒呢,得自个先在门口(等待队列writer)等着。
运行结果:
10.2. 让字符处理函数支配键盘输入
这一节完成外部设备—键盘的中断处理函数,即标题中的字符处理函数,键盘把用户按下的按键的通码和断码传递到键盘控制器(8024芯片)的寄存器中,然后处理器去读取这个字符,怎么处理这个字符完全取决于字符处理函数的具体实现。
对所有按键都只是简单的打印k:
按下单个字符打印2个k,因为按下和弹起分别发送了通码和断码
按下右alt打印4个k,因为键盘控制器的寄存器是8位寄存器,处理器一次只能读取一个字节,而右alt的通码和断码分别是2个字节
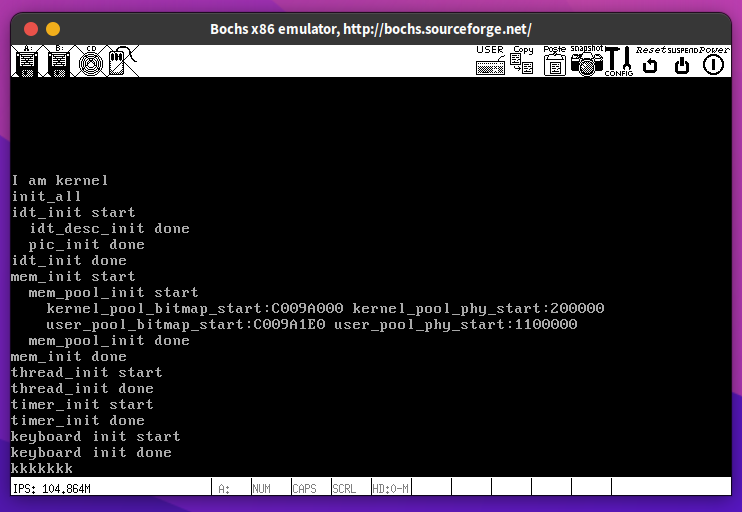
打印字符的字符编码:
按下字符k, 打印了25A5, 这与字符k对应的通码和断码相符合。 这里为什么是A而不是小写a呢,因为在put_int的实现中,十六进制中出现的A~F用的是大写
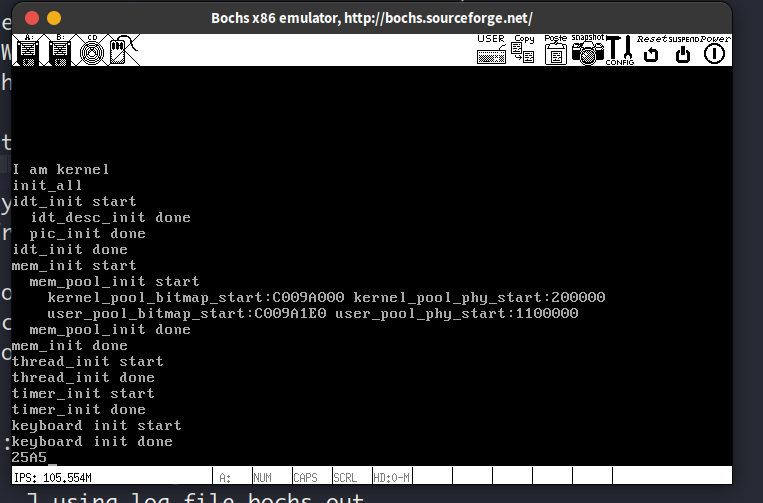
10.3. 更完善的字符处理函数—键盘驱动程序
这一节我们要实现所见即所得的键盘输入了,难点在于处理shift, alt, ctrl, caps-lock等控制字符,当按下这些控制字符的时候,按键对应的ascii码是不一样的,比如1会变成!, a会变成A
因为键盘驱动程序从键盘控制器的8位寄存器中读取的是按键的编码 (通码/编码),要想用put_char打印字符,得先把这个字符编码转换为ASCII码,做法是把通码当作二维数组keymap的索引,keymap中的每一个元素都是一个表示按键本身的ASCII值和shift之后该按键对应的ASCII值的一维数组。
难点在于如何处理shift和cap_locks之间的关系,这里采取的做法是统一用一个bool变量shift来表示接下来的按键是采用一维数组中的第0个元素还是第1个元素,控制按键shift和cap_locks对驱动程序的影响就体现在这个shift变量上,比如当这2个控制按键都按下去的时候,两者效果抵消,此时置布尔变量shift为0,打印第0个元素。
运行结果:
10.4. 管理输入的字符—建立环形输入缓冲区
之前我们键入的字符是直接用put_char写入显卡去了,现在我们要保留键入的信息到一个暂存地,并让其他线程来读取这个数据,这样我们就能通过键盘和线程交流交互啦。
这一节涉及到了一个经典的消费者和生产者的问题,要注意的一点是线程进入阻塞的那个条件判断语句,得用while语句而不是if语句,这和之前实现信号量机制的sema_down思想一致,就是让线程被唤醒之后,立马再次进入条件判断,原因很简单,就是线程被唤醒之后,并不是立马就调度到它执行的,可能在它之前,它所要求的资源又被其他线程给拿走了,哈哈哈,可怜的线程,因此这个被唤醒的线程不能想当然的就以为自己被唤醒了那么资源就一定在那,得再判断一句才是🥳。
既然是环形缓冲区,怎么判断它是空的还是满的呢? 首先,缓冲区为空的时候,也就是ioq_init刚执行完的时候,此时head和tail都指向第一个位置,所以似乎判断head==tail就可以知道是不是空的。但是!如果我们塞满缓冲区,此时head回绕加1之后指向下一个可写入的位置,那它将不得不跟tail一样指向第一个元素,也就是说head和tail此时也满足head==tail的关系,在这种情况下,我们将不能简单的通过head==tail来判断缓冲区是满的还是空的,这跟我之前学数据结构实现环形链表遇见的问题一样。 因此,我们妥协一下,在缓冲区中留出最后一个位置,这样当head指向tail的前一个元素的时候(即return next_pos(ioq->head) == ioq->tail),就认为缓冲区满了,不再写入了
只有生成者的运行结果:
缓冲区大小为63, 写满之后在调用消费者之前生成着将无法继续写入,所以屏幕上最多显示63个字符,之后无论怎么按都不会再输出字符:
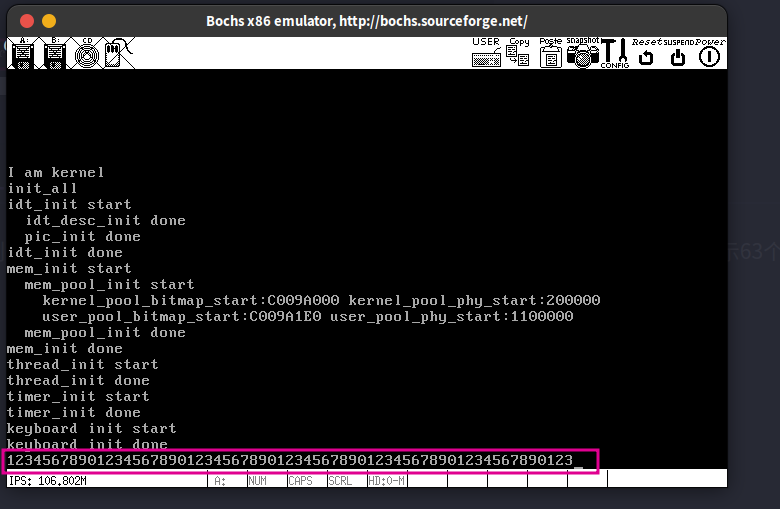
添加了2个线程(a和b)作为消费者读取环形缓冲区中的数据,运行结果:
初始时缓冲区为空,按住k键往环形缓冲区中写入字符k,消费者a和b轮流从中读取出字符k并打印,因为在函数ioq_getchar (消费者取出数据)和函数ioq_putchar(生产者写入数据)的实现中,确保了是在关中断的进行的原子操作,因此不会造成多个线程对缓冲区的访问冲突。不仅如此,在添加数据和取出数据时用了ioq_is_full和ioq_is_empty作为前提条件,避免了对缓冲区的越界访问

11. task的另一块拼图—用户进程的实现
11.1. 不得不用的TSS
刚哥已经反复强调过,一个完整的进程(即一个任务task),不仅包括我们自己编写的用户应用程序,还包括底层的操作系统内核,P.197的图5-18就很好的阐述了这个事实。因此我们的用户进程运行期间只要涉及到操作系统提供的服务,那么它就得进入内核。一如你需要洗车店的服务你就得进入洗车店一样。然后呢,因为内核态程序的栈与用户态程序的栈不一样,所以CPU在用户陷入内核的时候就得把ss:esp切换,使其指向内核态下的栈。这个内核栈的地址在哪呢?就在任务的tss中。
为什么我取得标题是不得不用呢?因为linux是不太想用tss的,因为用这玩意实现任务切换很慢,但cpu获取内核栈这个过程还是得依靠tss, 所以我们还是得让操作系统初始化好tss,具体是指初始化好tss中的esp0和ss0字段。所有任务共享这一个tss, 切换任务时得更新这个tss中的esp0和ss0
这节多少有点繁琐,得照着P.151的GDT描述符格式,几乎是一个bit一个bit的写好描述符的属性🙃。
运行结果:
查看gdt表,已经成功建立好了tss段,用户代码段和用户数据段
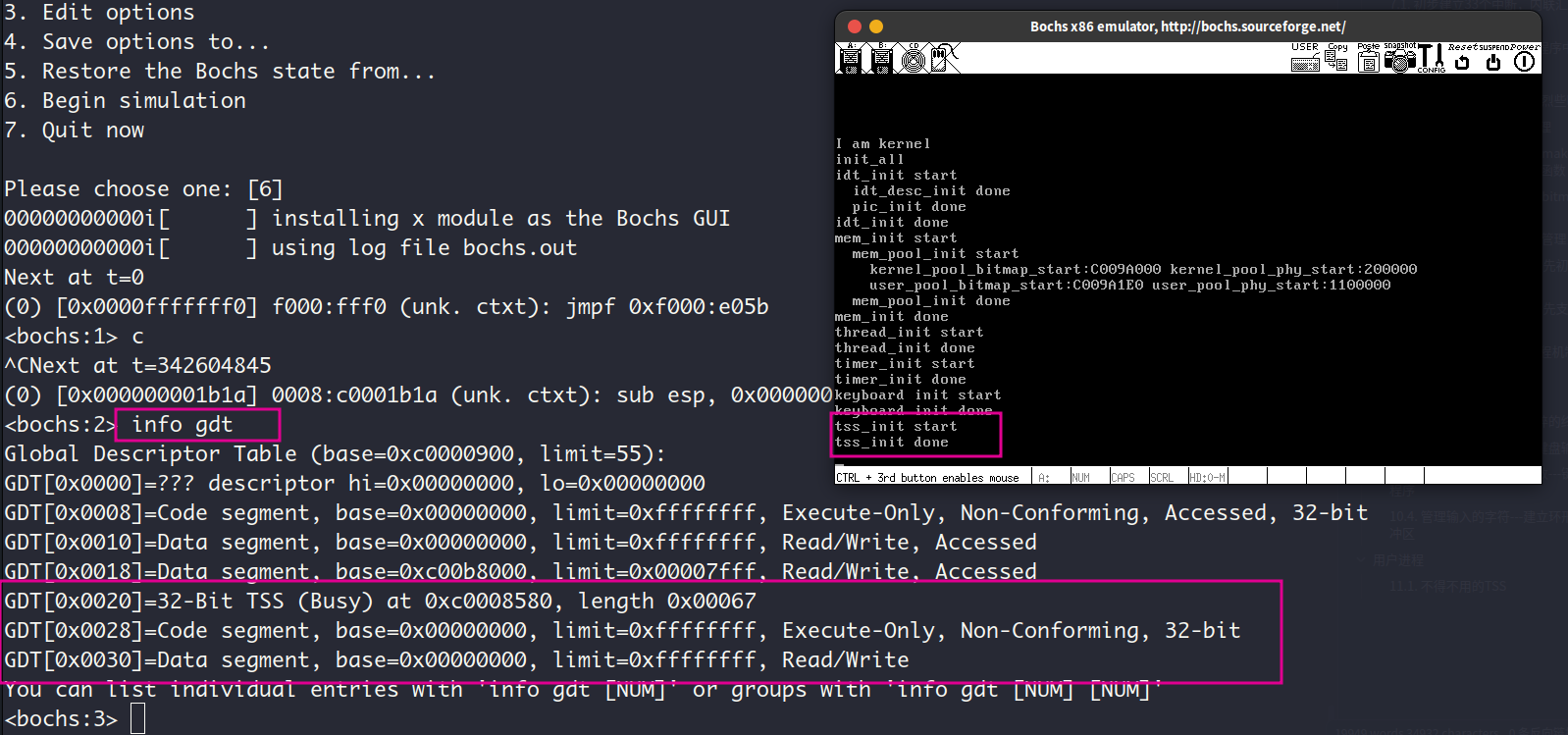
11.2. 特权级为3的用户进程
这一节花了我不少时间来完成,准确的来说是耽搁了不少时间。因为最近我的状态有些不好,前几天整夜整夜的睡不着,好像是有入睡障碍一样,主要原因还是自己多少有些焦虑,没学的东西还有点多,等着把这OS搓完了,就去把C++拾起来,做个C++的项目。这几天换了个记忆棉的人体工学枕头,稍微缓解了一下失眠。
用户进程的实现分为创建用户进程和执行用户进程,第一个核心问题是如何从当前正在运行的OS内核主进程跳转到用户进程执行。这是高特权级向低特权级的转移,要实现这种转移,只有一种办法,那就是通过中断返回,再具体点就是iret指令。我们要把用户进程的入口(具体实现中为start_process函数)作为中断程序的返回地址,就能实现这种转移。第二个核心问题就是,用户进程自己得有一套页表,从而实现进程间虚拟地址空间的分隔,还要有一套位图,这样它才能管理自己的内存。此外,实现用户进程还得给用户进程创建一个特权级为3的栈空间(栈底为0xc0000000),拿给用户态下执行的函数用。第三个核心问题就是如何让用户进程之间共享操作系统内核,做法是把操作系统内核所在的地址空间,映射到用户地址空间的高1GB中,相当于在用户进程中创建了一个通向内核的入口。
这一节踩了坑,花了5,6个的时间来debug,首先第一个错误是在内核的main函数中执行process_execute之后,会出现pagefault,通过之前设置的中断处理函数打印的提示信息,发现cr2寄存器中保存的触发pagefault的虚拟地址是0xf000ff57。我想不应该啊,怎么会访问到内核的这个高地址去。通过在main函数和prcess_execute中添加while(1)语句,发现process_execute能够完整的执行,但是却无法正确返回到main函数。找了很久都没找出原因, 最后对着代码一行一行的看,才发现在process_execute中把进程加入到all_list队列中的时候,加入的是进程的general_tag而不是all_tag,这会导致就绪队列中已经加入的general_tag被破坏,从而破坏了整个就绪队列。至于为什么这个错误会导致无法正确返回到main函数,还不是太清楚。

第二个错误发生在第一个错误修复之后,进程切换到第一个用户进程u_prog_a的时候,无法再切换到别的进程,导致内核主进程中的打印线程kthread_a和kthread_b无法执行,从下图可以看出,目标内存的变量的值已经被进程u_prog_a不断的增1了,但是屏幕没有反应,而且进程b对应的变量一直为0,也就是进程b完全没有得到执行。如下图:

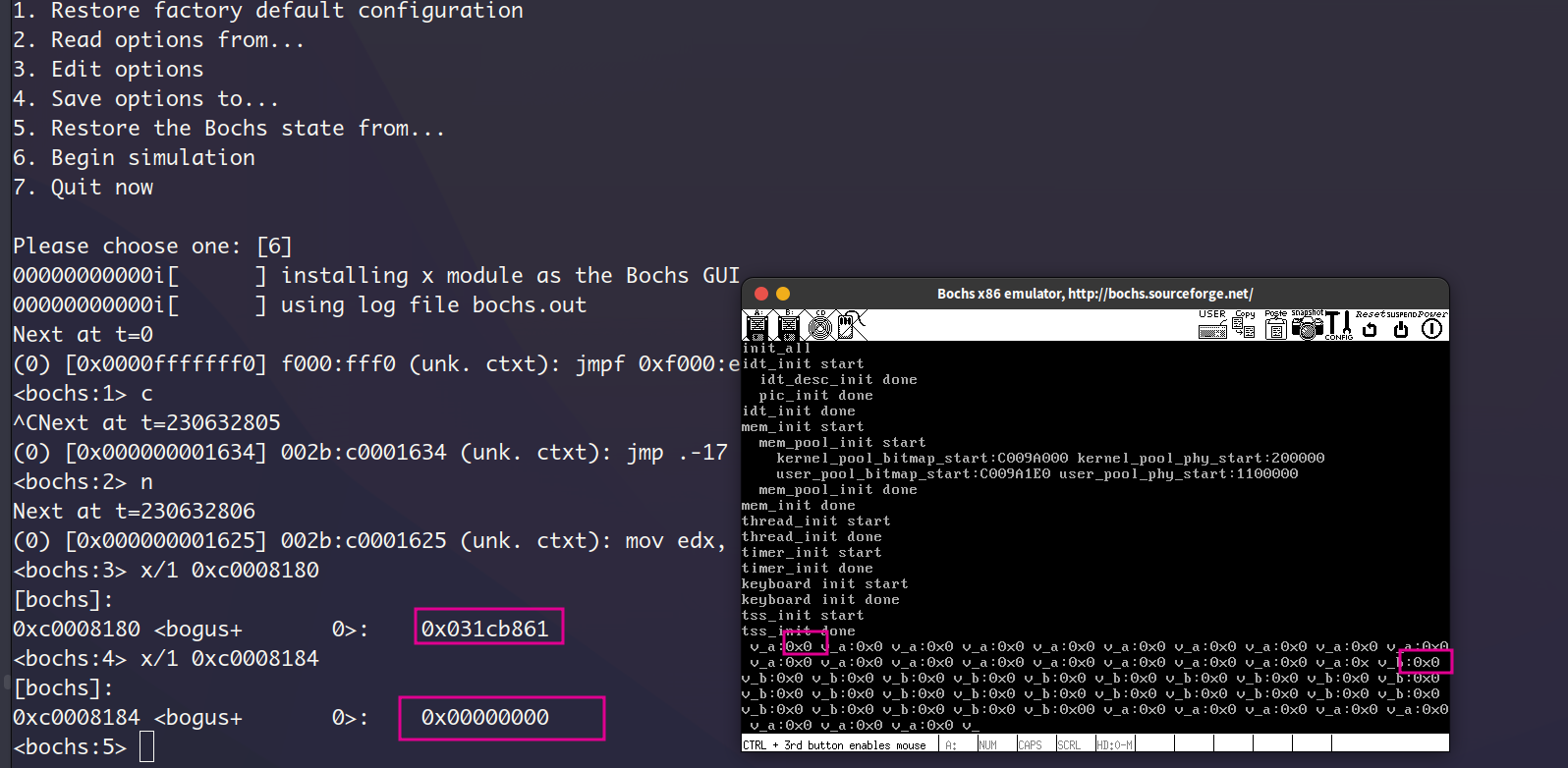
我也是调试了很久,把用户进程的建立和执行翻了个底朝天,甚至还跑去复查了第一遍第8章写的线程切换的相关代码。这样下来之后我意识到,我的时钟中断跑哪去了?要是有时钟中断,并且正确执行了的话,进程a没道理会一直占据CPU。于是我用nm命令查看了内核elf文件的符号表,获取到符号u_prog_a的虚拟地址,

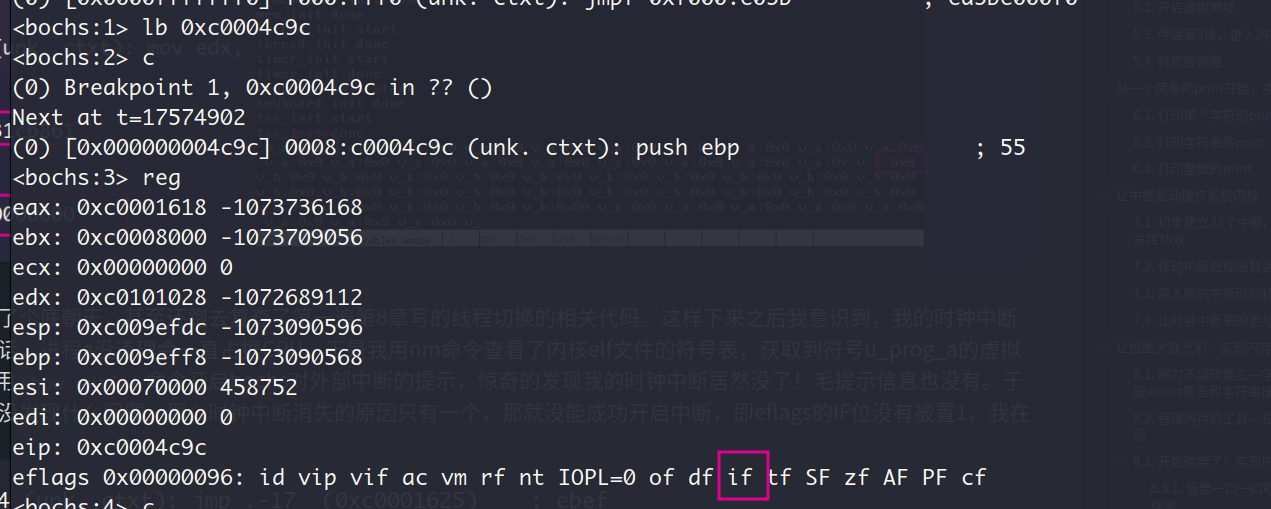
在bochs中设置此虚拟地址的断点,然后用show extint命令开启bochs对外部中断的提示,惊奇的发现我的时钟中断居然没了!毛提示信息也没有。于是乎,我又去复查了一边时钟中断的相关代码,没发现什么问题。那么时钟中断消失的原因只有一个,那就没能成功开启中断,即eflags的IF位没有被置1,我在bochs中一看,IF位果然为0!
我猜测这可能是intr_enable或intr_disable等调用没做好,于是去查了一下这些函数调用,没发现问题。最后我发现在start_process中初始化用户进程上下文中的eflags时,把或运算写成了与运算,导致eflags的IF位为0,所以才会有切换到用户进程的时候,标志寄存器从用户的上下文中恢复时,其IF位被置0
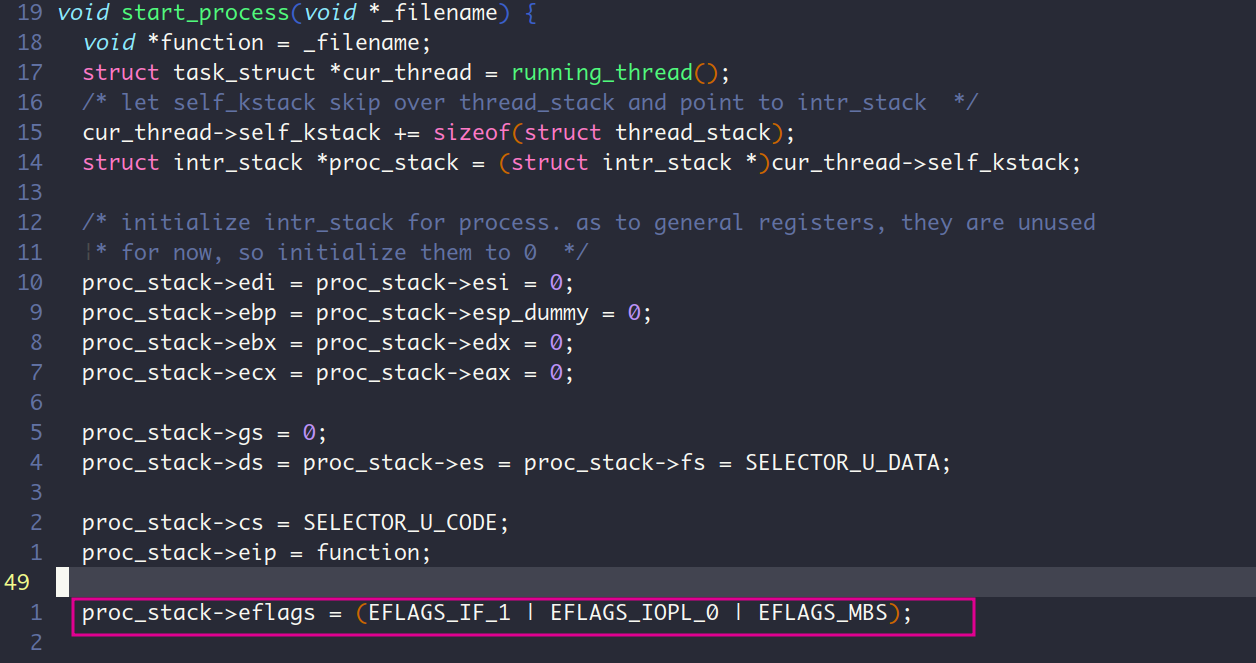
上面的坑,都是自己写代码的时候没能好好理清楚实现的逻辑进而自己想当然的写出来而造成的错误 。博主我是不爱直接对着书抄的,基本上都是理解完代码和机制之后才开始动手写,所以有时候会加入一些自己的想法而没去认真看书上的代码。踩这样的坑固然是有些“耽搁”的,但是不踩这样的坑,不犯这样的"笨"错误,我也不会去好好的把这几个文件翻来覆去的看,把机制彻底搞懂,也算是一个加深体会的过程吧。
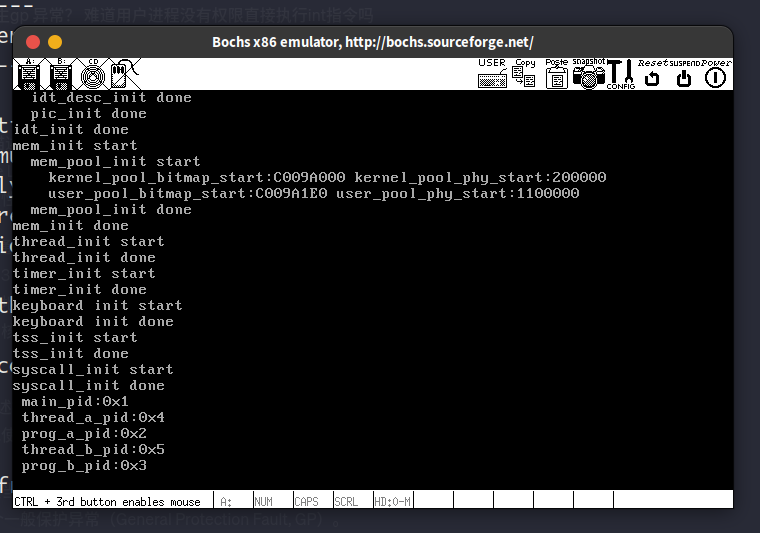
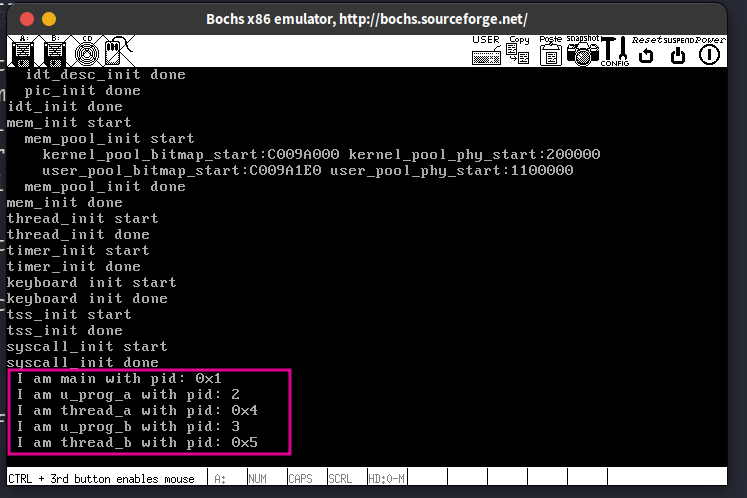
运行结果:
内核线程kthread_a和内核线程kthread_b不断的打印被用户进程递增的2个变量。
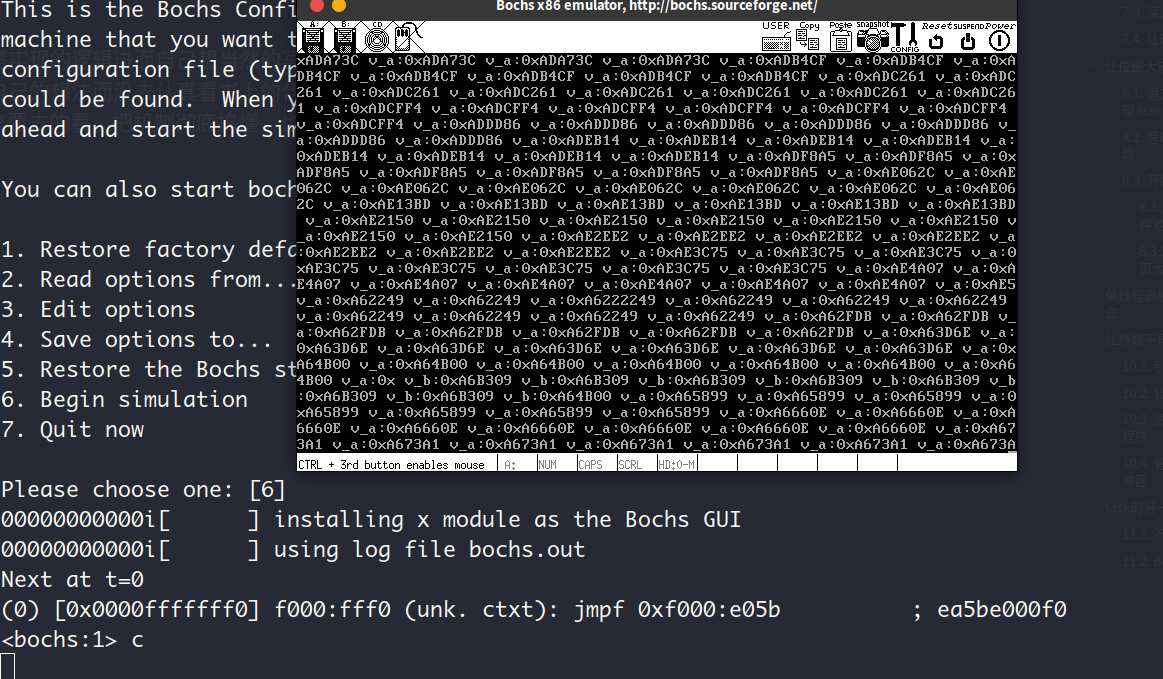
当调度到用户进程执行时,查看此时的选择子cs:
cs的值此时是0x002b,即0000_0010_1011,低2位为rpl位,表示的特权级为3,这说明当前确实执行在3特权级下。高13位表示GDT中的索引,值为5 (00101),正好索引到GDT中的用户代码段描述符
12. 进一步完善我的内核
12.1. 用户进程找操作系统办事—系统调用的实现
用户进程找操作系统办事,那么执行流程就得转到内核态的操作系统执行,这样操作系统才能办事。这样陷入内核的方式就是类型为软中断的指令—int+8位立即数, 更具体点就是int 0x80指令。
我们提供给用户进程一个能让它陷入内核态的接口_syscall,这个syscall中封装了int 0x80指令。既然是软中断,我们得有相应的中断处理程序,所以咱们得为中断向量号0x80写一个对应的中断处理程序。这个处理程序做些什么呢?那就是把eax中保存的NUMBER,也就是子功能号当作索引,遍历一个系统调用处理程序的数组,叫做syscall_table,找到相应的系统调用处理函数sys_xxx,然后跳转到这个函数执行,这个时候操作系统才开始真正为用户办事了。
值得注意的一点是,为0x80号中断写好中断处理程序后, 还要在中断向量表中注册这个程序,也就是说添加描述符,这里的描述符的权限是用户级别的,也是说对应的中断处理程序的特权级为3, CPU在执行 int 指令时会检查当前特权级别(CPL)是否满足中断描述符的 DPL 要求,这样用户进程就可以通过 int 0x80 发起系统调用,而不需要具备执行内核代码的权限。

运行结果:
12.2. 让用户进程说话—实现printf函数
有人看到这个标题可能会问,为啥还要实现printf函数?这不是C语言自带的吗?其实这个问题的答案跟我之前不理解还要另外自己定义bool类型一样,因为这些函数和类型是在C语言库里面的,而操作系统本身肯定是没法借助C语言库—外部库的,毕竟操作系统就是硬件之上的一层。而且从另一个角度看,C语言系统库不就是封装了操作系统接口的,便于用户调用的共享库嘛,比如C语言库里面的printf封装了操作系统提供的系统调用write,而我现在就是在搓操作系统,自然用不了封装了操作系统接口的C语言库
总之,我们的操作系统不能借助C语言库这种外部库,一切行为都得自己实现。
这一节值得额外讲讲的是那3个宏的实现,也就是下面这三个宏:

这3个宏实现了函数的可变参数机制,具体来说,函数中就是通过这3个宏函数来操作可变参数列表的。
va_list是类型char*的别名,而v在printf中传入的实参是format。format本身是一个类型为char*的指针,所以va_start就是让二级指针ap指向由v表示的一级指针format。因为按照C语言函数调用规定,参数是从右到左依次压入函数的栈中的,因此此时ap指向的就是位于刚好返回地址之上的format参数。而va_arg函数把ap向上移动4个字节,4个字节就32位计算机栈中一项的大小,因此va_arg就是让ap指向下一个栈中的参数,这个参数一定是可变参数列表中的参数。
刚哥在书上说va_start指向的是可变参数的第一个参数,我认为这个说法不太对,format是最后一个固定参数,如果要让va_start指向第一个可变参数,那么它应该是这样做才对:
#define va_start(ap, v) ap = (va_list)&v+sizeof(v);如果这样做,那么后续获取可变参数的时候,就先返回值,再递增ap指针,也就是要改变va_arg的实现了。
我们这里的va_arg是先递增ap,再返回值,因此也可以正确的获得可变参数列表中的值。
运行结果:
12.3. 完善堆内存管理
12.3.1. 更细粒度的内存分配
之前在第8章实现内存管理的时候,我们只是简单的以页作为分配单位,这一节要实现更细粒度的内存分配,实现malloc对应的系统调用处理函数sys_malloc。总共建立了7种大小内存块—16, 32, 64, 128, 256, 512, 1024。
P.548的图12-16已经把整个内存分配的数据结构讲的很清楚了。值得注意的一点就是,在实现sys_malloc时,用struct arena*类型声明的指针a接受了malloc_page的返回值,从本质上来说,a就是个存储了值为指针的普通变量,struct arena不过是告诉编译器,用*a取地址的时,取出struct arena大小的内容。所以用a来接受malloc_page返回的页的起始地址是没问题的。
这里采取的数据块分配策略是从低容量的内存块向上找,找到最接近目标大小的数据块进行分配,这玩意在教科书上应该叫最佳适配算法吧🧐?
运行结果:
12.3.2. 用好老朋友位图,实现内存的释放
无论是内存的分配还是释放,无非就是操作3个玩意,一是虚拟内存池的位图,二是物理内存池的位图,三是页表。要分配内存,那么就在位图上找个为0的位,把它置1,并建立虚拟地址和物理地址的联系。要释放内存,那么就去把之前置1的位变成0,再修改页表就完事了。
测试sys_free的运行结果:
运行了挺长时间的(可能有一分钟),我还以为我的逻辑有问题,又跑回去过了一遍,没发现什么问题, 最后运行的结果也是正确的,在每次循环中进行了多次内存分配和释放,这本身就是一个相当大的操作量。
malloc和free的测试结果:
在sys_malloc和sys_free上建立2个系统调用接口而已,很快就写好了。
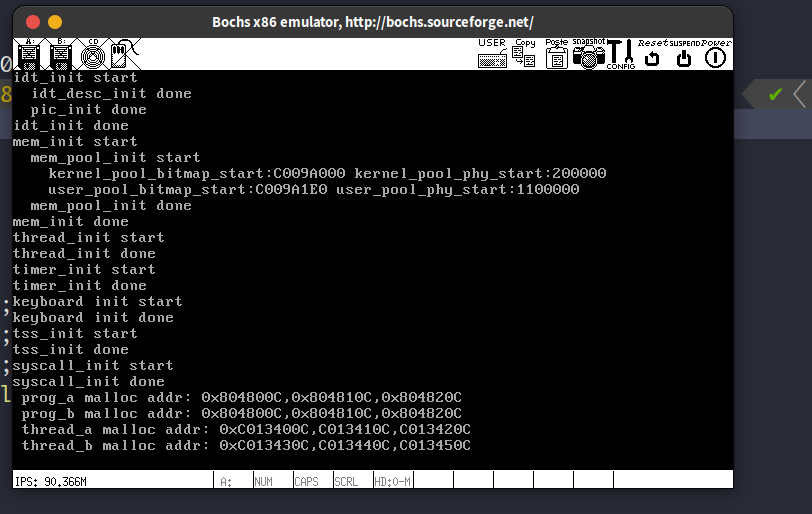
13. 硬盘驱动程序
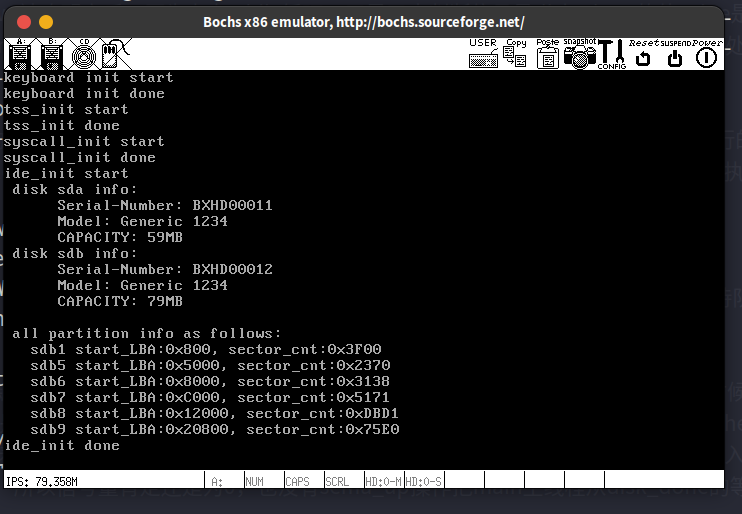
13.1. 给文件系统安个窝,创建一个从盘
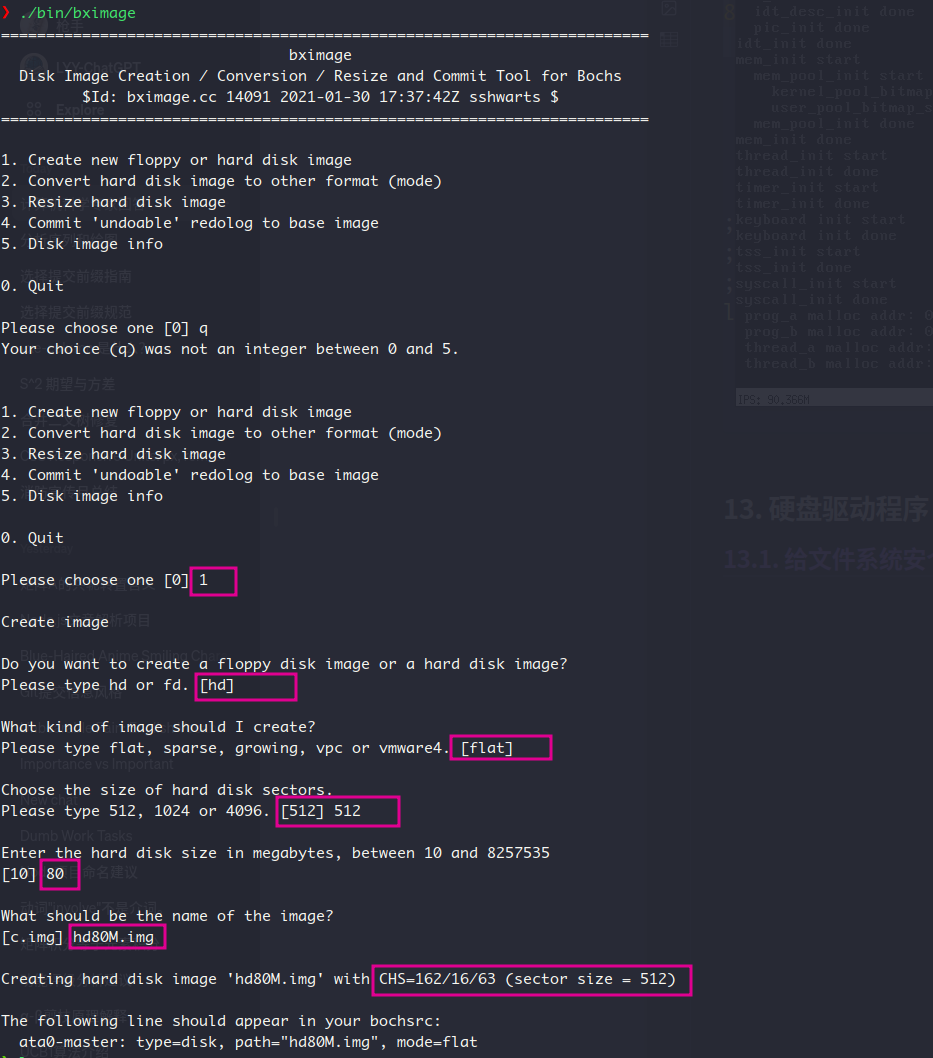
在配置文件bochsrc.disk中写入:

启动bochs,查看此时的磁盘数量

用fdisk创建分区:
- 设置柱面数和磁头数
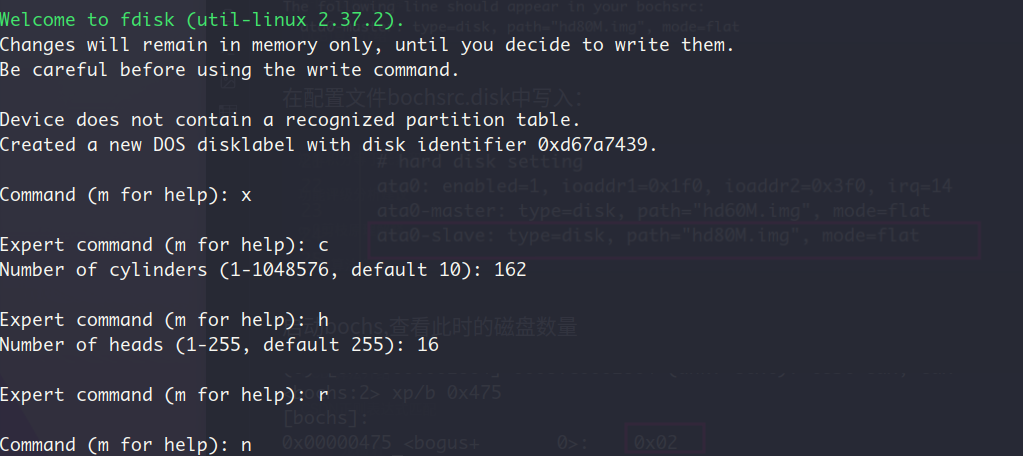
- 建立主分区,扩展分区,扩展分区中的逻辑分区
这部分的fdisk流程跟书上的不一样,估计是bochs版本的原因。书上是设置起始和终止的柱面数,而我这是设置起始和终止的扇区号(sector),但本质上来说,就是在填充分区表中的描述符嘛,描述符指定了这些分区的起止界限,只不过单位从柱面变成扇区号了而已。在网上试着找了下前人关于这部分的内容,填了下面的值:

用t命令设置分区id之后(设置了一个不存在于已知文件系统id集合的值,因此显示unknown。分区id表示文件系统类型,也就是说这些分区上的文件类型是未知的):
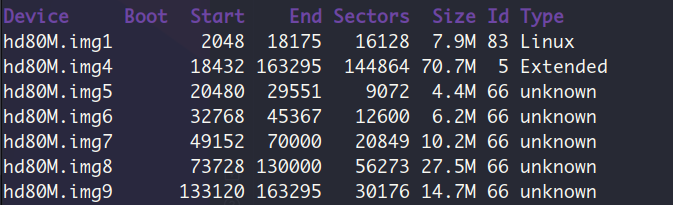
- 列出分区表
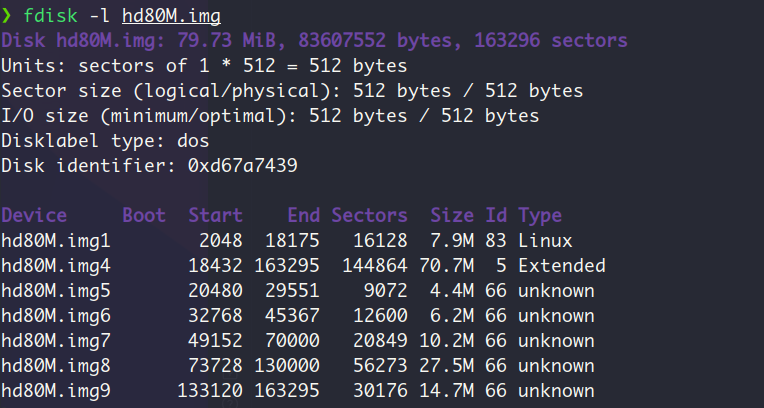
分区后的硬盘大小:

强烈建议:把创建好的盘弄个备份,后续建立文件系统的时候会很需要有一块只划分了分区的磁盘来验证结果。
13.2. 磁盘与分区
硬盘分区是指将硬盘的存储空间分割成独立部分的过程。每个分区表现为一个独立的“区域”,可以单独进行格式化和管理。在操作系统眼中,每个分区都像是一个独立的硬盘。
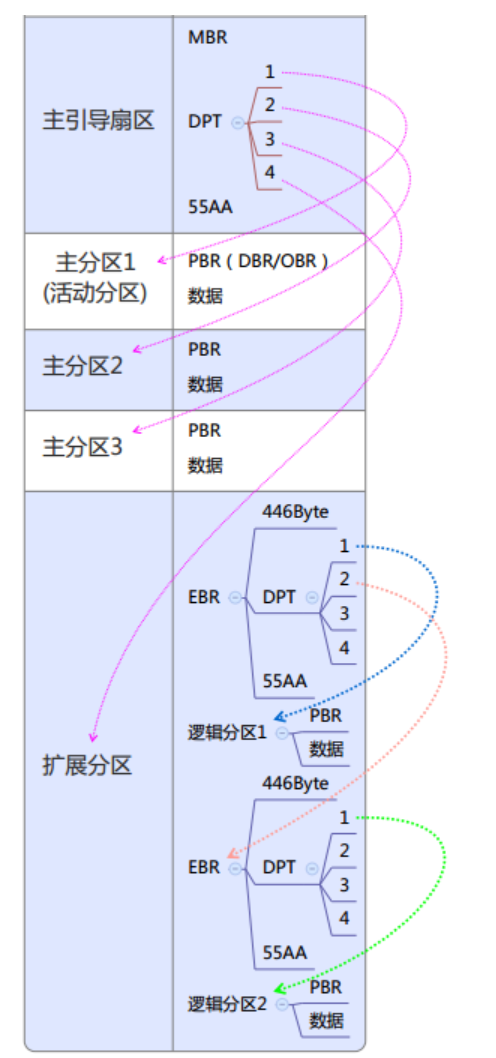
主分区:最多可有 4 个。这些是最基本的分区类型,可以直接包含文件系统。
扩展分区:最多只能有 1 个,用于绕过 4 个主分区的限制。扩展分区本身不包含文件系统,而是包含多个逻辑分区。
逻辑分区:存在于扩展分区内,数量可以超过 4 个。它们在扩展分区的框架内表现得就像主分区。
网上找了张图,我觉得说的很清楚(PBR改名为OBR更合适):
总扩展分区被拆为多个子扩展分区, 子扩展分区又被拆为EBR引导扇区+空闲扇区+逻辑分区, 逻辑分区中有包含OBR引导扇区,也就是操作系统引导记录, 也即操作系统内核加载器
13.3. 抽丝剥茧,深入探究硬盘驱动程序
这一节真的花了我接近一天来debug, 不过也还好, 正好借着我遇到的这个问题, 把硬盘驱动程序的实现细节理清楚了一遍。
我遇见的问题是,在identify_task函数获取第2块硬盘(即slave disk)的信息的时候,sema_down函数会抛出当前进程已在就绪队列中的错误。我加入了几条printk语句以获取更多信息
运行结果如下:
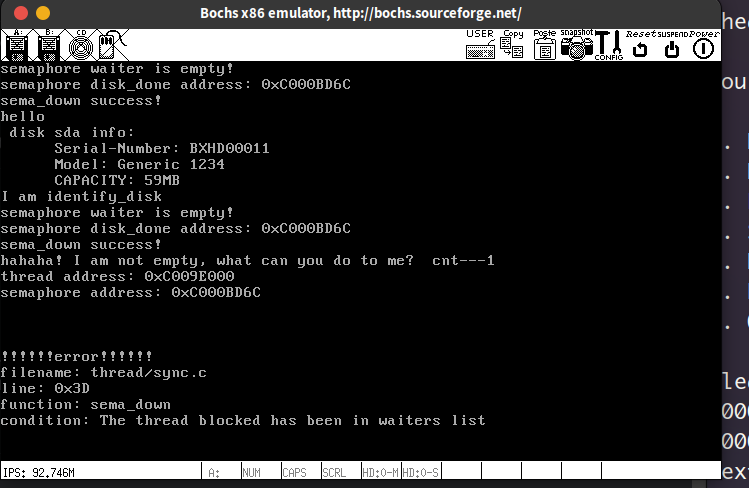
输出有些乱,各位看官也没必要看懂上面的输出,总之通过这几条printk语句的执行结果我可以得出的信息就是:第一次identify_task是完美执行的,在ide_init中第二次调用identify_task的时候,进入sema_down函数之前,信号量hd->which_channl->disk_done的等待队列是为空的,说明identify_task函数本身是没问题的,问题一定是出在了sema_down函数内部。
于是我开始排查sema_down,根据sema_down中的printk语句运行结果可知,第二次idenfify_task函数进入sema_down的时候,首次执行是成功的,也就是说,是成功调用了thread_block阻塞了当前进程的 (其实问题的根源就是在这里假阻塞了)。因为此时在内核初始化init_all过程中,所以还没有开启用户进程和其他线程,因此此时执行环境中只有一个内核main进程和能够让CPU挂起的idle线程。
于是我就开始对进程/线程的切换抽丝剥茧。一步一步的看,当main进程在sema_down中用thread_block函数阻塞自己之后,thread_block函数会把main进程的状态设置会TASK_BLOCKED,然后调用schedule函数

在schedule函数中,存在这样一条语句:

要理解这条语句,那么我要好好说道说道idle线程。这个线程的实现如下:
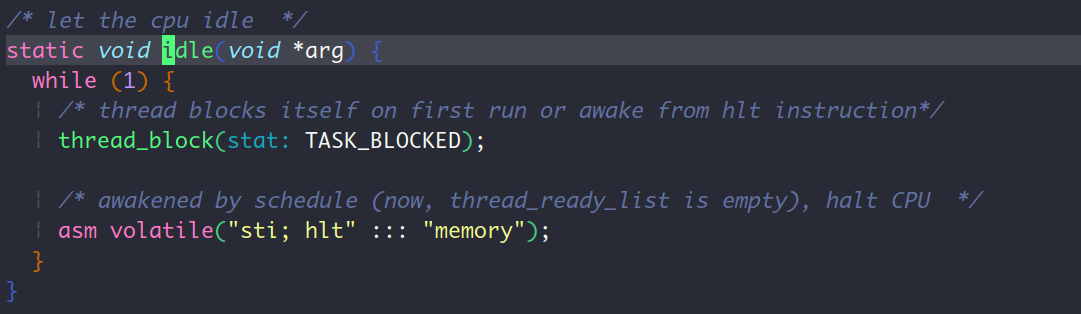
并且该线程在内核刚启动的时候就在thread_init函数中随着内核main主线程的建立而建立。因此在第一次调用identify_task,接着执行到schedule函数的时候,此时thread_ready_list并不为空,此时里面还有一个刚建立的idle线程,因此就pop出来执行。那么现在CPU就要执行idle线程了,该线程先阻塞调用thread_block阻塞自己,接着就又要调用schdule函数,因为内核中的main主线程是调用的thread_block主动阻塞的自己,所以main主线程此时不在thread_ready_list里面,因此上面的这个if语句(if(list_empty(&thread_ready_list)))就成立了,此时就应该对idle线程执行thread_unblock。也就是说,首次执行idle线程的时候,它自己阻塞了自己,结果马上又回到自己了(注意我的论述的前提是,此时的执行环境下只有内核main主线程和idle线程),于是idle线程再次开始执行,halt CPU。既然hlt指令在遇到外部中断的时候会继续执行,那么当时钟中断来临的时候 (并且idle时间片到期),又要切换idle线程了,但是!现在的thread_ready_list还是空,所以又调度到idle线程,接着就是thread_block schedule队列为空调度回idle执行hlt指令,这样不断的循环,直到产生磁盘中断。
当然啦,上面所说的发生在只有内核main主线程和idle线程的情况下。此时可能有其他进程/线程存在吗? 不可能,因为ide_init存在在init_all中被调用,这属于内核初始化的一个过程,因此不存在其他的进程/线程(进程就是线程+资源,既然我强调的是执行序列,以后就叫线程了,省的多打字)。idle老哥的存在,是为了让CPU大哥休息休息,好在内核初始化之后投入到多线程的战斗中。
说了这么久的idle线程,那么它和sema_down函数有什么关系呢?是这样的,当磁盘中断来临的时候,CPU从hlt中苏醒过来,开始执行磁盘中断处理程序intr_hd_handler,
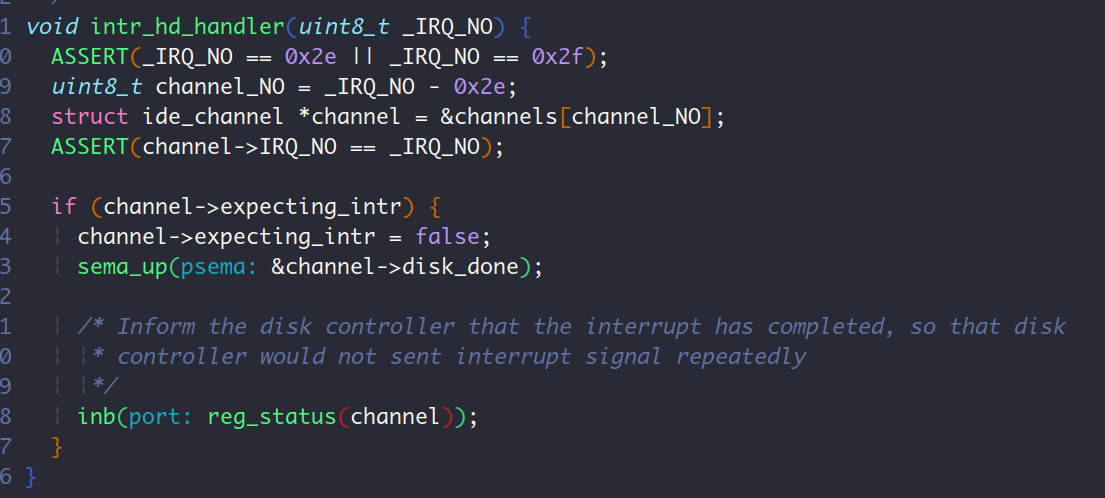
这个中断处理程序会调用sema_up函数,并在这个函数中把main主线程重新加入就绪队列thread_ready_list中。那么在下一次从idle中调度出来的时候,CPU就可以重新回到identify_task中的sema_down函数中继续执行。sema_down被唤醒之后,因为存在while循环,于是又去判断信号量disk_done的值value是否为0, 因为disk_done.value已经在中断处理函数中+1了,所以该判断为false, sema_down执行信号量值递减操作后退出。所以说,磁盘驱动程序是被磁盘中断处理程序唤醒的。
既然正常的流程搞清楚了,是时候看看上面的程序错在哪了。从printk的输出可以看出,在第二次调用identify_task进入sema_down的时候,首次执行的没问题的,因为打印了sema_down success的语句,此时内核main主线程被block,等待中断处理程序唤醒它。按正常流程走,此时CPU应该切换到idle线程执行去了。
然后挂起CPU等待外部中断,具体来说是等待磁盘中断来唤醒main进程。
问题一定是出在上面这个“按正常流程走”部分,CPU指定是没这么走,才会导致在内核main主线程被唤醒之后,信号量的值0,继续进入while,等待队列里面居然还有内核main主线程,于是进入if语句中,从而触发PANIC。
于是我一行代码一行代码的审查,甚至还去把老早就实现的list.c文件重新检查了一遍。 最终发现在schedule中,不是要添加一个if语句在队列为空的时候唤醒idle线程吗?我想当然的就在后面加了个else 😩,导致我schedule函数可以说是毛也没干,只是把idle线程加入了就绪队列,也没执行list_pop切换到它。schedule函数执行完thread_unblock后直接返回,这sema_down压根就没让main睡着,更别谈唤醒了,更没有等到磁盘中断处理程序把信号量加1,就接着立马进入sema_down函数的while语句了,因为此时磁盘中断处理程序都没执行,所以信号量肯定还是为0,也没有sema_up操作把main主线程从disk_done的等待队列中取出。
修改之后,去掉用的printk语句,运行程序,结果如下:
分区表中的内容正好对应了用fdisk工具为从盘hd80M.img划分分区之后,用fdisk -l hd80M.img查看分区输出的信息
顺便提一句busy_wait函数,这个函数被多次用到,目的是就是判断此时磁盘到底是不是可以操作的状态,如果不是,那么就是调用thread_yield交出CPU。按道理来说,磁盘发出中断(其实是磁盘控制器发出的中断),就说明此时磁盘已经准备好了,没必要在加个busy_wait。所以这里的busy_wait更多的是一种保险措施,具体来说,在busy_wait中判断磁盘控制器中的寄存器的位是否是预期的,这样加上一层保险。只要磁盘本身没什么大毛病,busy_wait都不会进入else分支(已添加printk语句验证过了)
这一章费了我不少精力啊,我以为能很快搞完然后马上搞文件系统呢,没想到还是花了很多时间,大概有3天呢。主要原因还是本身对磁盘不了解,这一章开头讲磁盘和分区的时候,MBR, EBR, OBR把我旋晕了快。而且也没写过什么驱动程序,现在看来,这些硬件驱动程序,无非就是把硬盘抽象为一个一个数据结构,比如我们定义在ide.h中的结构体。然后把对I/O端口的操作封装为一个个函数就完事了。
写到这里,从10.31号开始有第一次git提交起算,XUN-OS已经用了一个月的时间了,具体来说是34天,现在还剩文件系统和终端的实现。我所做的一切,是我热爱的,是我觉得有成就感的事情。这些事情对于我的目标,对于明年的愿望,肯定也是有好处的,但是我不愿意想太多未来的事情,这会令当下处于特殊阶段的我倍感焦虑,我所能做的,就是向着正确的方向 (心之所向),一个脚步一个脚步的走好,不在浮沙上建立高楼。总之,但行好事,莫问前程。
14. 创建文件系统
14.1. 站在磁盘驱动程序的肩膀上,建立超级块,inode, 目录项
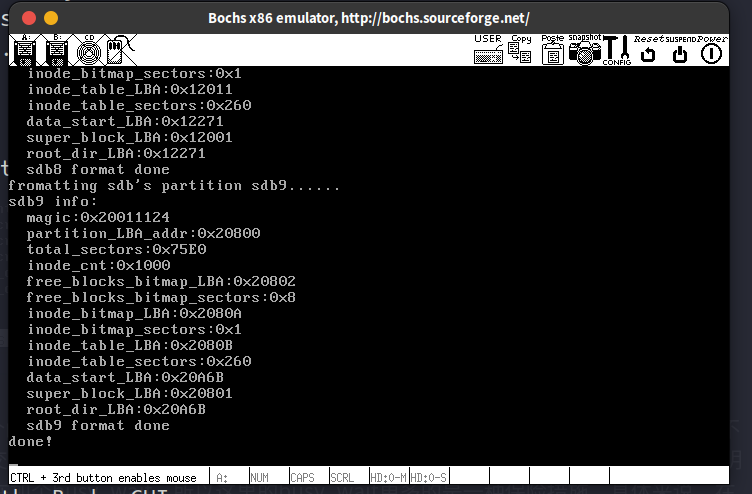
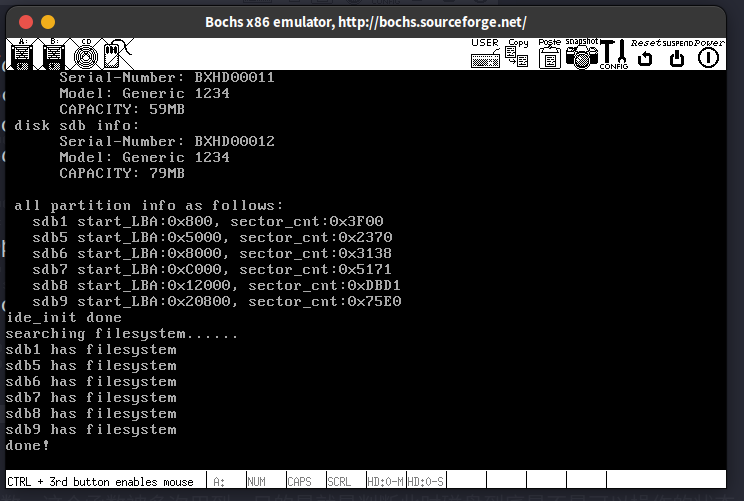
这一节呢是在分区上创建文件系统,是个怎么回事呢?本质上就是在每个分区(主分区+扩展分区中的逻辑分区)中建立好超级块,空闲块位图,inode位图和inode数组这4样东西就行了。怎么个建立法呢?就是先在filesys_init中遍历这几个分区(1个主分区,5个逻辑分区),检查看看有没有这4个玩意。没有的话就调用partition_format给分区中加这4样东西。既然要加进去,那么就是把内存里面的东西放到磁盘里面,上一节定义的ide_write在这就能发挥作用了。因为这4样东西还是挺大的,毕竟个个至少都要占有一个扇区的大小,所以先在程序中定义并初始化好这4个东西肯定是不行的,栈直接给你溢出PCB了。因此用的是堆空间,而且只用了一个buf缓冲区,用强制类型转换让这个缓冲区分别存储super_block, inode bitmap, inode table和目录项,存一个写一个,写完换下一个 QvQ 。
运行结果如下:
跟分区的实际情况对得上,说明程序正确
再次运行:
14.2. 挂载分区
本质上就是把磁盘分区上的文件系统的信息(超级块,inode位图,空闲块位图)读入到内存中,这样我们的操作系统就可以通过这些信息使用这个分区中的数据块。这里又是一个ide_read大显身手的场合
运行结果:
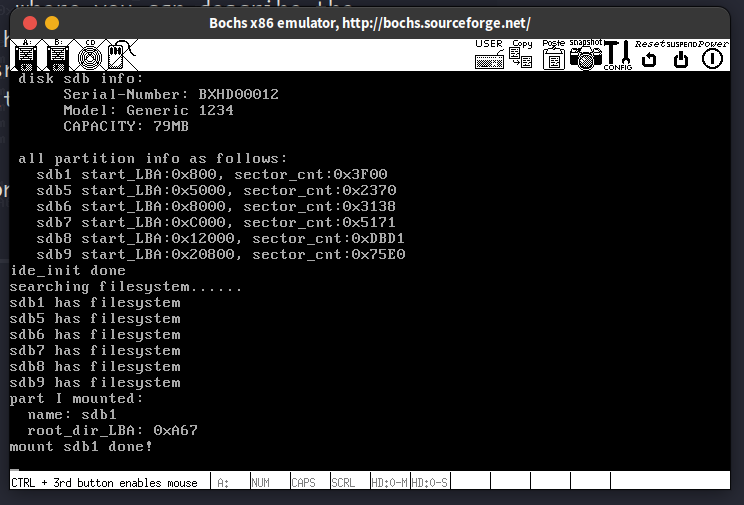
我在moun_partition函数中额外加入了2条printk语句用来获取当前挂载的分区的数据区起始扇区地址,也即根目录的起始扇区。这样做的原因呢,是方便用刚哥给的xxd.sh脚本插件检查硬盘hd80M.img的内容是否符合预期。
上面的输出显示挂载的是主盘sdb1, 起始扇区为0xA67,换算为起始字节地址为1363456,用xxd查看该地址处起始512字节的内容:

咱们目录项的定义是下面这个样子,其中filename占16个字节,enum 类型的f_type可以理解为int类型,占4个字节,所以一个目录项的大小是24个字节。
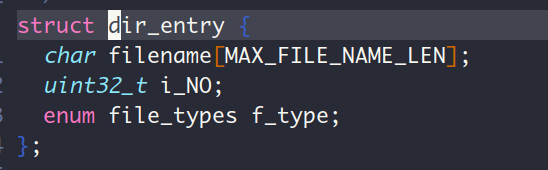
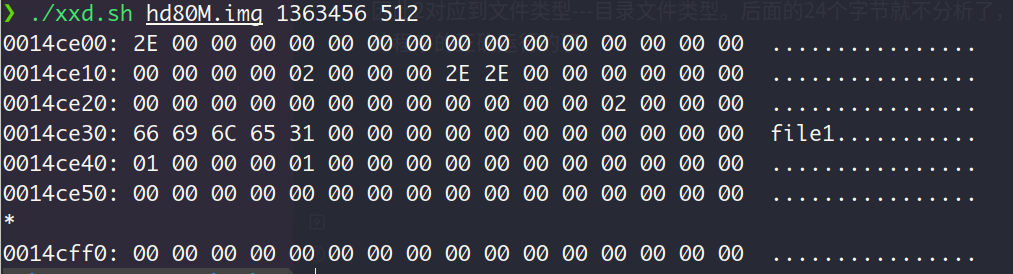
因此,我们看起始字节地址开始的48个字节,如果表示页目录项.和..,那么就对了, 这2个目录是在函数partition_format中为根目录创建的。那我们来验证一下:因为我的CPU是小端序列,那么打印的前16字节的值为0x0000…02E, 代表了第一个目录项的file_name。字符.的ASCII是2E, 因此filename为.,紧接着的8个字节分别表示根目录的inode编号,为0,和文件类型,值为2,文件类型定义在fs.h中,如下:

因此2对应到文件类型—目录文件类型。后面的24个字节就不分析了,一样的道理。可见,咱们的程序的正确运行的了。
14.3. 打开和创建文件,sys_open的实现
这一节的内容相当的多,我建议是把14.3,14.4和14.5一口气看完再说,不然14.3的函数你就不是很清楚有什么用。
基于sys_open的实现所要求的东西,我来理一理这些函数的组织形式。
要实现文件打开指定路径 (pathname)下的文件,首先得先找到文件吧,于是就有了file.c中的search_file函数。这个函数是怎么做到搜索的呢?答案是在pathname中顶层目录所代表的目录项中寻找次顶层目录的目录项 (别忘啦,目录文件中数据内容是目录项),找到了就更新顶层目录为次顶层目录。
举个例子,对于路径/home/elite-zx/build-OS-from-scratch,search_file函数先在根目录/下寻找文件名为home的目录项,哈哈哈,就是遍历目录项嘛,这正是dir.c中的函数search_dir_entry做的事情。在搜索过程中,既然要遍历当前顶层目录中目录项,咱们得把这顶层目录的数据块读入内存吧,嘿嘿,这就是dir_open做的事情,仔细想想,要读取一个文件的数据块,得先把这个文件的inode读进来吧,CPU得在inode中获取数据块的地址,于是就有了inode_open函数。要读入inode, 得知道inode在分区中的位置吧,咱们定义了一个结构体inode_postion来表示inode的位置,并通过调用inode_locate把inode位置信息填入到这个结构体中。所以光是打开对应的目录文件就有dir_openinode_openinode_locate这样的调用链。有打开就有关闭,不然把路径中每一层的目录文件都加载到内存,那也太多啦,于是就有了dir_close和inode_close。
sys_open可以在目标文件不存在的时候创建文件(仅限最后一个目录下不存在目标我文件,对中间目录不存在的情况不成立),所以咱们有一个创建文件的需求,这是由函数file_create做到的。创建文件,总的指定在哪个父目录下创建吧,于是file_create肯定有一个parent_dir参数。创建文件还需要什么呢?我想P.614的图14-16已经说的很清楚了。我们就按照这个图的指示来创建文件。
咱们创建文件的第一步是创建文件的inode, 这是每个文件必需的,由函数inode_bitmap_alloc和函数inode_init来完成。第二步是在父目录下创建一个目录项,不然CPU上哪找到我们的文件QVQ,这个需求是由函数sync_dir_entry和函数create_dir_entry来完成的。第三步是在全局文件表中创建一个目录,第4步是在进程内部的文件描述符表中创建一个目录,这2步的目的是让CPU能通过用户进程提供的文件描述符来找到对应的文件,分别由函数get_free_slot_in_global_FT和函数pcb_fd_install完成。
最后,咱们在内存中把从磁盘读取的分区数据修修改改的,必然得同步到磁盘,因此有了一堆磁盘同步的函数inode_sync, bitmap_sync。 函数的实现细节都在仓库的源码里啦,我注释写的还是蛮详细的。
首次运行结果:
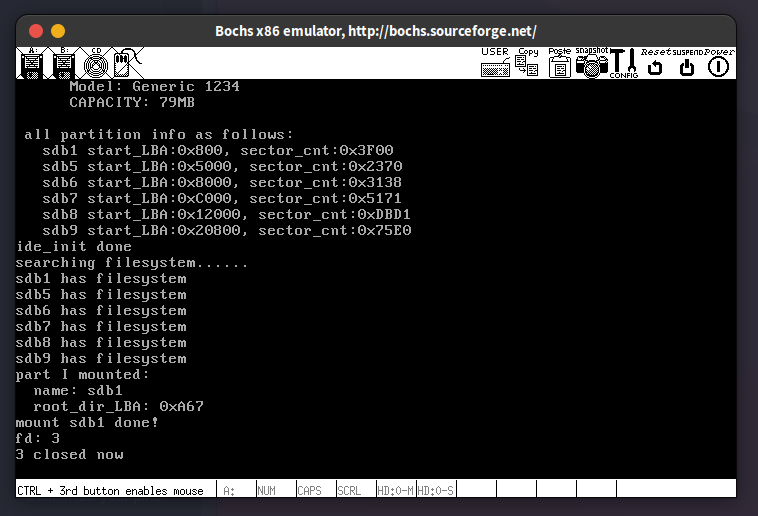
咱们在main函数中调用sys_open在根目录下创建了文件file1。查看挂载的主盘sdb1中的根目录的数据扇区内容,可见file1的目录项已经建立。
再次运行,显示文件已存在,符合预期🥳
14.4. 关闭文件,sys_close的实现
关闭文件,就是把打开文件所建立的访问链条(即 fd file table entry inode)一一关闭。具体来说,sys_close函数收到主调函数传来的文件描述符fd, 然后调用fd_local_2_global函数把fd转为全局文件表的下标global_fd,通过global_fd咱们就可以得到文件对应的inode了,调用inode_close去掉这个inode,并把global_fd对应的文件表项的fd_inode指针置为NULL,这样才能使得函数get_free_slot_in_global_FT认为这个global_fd有效,可以重新拿来用。
运行结果:
14.5. 写入文件,sys_write的实现
这一节2百行的函数file_write可真长啊,不过逻辑还算清晰易懂的。因为咱们是需要时再分配磁盘上的数据块,而不是一股脑的就塞给每个文件一堆数据块,因此在写入文件时,得看看现在文件拥有的数据块够不够你写的,不够的话还得再分配点数据块给文件。分配数据块也不是个简单的事情,还得考虑是分配是直接数据块还是间接数据块,如果是后者,那么得把一级间接块索引表读进来。sys_write中的核心函数file_write的大致思路就是先把可写入的数据块给确定了,放在all_blocks_addr这个数组里面,再开始写。写的时候还要注意因为咱们是以块为单位进行读写(ide_read和ide_write就是这么实现的),所以写入第一个数据块的时候不要把原来的数据给覆盖了,
运行结果:

下面来验证一下正确性:
从上面的输出结果可以看出,我又给mount_partition函数加了个printk😁, 打印inode_table的地址,因为咱得看看根目录文件和file1文件的inode是不是都写入正确的值了。
先看看file1此刻的内容吧:
确实是万物起源hello,world, 没问题。这个hello,world 应该是我学习计算机科学以来,难度和水平最高的一个了吧🤓

再执行一次试试:

再检查下inode_table:

上面这串数字是个啥呢? 听我慢慢道来:
咱们的inode结构定义如下:
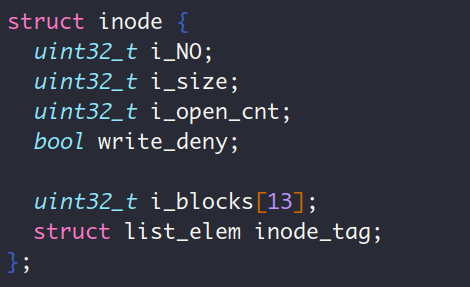
list_elem结构体中内含2个指针prev和next,这意味着一整个inode占用的大小为 个字节,因此上面xxd的输出中前76个字节是根目录的inode,与刚哥给的结果相同,刚哥已经分析过这部分了,那我就说说后面的第2个inode吧,第一个双字内容为1,说明该文件的编号是1,check✅。第2个双字内容为0x18,即24字节,因为该文件是普通文件(咱们在file_create给函数create_dir_entry传递是文件类型参数是FT_REGULAR,因为我们的sys_open不支持创建目录文件),所以这24个字节表示file1文件本身的大小,正好对应了2个hello,world\n的大小,check✅。再看第5个双字内容,为0xA68,表示i_blocks[0],与我们打印的地址相同 (此时空闲数据块中只分配出去了一个根目录占有的数据块和file1占有的数据块),check✅。按照file_write函数的逻辑,在首次写入文件时要先分配一个数据块:
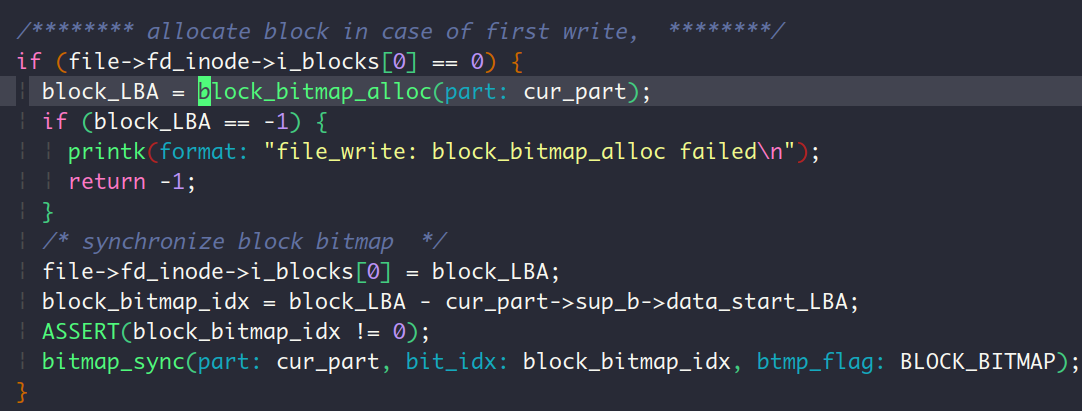
而且写入是hello,world远不足以写满这个数据块,因此此时file1文件只占有一个数据块,所以i_blocks[1~12]的值为0,check✅
在分析上面的内容的过程中,我算是切身体会到这个inode索引结构的好用了。要分配一个数据块,能在空闲块位图中找到一个空位就行了,然后返回该位对应的空闲数据块 (函数block_bitmap_alloc的实现逻辑),也不用管这个数据块与文件已有的数据块连不连续,充分利用了空闲数据块。在做到这一点的同时,还不用维护链表结构,没有链表结构本身的缺点,既能做到快速访问,而位图本身占有的空间还小的很,确实是精彩的设计。我相信做完这个操作系统,"纸上得来终觉浅,绝知此事要躬行"绝对会成为我学习要遵循的真理。
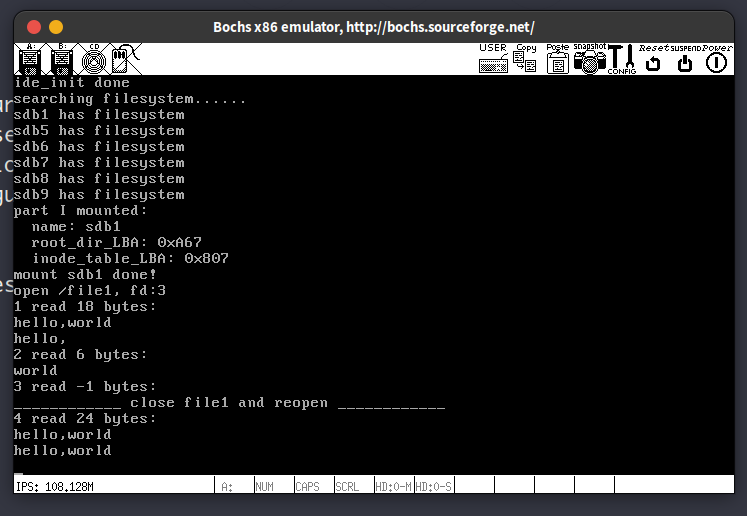
14.6. 读取文件,sys_read的实现
与sys_write的实现过程大差不差
14.7. 移动文件读写指针,sys_lseek的实现
本质上就是修改文件结构(struct file)中的fd_pos成员
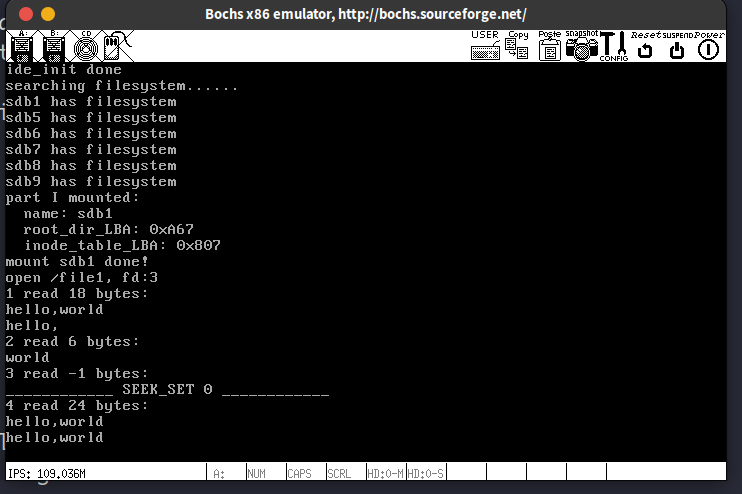
14.8. 删除文件,sys_unlink的实现
本质上就是去除/回收这几样东西:
- 文件占用的数据块和块位图中的位
- inode和inode位图中的位
- 父目录中的相关目录项
前2个由函数inode_release做到,第3个由函数delete_dir_entry完成
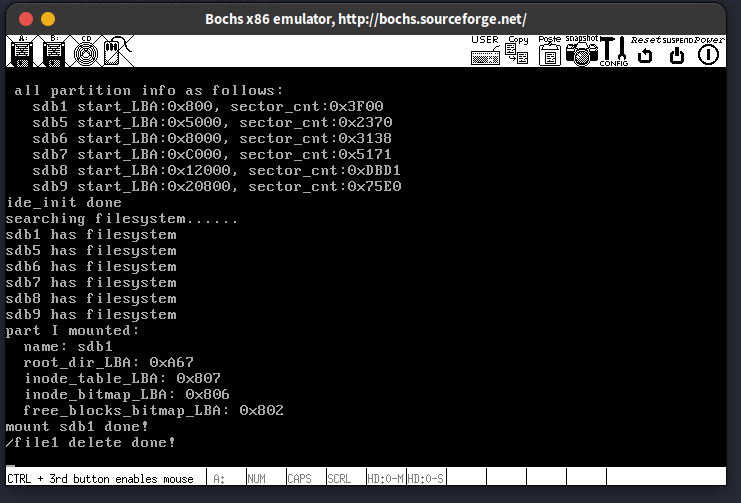
下面分别查看块位图,inode位图,inode表,根目录的内容:
- 块位图
仅分配出一个块,这个块是给根目录用的,符合预期

- inode位图
仅分配出一个inode, 说明咱们确实是把file1的inode给回收了

- inode表
/file1的inode被抹去,并且根目录的i_size更新为2个目录项大小,即0x30 (48个字节)

- 根目录
file1的目录项已被抹去,现在根目录中仅剩最初的.和..目录

14.9. 创建目录, sys_mkdir的实现
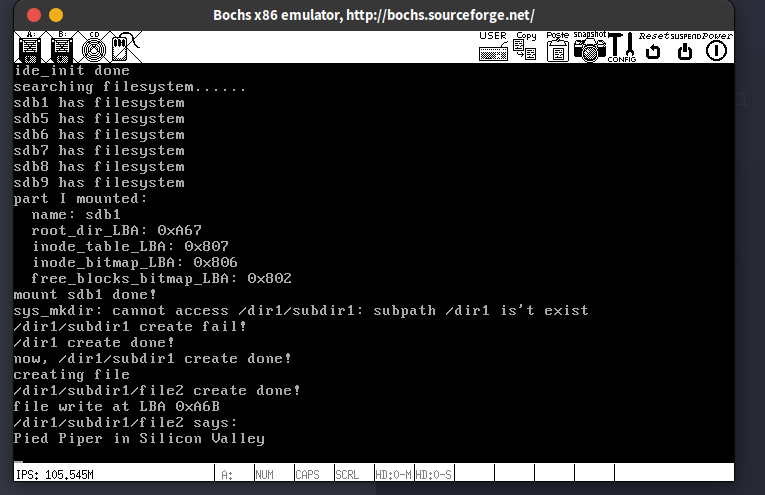
根目录:
dir1对应的在根目录中的目录项显示,dir1的inode编号为02,文件类型为FT_DIRECTORY (表现为值02)
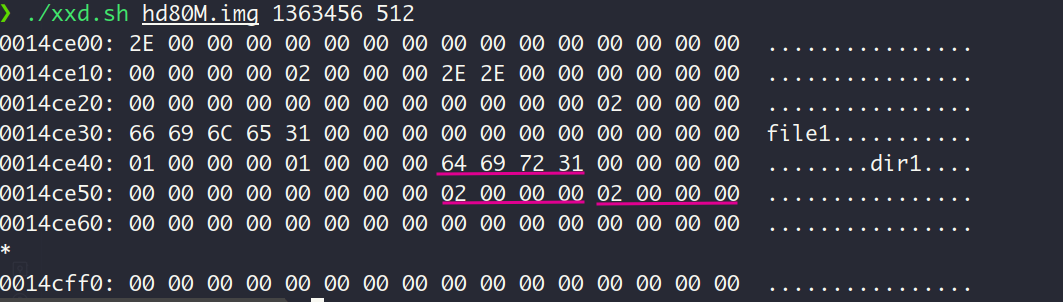
inode表:
根据一个inode占用76个字节大小这一信息 (咱们自个定义的),可以在inode表中找出4个inode,dir1的inode在第2个竖线处。该inode中i_blocks[0]的值为0xA69,说明了目录文件dir1的第一个数据块的LBA为0xA69,转换为字节地址就是1364480。
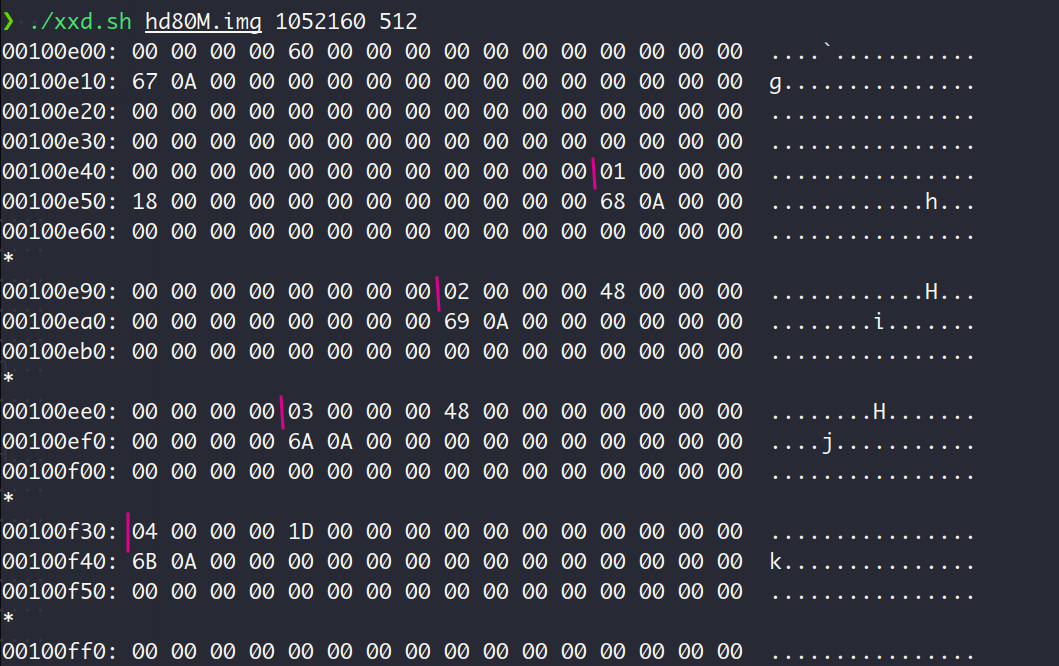
下面我们查看这个地址的内容:
可见目录文件dir1的数据块中存在3目录项:. , ..和subdir1 , 符合预期 QVQ。
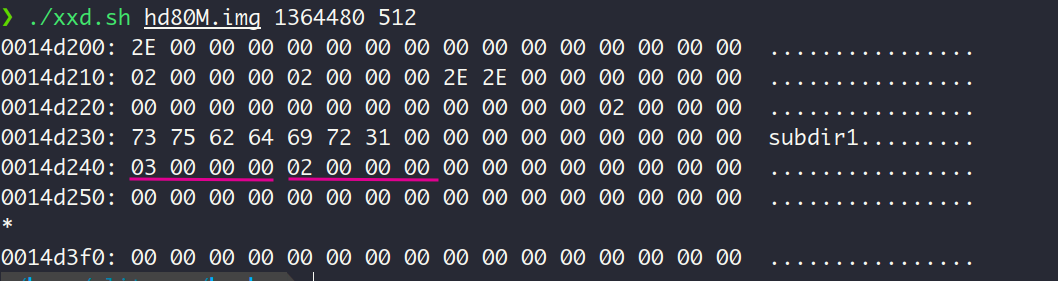
根据上图中subdir1目录项中的信息,可以得出该文件也为目录文件(FT_DIRECTORY,值为02),inode编号为03,从inode表中第3个inode中可以知道subdir1的第一个数据块的LBA为0xA6A, 换算为字节地址就是1364992。文件大小为0x48,也就是72个字节,正好对应了subdir1目录下的3个目录项:. , ..和file2
咱们查看subdir1的数据块的内容:
存在3个目录项,即. , ..和file2的目录项。

再根据inode表中的内容,查看file2的内容:
这里的字符串内容是向我最喜欢的美剧之一《硅谷》致敬 ^_^,话说最近OpenAi的董事会开除创始人CEO又马上重新应聘回来的行为真的是跟《硅谷》里面如出一辙啊🤨。

14.10. 打开和关闭目录,sys_opendir和sys_closedir的实现
14.11. 遍历目录,sys_readdir和sys_rewinddir的实现
14.12. 删除空目录,sys_rmdir的实现
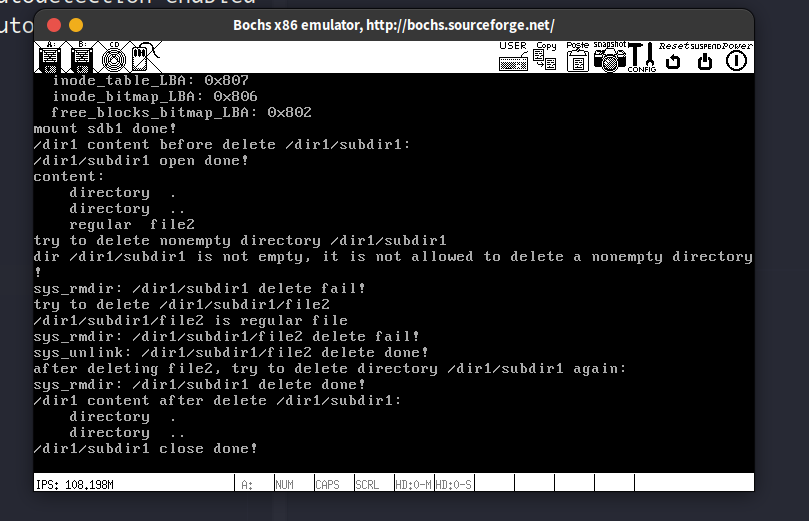
14.13. 目录项"…"展现锋芒, sys_getpwd与sys_chdir的实现
每个目录中存在的目录项..终于发挥了它的作用,咱们从当前目录,从下而上的顺藤摸瓜到根目录,就能获取到工作目录的路径啦。
14.14. 探索sys_stat函数,获取文件属性
文件系统的内容是出乎意料的多,我认为这一章起码顶之前3章的内容。本来我预计是12/10之前读完这本书并写完这个操作系统,但这个文件系统的内容确实太多了🙃,以至于12/10才把文件系统写完,现在还剩最后一章系统交互。从做这个操作系统到现在,每一行代码都是我自己写的,而且百分之99.99的代码我都是理解了的,只有函数和结构开头的注释是让GPT4帮我生成的。对于这本书,如果真的只是想赶个项目出来,而甘愿当而coper而不thinker,那么这个过程会是痛苦的,毕竟这是一本700多页的书和几千行代码。但如果当一名thinker,尽管要投入大量的时间,但也确实是能看见操作系统的“真象”的。
自从来到宁波,开始居家修炼起,我感觉是一天好觉也没睡过,那怕有的晚上确实很累了很困了,也会躺下去就开始焦虑,经常性的闭眼了1,2个小时还是清醒的。直到昨晚我实在受不了这种恶性循环了(晚上睡不着,早上又起不来),就直接干脆不睡了,起来把这个文件系统写完了,git log都显示我凌晨3点提交的commit。

但今天早上起来身体又浑身难受,我大概是受不了这种日夜颠倒的作息,真心希望后面能睡个好觉啊,现在最想拥有的能力就是到点倒头就睡的能力🥱。
15. 迎来终章,系统交互
15.1. 回顾第9章,实现fork
这一节用到了很多第9章线程切换的知识,我确实有点忘记了,于是我又翻回到第九章大致看了看。因为这一节涉及到进程切换的难点,所以这一节我要好好说道说道。
要实现fork,也就是说要从一个进程中创建一个一模一样的进程出来。要创建进程,那么咱们就看看一个进程需要什么呢?回顾第9章可以知道,一个进程得需要一个PCB,这个PCB里面有用于中断的intr_stack和线程自己的内核栈thread_stack。要创建一模一样的进程?那咱们就直接把父进程的PCB复制过来不就行了嘛,当然啦,也不是全部拿过来用了,还是得个性化的修改一下呢。在我们的实现中,第一步就是创建子进程的PCB,这就是函数copy_PCB_and_vaddr_bitmap做的事情:
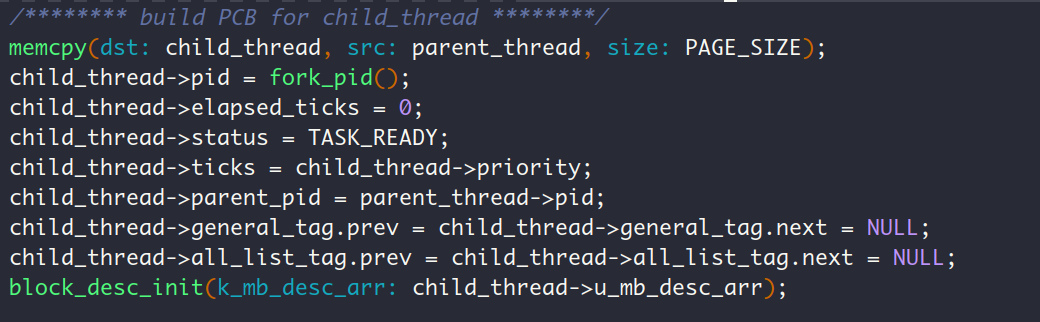
注意哈,这里子进程调用函数block_desc_init重新初始化了自己的用于堆内存管理的内存块描述符,而不是使用父进程的内存块描述符。这是因为进程之间的堆内存管理应该隔离。如果不隔离的话,如果父进程修改了堆(如分配或释放内存块),这将影响共享的内存块描述符,进而影响到另一个进程。当子进程使用从父进程继承的内存块描述符来分配内存时,它可能会基于不正确或过时的信息进行操作。因为描述符中的信息可能已经由父进程修改过。
现在咱们的进程宝宝已经有了自己的PCB了,但在PCB中要根据子进程个性化修改的可不止上面这几个赋值语句呢。子进程管理虚拟内存池用到的位图 (进程有自己独立的地址空间,2个进程总不可能用一个位图来管理自己的虚拟内存吧),内核栈thread_stack都得独立于父进程。于是就有了为子进程分别创建位图和内核栈的过程:
创建位图
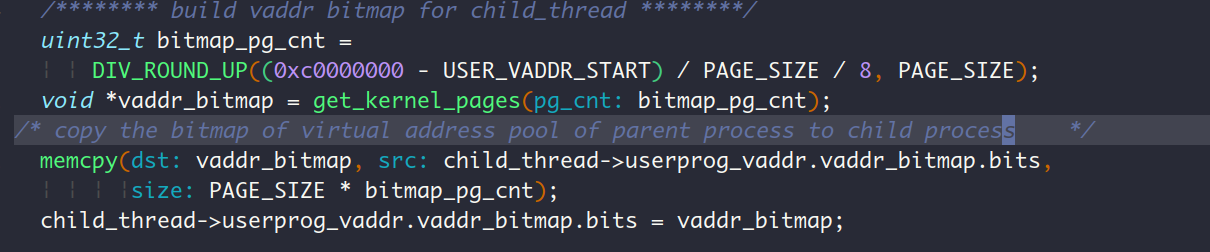
创建内核栈:
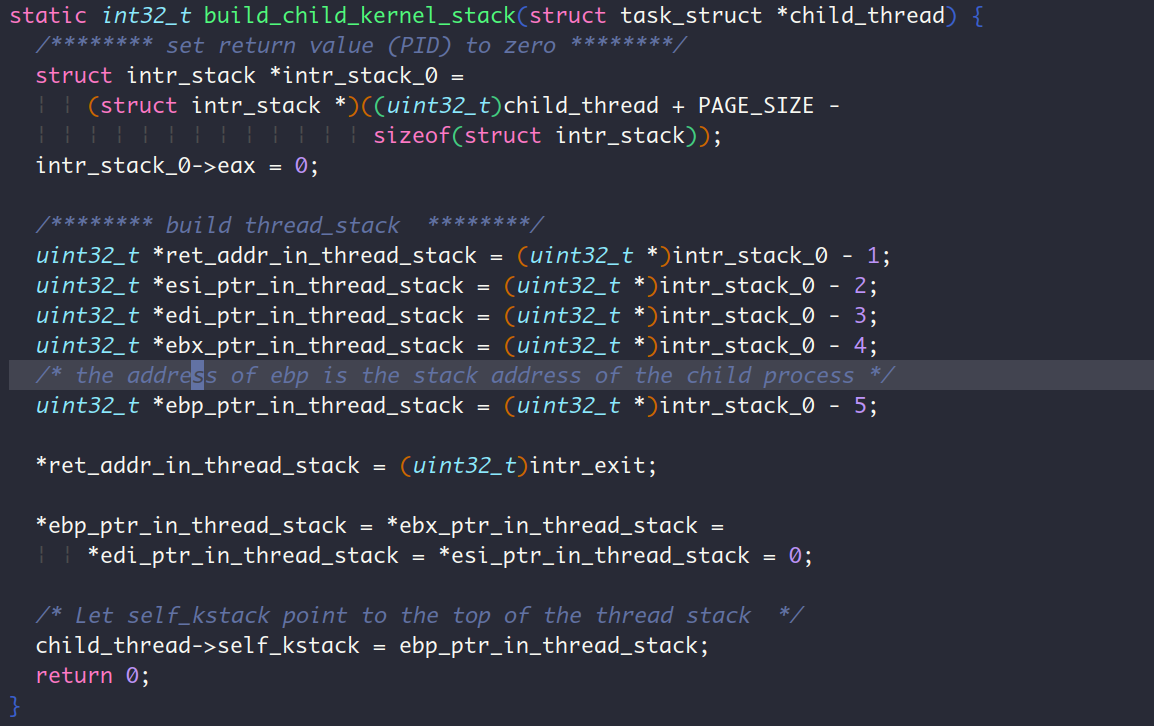
这个内核栈的创建过程是真得好好说说,这里涉及了第9章进程切换的知识。从P.509的图11-13表示的栈布局可以看出,ebp位于内核栈的顶部,它的地址就是内核栈thread_stack的地址,咱们得把它的地址保存在PCB的self_stack中,因为进程调度时执行的switch_to函数在切换PCB时,就是通过PCB的第一个成员self_stack来获取的内核栈的地址的(这部分可以见P.433刚哥对switch_to函数的讨论)。ret_addr位于内核栈的顶部,从switch_to函数退出的时候,就是返回到这个地址中继续执行,我们把它设置成了intr_exit,目的是它子进程直接从中断返回。注意这里哈,和第9章不一样,第9章是从switch_to函数返回到schedule再返回到中断处理函数再返回到intr_exit()。
进程可不能只有个PCB啊,这玩意只是被操作系统调度模块所需要,进程自个还得有血有肉才是,也就是说进程得有自己的进程体(代码段数据段等),这部分直接把父进程的copy过来就行了,反正父子进程执行的是独立且相同的代码。这里要注意的是,子进程被重新调度之后,是接着fork()函数之后的流程开始执行,所以呢,它拥有的用户栈得和父进程一样。这是由函数copy_body_and_userstack完成的。
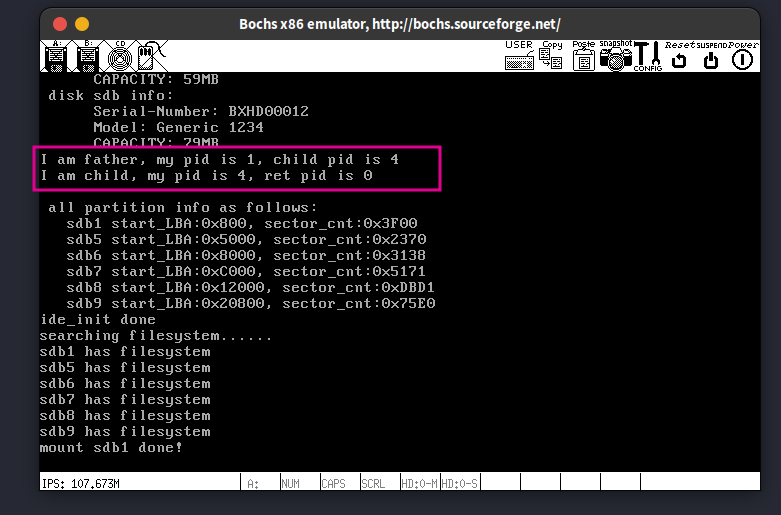
运行结果:
15.2. 打造我的Shell
15.2.1. 先搓个Shell雏形
这一节在sys_read,putchar和键盘驱动程序的基础上初步建立了一个shell。有趣的是刚哥取得用户名是rabbit,不知道各位看书的时候是否注意到,在第7章开头刚哥提到了他女朋友叫王小兔,这正好对应上了,可见刚哥也是很有风趣的😜。
这一节也不是那么一帆风顺,我在readline的实现中,错把下面的1写成了count,导致这个shell进程一直卡在sys_read的ioq_getchar处,进而导致我的终端对键盘输入毫无反应(输入不满count个字符)。排查了一番才找到错误。

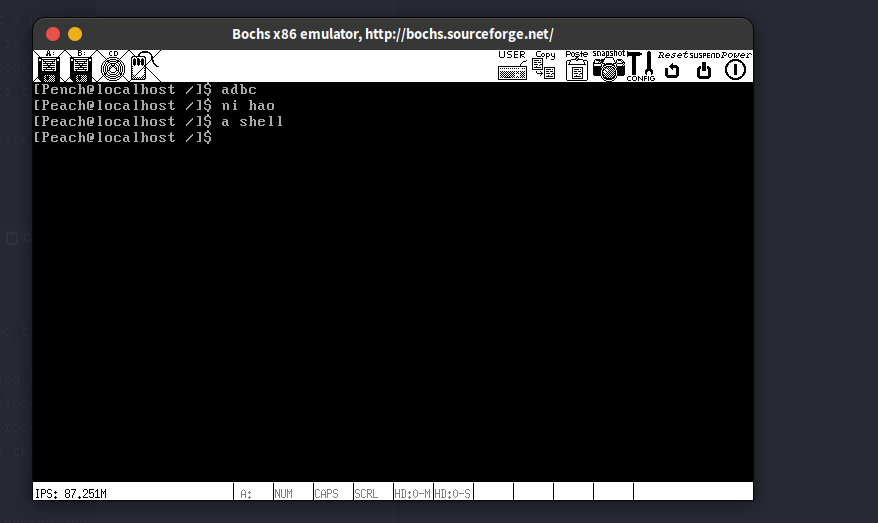
这里我取的用户名是Peach,也是对应了我最重要的人之一。
运行结果:
15.2.2. 让雏形稍微动起来,实现Ctrl+l清除屏幕和Ctrl+u清除当前行
本质上就是在键盘中断程序中,把Ctrl+l和Ctrl+u通过cur_char-='a'的形式映射到某个控制字符,然后对这个控制字符在readline中专门处理,还是第10章那句话,什么字符表现为什么形式是由我们说了算😎
运行结果:
这种动态的运行结果,用ubuntu自带的录屏软件 (用ctrl+shift+alt+r启动) + ffmpeg生成gif (ffmpeg -i videofile output.gif),很方便
15.2.3. 解析命令
本质上就是提取出命令行中以空格分隔的参数
运行结果:
15.2.4. Shell中的路径解析
这节还是有点难度的,咱们的任务是把用户输入的不规整的路径转换为规整的路径格式,比如说把/a/b/../c转变为/a/c,这样的规整路径交给cd, ls等命令,才好处理
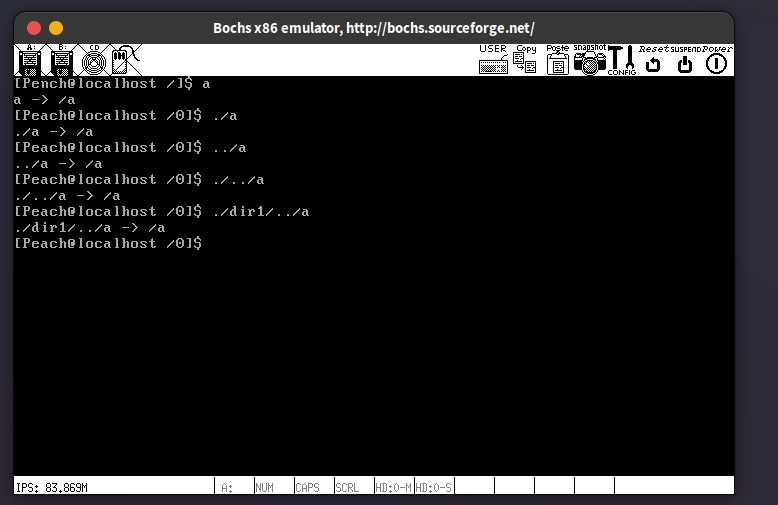
15.2.5. 让shell更名副其实!实现ls, cd, mkdir, ps, rm等命令
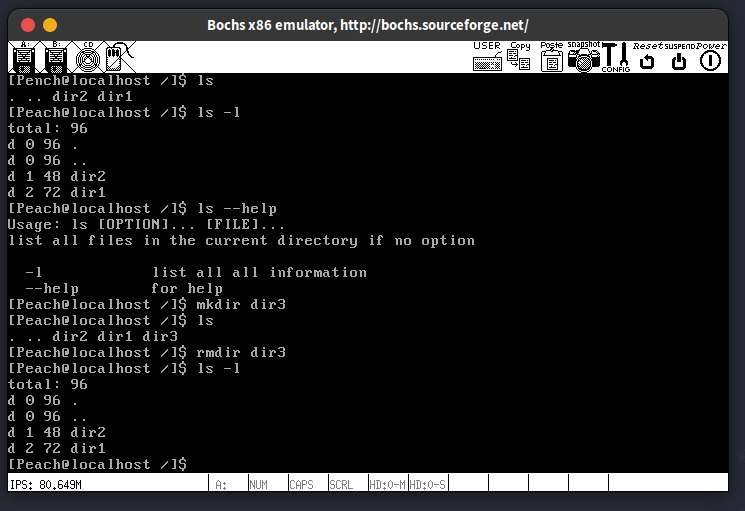
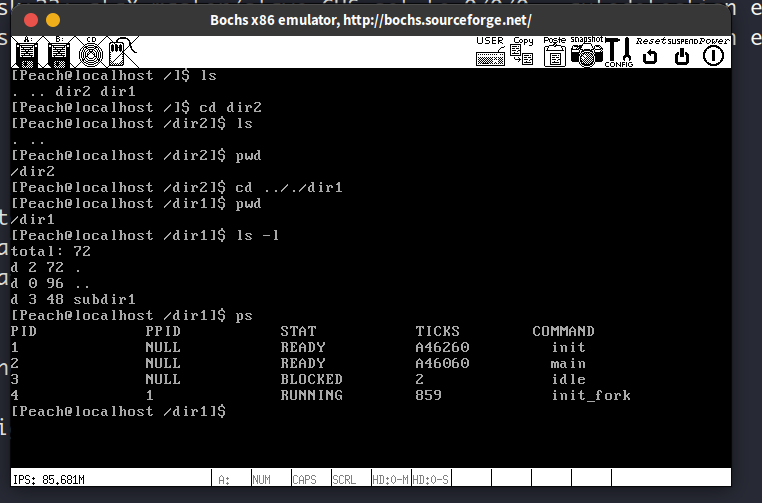
这一节仅在ls的实现上稍微复杂一点,而且还没有注释,不过仔细看看还是看得懂。我的ls支持选项-l和--help,因为-h对linux上的ls命令来说是–human-readable的意思,所以我改成了--help,此外各种输出提示我也是照着linux上实现的。之前一直没用到的all_list_tag总算在实现ps的时候派上了用场。
部分命令运行结果:
15.3. 加载用户进程
先谈谈处理用户程序这部分。需要额外再写一个assert.c,实现逻辑与debug.c一样,之前写shell的时候遇到过assert,我都是直接在debug.c中加了句#define assert ASSERT解决的,现在用户程序prog_no_arg需要assert.c,就必须得写一个了。此外编译出的prog_no_arg的实际大小远大于刚哥所说的4777,我估计是页对齐的原因。加载用户可执行文件的逻辑本质上是这样的:把可执行文件先写入裸盘hd60M.img,再在内核中通过ide_read把文件的数据从hd60M.img中读到位于内核的堆空间的缓冲区,接着在通过文件系统接口sys_write把缓冲区的数据写入文件系统所在的硬盘hd80M.img(更准确的说是第一个分区sdb1)
最后便是execv的实现,这个函数本质上就是做了这样一件事情:读取用户的ELF文件的文件头和程序头表,并根据这2个表的信息完成ELF文件的加载,具体来说是类型为LOAD的segment的加载。关于这部分,我强烈建议各位看官先去看看程序员的自我修改—链接,装载与库这本书,直接看第三章就够了。ELF文件加载完了之后,就开始进程体的替换了,用刚加载的用户程序的进程体换掉老进程的进程体,关键的步骤就是修改老进程的eip为用户程序的入口地址entry_point,然后假装从中断返回。各位看看代码就知道了。
这一节做的相当久,原因是我遇到了下面这样的页错误:

上面的hello,success之类的语句是我为了调试定位加的,大家可以忽略。经过定位,我发现load函数在加载ELF文件的第2个segment的时候触发了页错误。我一直以来都是用bochs原生的调试功能,但在这一节就显得太捉襟见肘,连查看变量的值都是那么麻烦,对C语言太不友好了,之前的C程序调试基本都是靠加打印语句和审查代码能查出来,这下我不得不换成gdb调试(结果发现异常好用!)。
因此现在补充一下如何配置bochs+gdb (Using Bochs and the remote GDB stub)
- 重新编译bochs,使其支持gdb远程调试
./configure \
--prefix=/home/elite-zx/bochs \
--enable-gdb-stub \
--enable-iodebug \
--enable-x86-debugger \
--with-x \
--with-x11
make -j $(nproc) && make install修改bochs配置信息,追加下面的内容
# gdb part setting
gdbstub: enabled=1, port=1234, text_base=0, data_base=0, bss_base=0- 让ELF文件包含调试信息
修改makefile, 在gcc的选项中加入-g, 我查了下gcc的man手册,顺手把这个选项的含义贴在这里:

- 使用gdb远程调试
接着用bochs -f bochsrc.disk启动bochs,再启动gdb(推荐用gdb -tui的形式启动gdb,更直观),最后在gdb中输入下面的命令,sysmbol-file后面跟着的是内核文件的路径
target remote localhost:1234
symbol-file /home/elite-zx/build-OS-from-scratch/build/kernel.bin效果如下, 之后咱们就可以用gdb调试啦
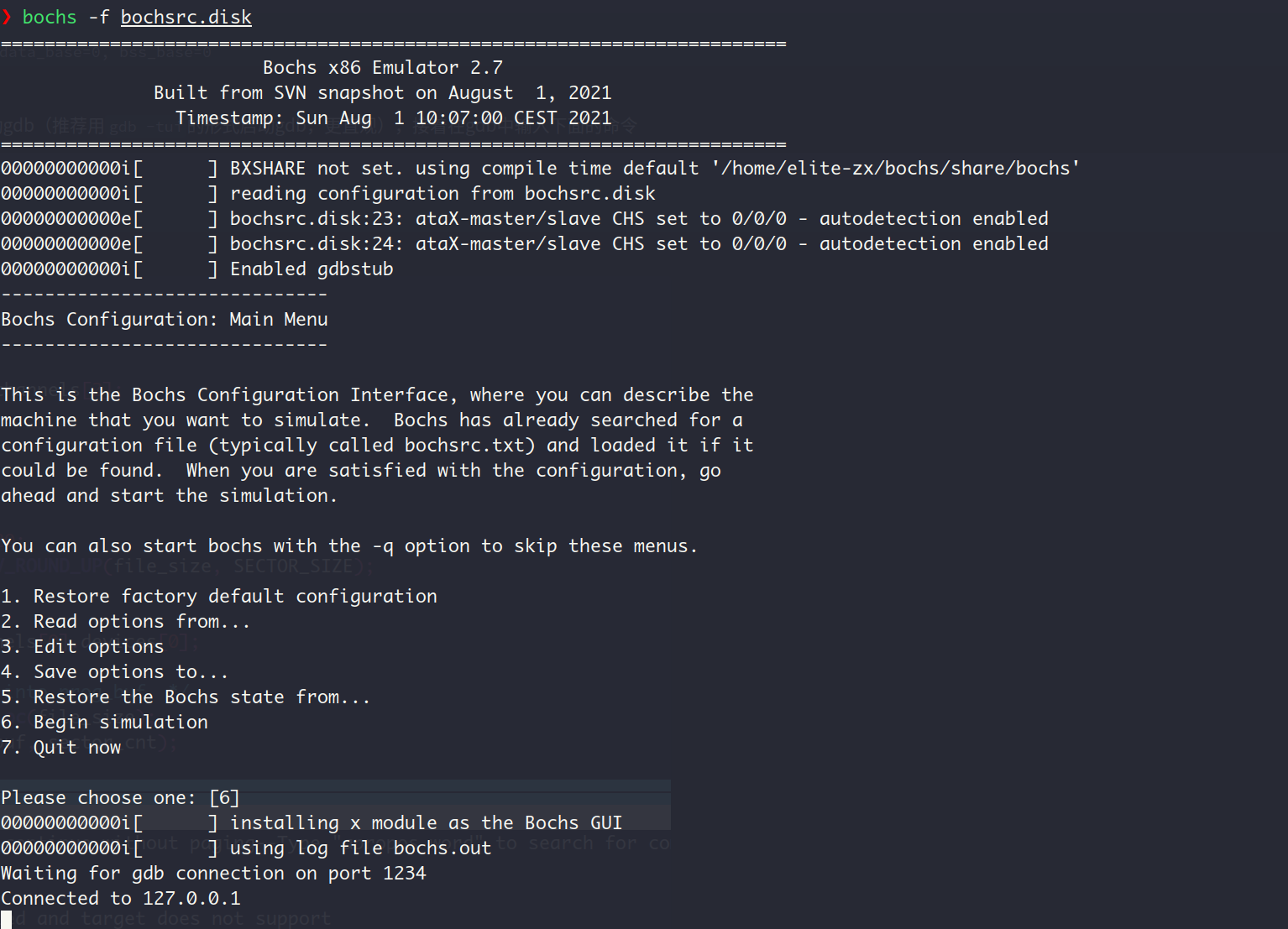
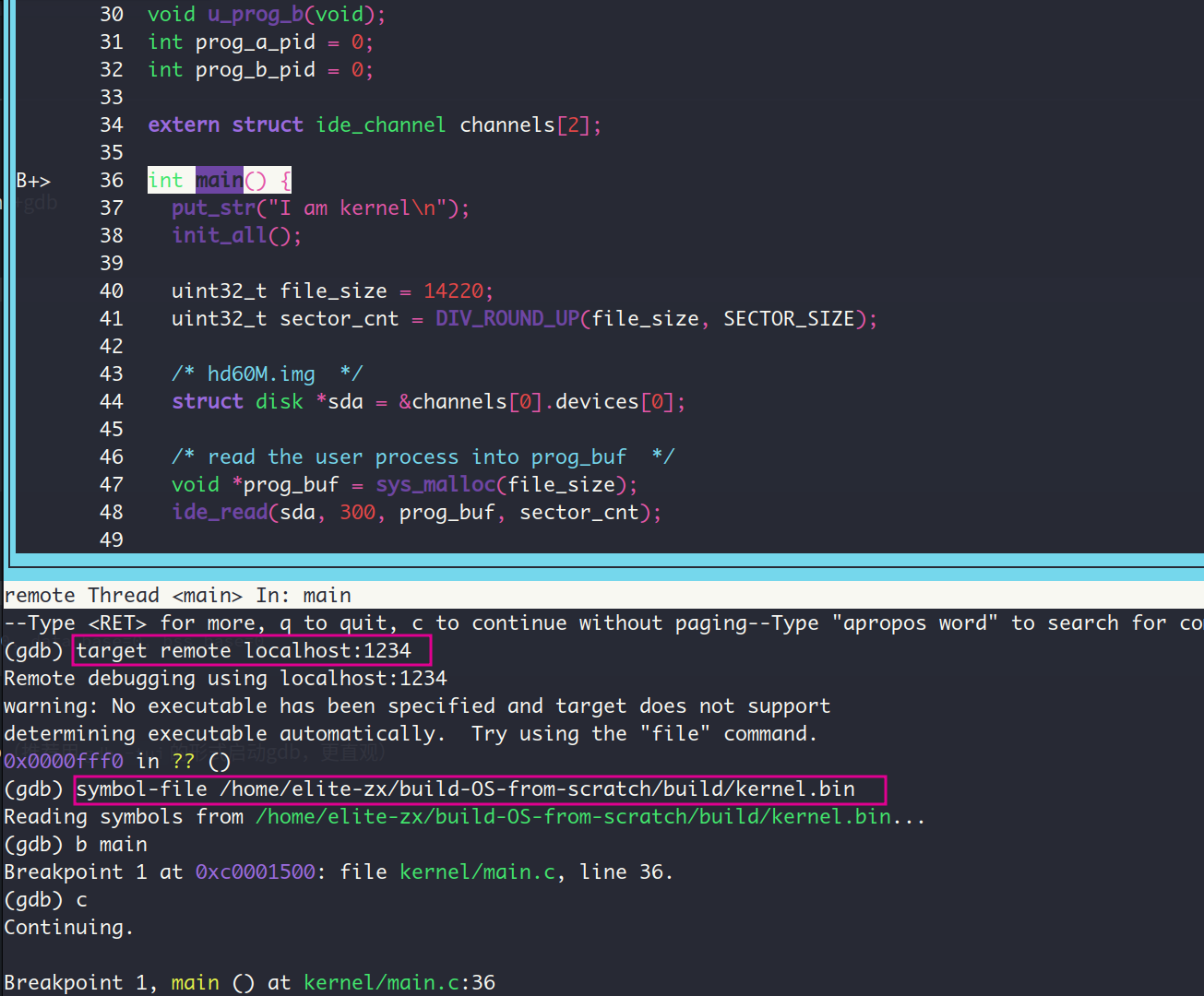
这里各位看官可能有跟我一样的疑惑?这里为什么要用gdb的命令sysmbol-file手动的加载内核文件的调试信息呢 ,实际上经过我的实践,这里如果不手动加载调试信息的话,gdb是找不到的。我问了下GPT-4, 把它的回答贴在这里:
当您在 GDB 中调试内核或类似于内核的低级程序时,可能需要手动加载符号表。这主要是因为这类程序通常以一种与常规用户空间程序不同的方式加载和运行。在用户空间程序的情况下,操作系统加载器(如 Linux 上的 exec)负责加载程序并准备执行环境,其中包括设置用于调试的必要信息。GDB 依赖于这些信息来自动加载符号表。
然而,对于内核或其他低级系统程序,这些程序通常由引导加载程序(bootloader)在没有操作系统加载器的帮助下加载。例如,在引导一个操作系统时,内核是由引导加载程序直接加载的,没有标准的加载器来设置调试信息。因此,GDB 无法自动加载内核的符号表,需要您手动指定。
使用 symbol-file 命令手动加载符号表是在这种情况下获取调试信息的标准做法。您提供给 symbol-file 命令的路径应该指向包含调试符号的内核文件。
gdb的用法,可以参考Beej’s Quick Guide to GDB,网站虽然很老,但是内容很实用。此外,提醒各位,按住shift可以在gdb中选中内容,然后进行复制,这样会方便许多。
下面开始我的调试之路,我是怎么找出错误点的。
查看prog_no_arg的程序头表中的segment信息
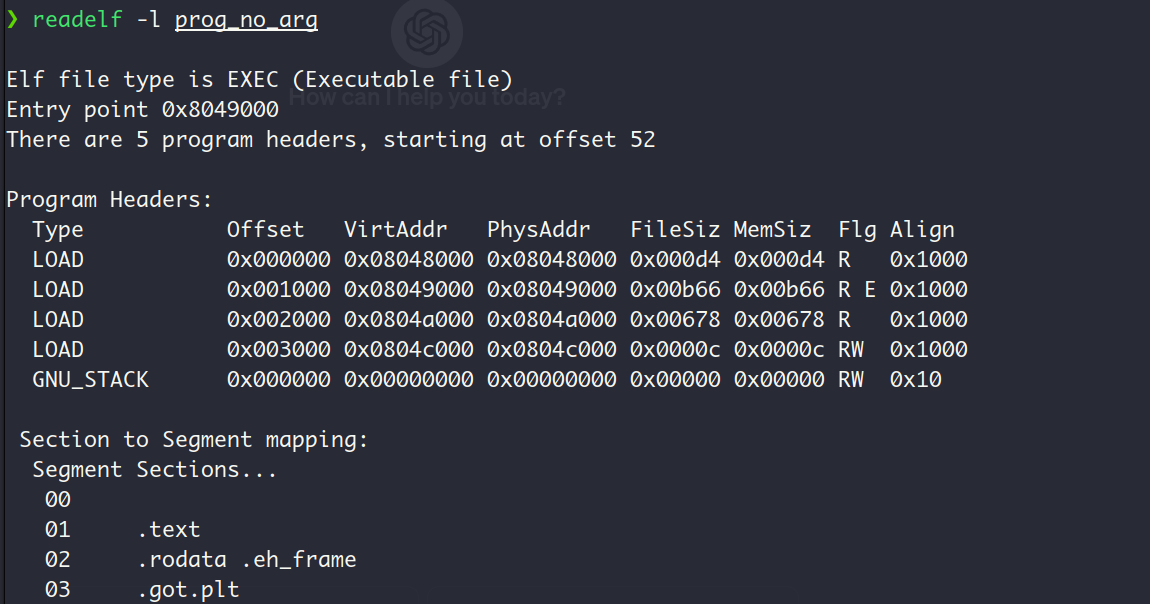
在开始加载segment之前,查看文件头中关于程序头表的信息:
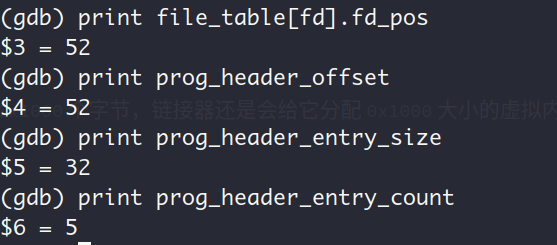
prog_header_entry_count显示程序头表中有5个项,即一共有5个segment, 这与上图中readelf -l的输出结果相符合。此时的文件指针偏移量为52,这是因为在load函数的前半部分,咱们先把用户文件prog_no_arg的文件头读进来了,不信的话各位看官可以看看用户文件prog_no_arg的文件头大小:
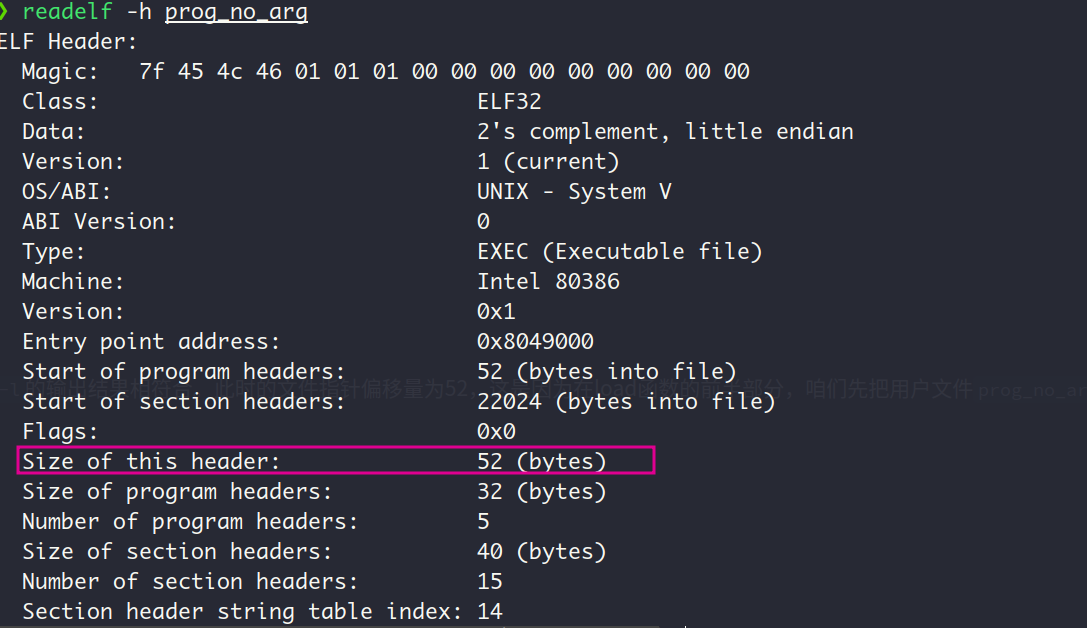
正是52个字节的大小,而且 上图中的size of program headers字段为32, 表明程序头表的每一个项为32个字节,这与上述的prog_header_entry_size的值相符合 QvQ
下面开始加载segment1:
进入segment_load函数之后,打印segment的大小:

这与readelf -l的输出中FileSize字段的值吻合。
接着看看这个segment所处的虚拟页和在虚拟页中的偏移(无偏移)
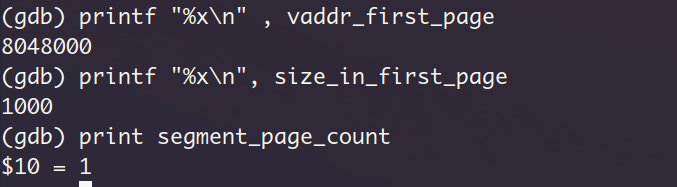
readelf -l输出中的Align字段表示了segment的对齐属性,因此即使segment本身的大小不超过0x1000个字节,链接器还是会给它分配0x1000大小的虚拟内存空间,所以第一个segment的大小在这里显示的是0x1000,此处的804800也符合在函数create_user_vaddr_bitmap中设置的用户进程起始虚拟地址(vaddr_start)。
看样子刚哥在P.719所说的文件的第一个段的起始地址都不是自然页有些过时了,链接器确保了文件的segment是页对齐的。现在我应该能猜到为什么我的prog_no_arg文件的大小远大于刚哥所说的4777个字节了,因为我的prog_no_arg遵循页对齐。
不得不说,这一节用到了大量的有关ELF文件格式,链接,加载运行方面的知识,要不是之前读过这方面的书,我可能是真的一脸懵(虽然读过但好像也不是特别清楚 QAQ)
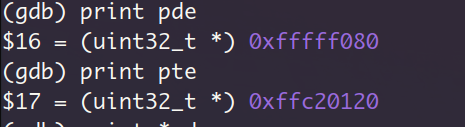
segment1的页目录项和页表项对应的虚拟地址,前者高20位是均为1以索引页目录表,后者高10位均为1以索引页表。查看页目录项和页表项的实际内容,可以发现其present位都为1

segment1看样子是成功加载了,下面看看segment2:
读取一个32字节的程序头表项之后,此时的文件指针偏移量变成84
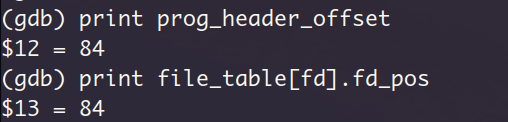
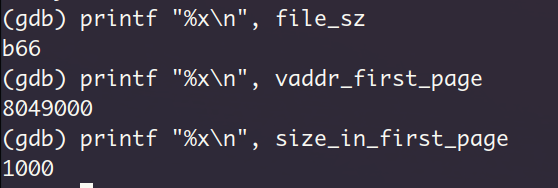
查看segment2所处的虚拟页信息,依旧是页对齐的形式,实际大小b66与readelf -l的输出相符

页目录项和页表项,页表项在segment1的基础上加了一个项的大小(4个字节),这意味着segment2所处的虚拟页紧跟在segment1的虚拟页之后
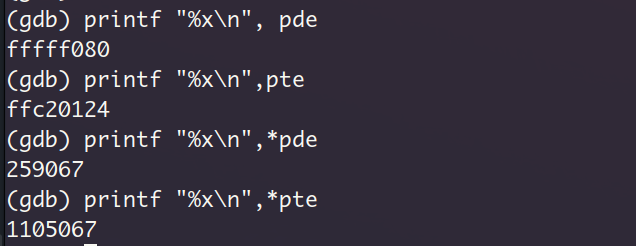
下面就是调用sys_read读取这个segment, 具体来说,就是读取从虚拟地址0x804900开始的一个页,进入sys_read,再跳转到file_read,从文件prog_no_arg中偏移量为4096的位置开始读取0xb66个字节。这里的4096是怎么回事?其实这是segment2中由prog_header.p_offset指示的偏移量,从之前的readelf -l的输出就可以看出。而且在segment2之前已经有一个4KB的segment1了,所以偏移量是4096
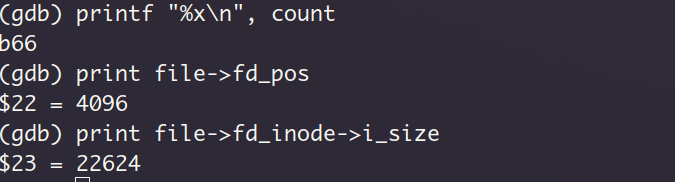
一共分配了6个数据块(编号8~13), 这个数字怎么来的呢?因为咱实际读取的字节数是0xb66,换算为十进制就是2918,一个数据块大小为512个字节, 向上取整,得到所需数据块数量为6。为了保险,我还是打印了blocks_required_read的值,该值表示待读取的数据块数量,!!!这里居然是一个巨大的值,原因很简单,就是无符号数的回绕,因为我用一个小的值block_read_start_idx减去了一个大的值block_read_end_idx。但其实这里blocks_required_read的值对流程的影响并不大,后续分支只是判断它是不是0而已。
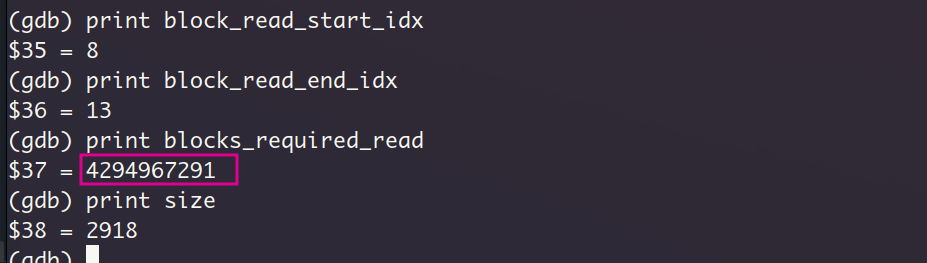

下面开始读入。因为是页对齐的,所以不存在第一个数据块存在旧数据的情况(数据块被完全覆盖),因此第一次读入也是以块为单位
4次循环后查看还未读取的数据量,确实是刚读了2048个字节()

读取完size个字节后,进入释放all_blocks_addr和io_buf的内存阶段。

这2个变量在用户内存池中占有的大小分别是512个字节和560个字节
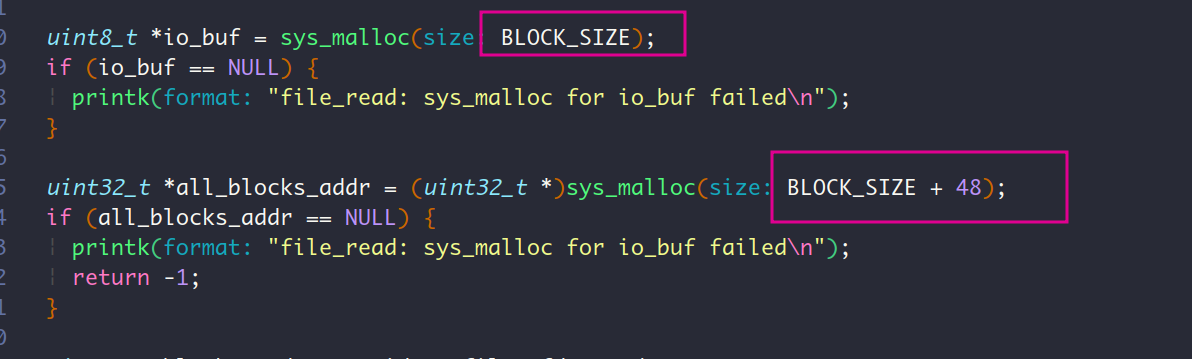
先看sys_free(all_blocks_addr),因为是用户进程,所以从用户内存池中释放
先看看对all_blocks_addr的释放过程,按照sys_malloc的逻辑,应该分配给了它一个1024大小的内存块,咱们在sys_free中查看它占有的块对应的描述符中的信息,块大小果然是1024,该类型的arena中的数据块一共是3个,因为4KB的页其中元数据要占有一小部分,因此剩余的空间,平均分成1024的块的话,只能分成3份,初始化描述符是在函数block_desc_init中实现的,从这里确实可以看出,我们的sys_malloc实现是真没啥问题,问题一定是出在sys_free这里。
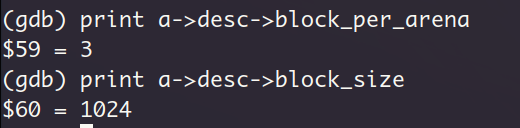
因为在1024类型的arena中只分配了一个数据块给all_blocks_addr,因此回收这个数据块的时候会导致把整个arena回收(回顾一下第12章,在sys_free中如果arena中全是空闲数据块,那么就回收整个arena)。还是验证一下,查看当前arena的元信息(该元信息在文件memory.c中声明为结构体 struct arena)中的cnt字段
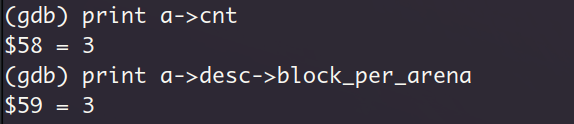
因此现在sys_free进入了回收arena的代码块
对all_blocks_addr的释放没有触发页错误,接着我们看对sys_free(io_buf)。
执行到这里的时候发生了页错误:
此处应该是512字节大小类型的arena,但其描述符中的信息是乱码
回到给io_buf分配内存的sys_malloc语句,进去看看
分配的确实是类型为512字节的arena
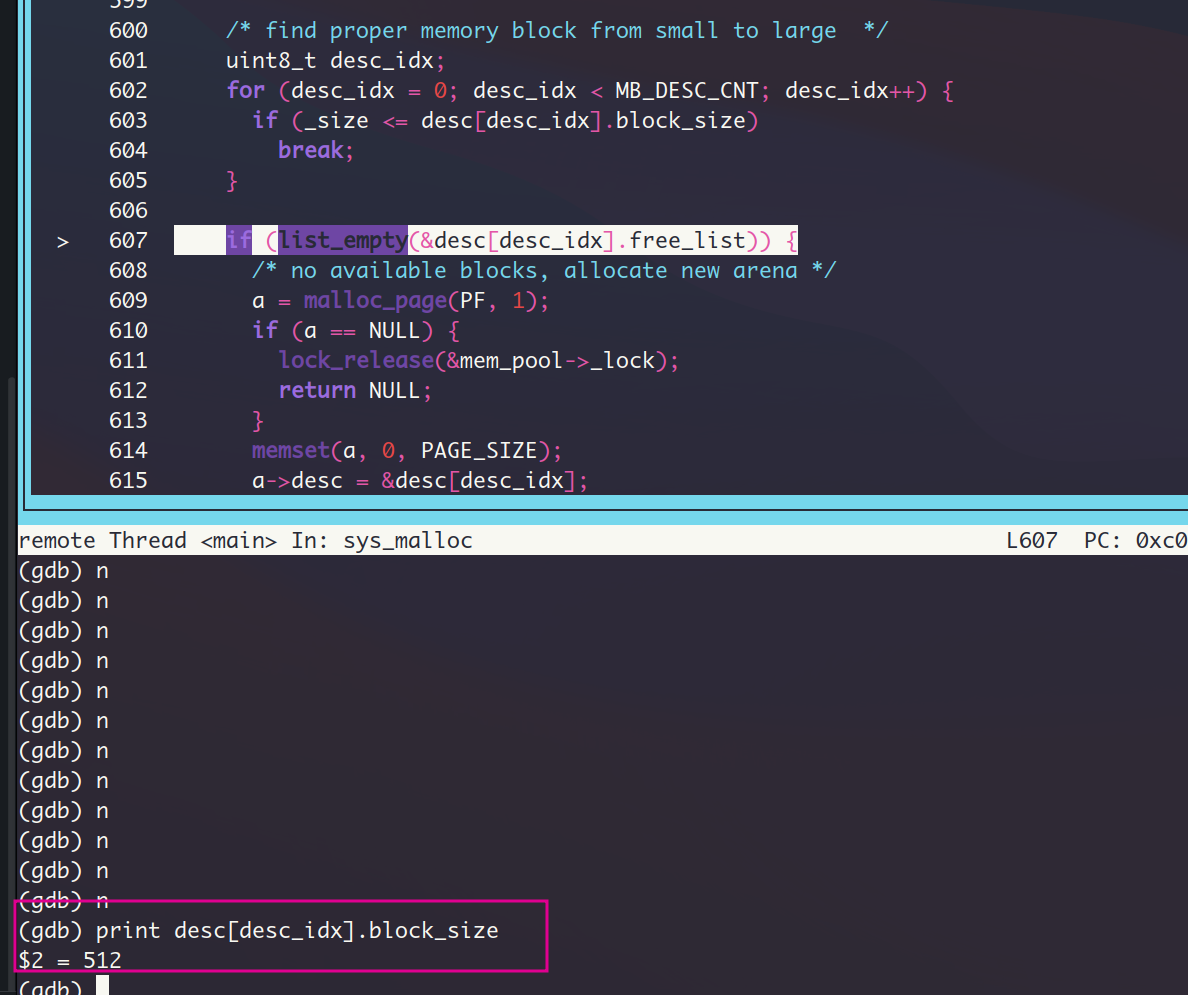

执行流程没有进入list_empty分支

查看free_list的值,head和tail确实不符合list_empty的plist->head.next == &plist->tail的条件,但是这个free_list的值明显是不对的 (😢)。 下面的打印的指针值明显是不正确的,next指针的值成了0x804960c,该地址下的内容又是head的地址,等于说head的next成员成了head的二级指针,看样子必须回到前一次segment的加载过程,看看512类型的arena怎么出错了。
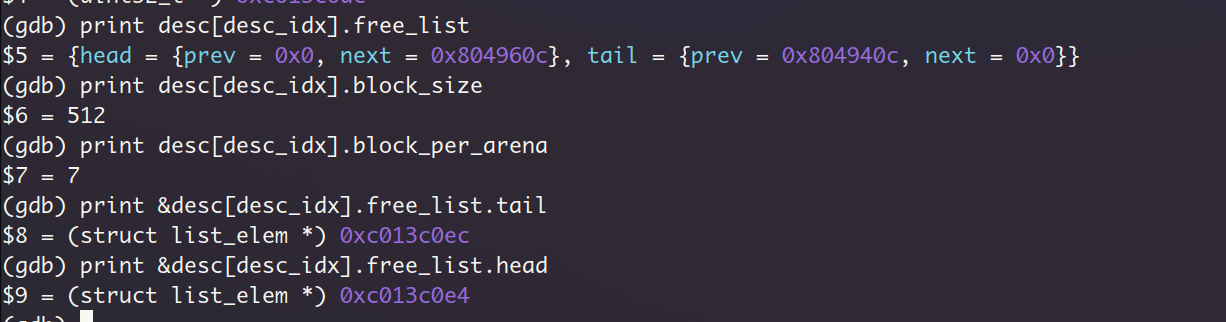

回到加载segment1的过程中,进入给io_buf分配内存的sys_malloc,分配给io_buf一个数据块之后,还有5个512字节块。
这里应该是有问题的啊,首先吧,现在我们执行的进程是由Shell进程fork而来的,然后在调用execv用 用户进程的进程体取代当前进程的进程体。所以目前这个进程的块描述符应该是才初始化过的,我检查了下,虽然在进入segment_load函数之前,该进程中调用过几次sys_malloc,但都在函数末尾释放了的,这意味着现在的块文件描述符对应的arena应该是空的才对,这里为什么会有一个被分配出去的512数据块呢?
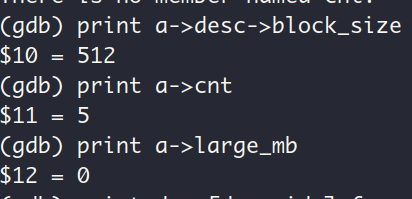
为了搞清楚这个问题,我决定回到fork结束之后,刚进入子进程的时间点,查看此时子进程的块描述符数组u_mb_desc_arr。怎么进程PCB的内容全部变成0了😅
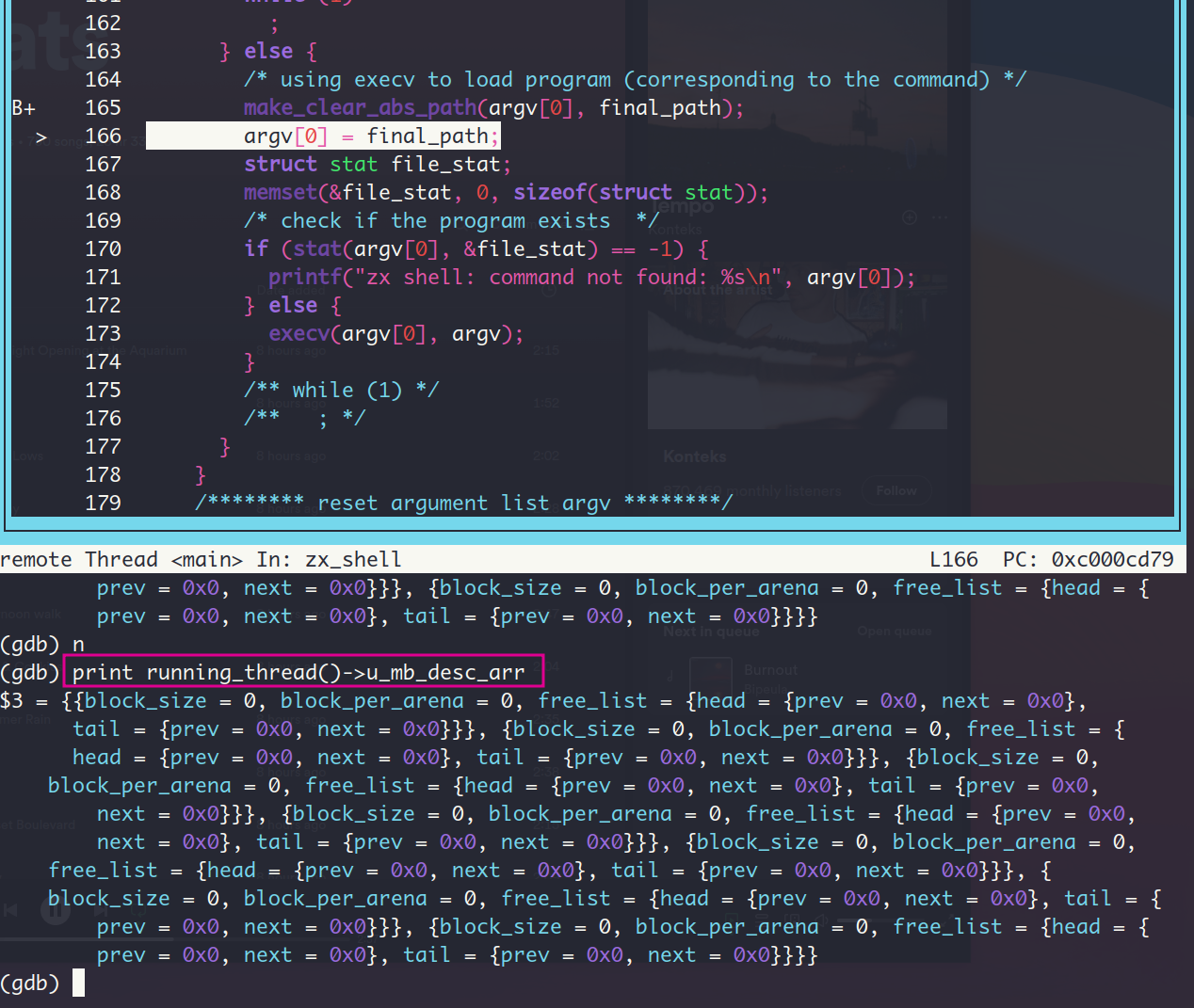
子进程pid居然也为0…, 我现在的情绪是这样的😫。
那么回顾下内核启动以来调用fork的地方,先是在init进程中调用fork创建了子进程shell,通过ps命令就可以知道,这个fork到没啥问题。

。。。我现在的情绪依旧是这样的😫, 因为我查看了其他几个进程的pid,除了main以外,包括init进程在内,只要是用running_thread()->pid打印pid的值,结果都是0,真是抽风啊!!!。 ps命令能正确运行是因为它是通过all_list_tag获取的进程PCB,而不是running_thread,但是running_thread的实现也没什么问题😥。此外,fork的返回值也是正确的pid值。
在函数block_desc_init中检查512类型的arena的描述符的初始化过程:
对于512大小的arena, 一个arena(一页)中可以放7个数据块

刚初始化的描述符free_list为空,head指向tail,说明函数block_desc_init初始化的过程没什么问题

行吧,这个running_thread()获取的PCB打印为0的事情就先不管了。既然段错误发生的核心原因是因为进入segment_load之前,进程的块描述符的free_list不是为空的状态。那么我就在进入segment_load函数的前一步再调用一次block_desc_init重新初始化进程的块描述符,这样就能保证free_list为0了,这样做也确实能正确的让用户进程加载并执行。

但是这样的话,在重新初始化之前记录在块描述符的free_list中的空闲数据块就丢失了,造成了内存泄露了。因此这个办法还是有问题的🙃。
16. 结语
这个execv内触发的page fault, 我从前天晚上调试到今天晚上,一共是用了2天。我几乎把堆内存管理的代码又过了一遍,也没能发现哪里导致了512大小类型的arena的异常,最终只能在进入segment_load之前强制重新初始化块描述符并以内存泄露的代价勉强完成用户进程的加载。其实我内心还是很失落的,我确实是想从0开始手搓一个操作系统内核的,这个内核当然是功能越完整越好。因为现在已经出现了我解决不了的问题,因此后续系统调用wait,exit和管道的内容哪怕我把代码敲上去也看不到运行结果,所以我就不准备是实现了。
从git log记录来看,我的OS kernel的首次提交是在10.31号,到今天(12.15号)有了差不多快一百次提交,如果之前的CS144和实习期间做的一个grpc后端服务不算的话,这应该算是我第一个完成大型的个人项目。我本来给自己定的完成的时间就是12.15号(本来是12.10号,但没想到文件系统的内容这么多),除去11月的几个出去散步了的周末和几个晚上严重失眠的疲惫的天数之外,从实现MBR开始一直到实现系统调用execv一共用了差不多40天的时间。我也不是一个特别自律的人,而且我还是居家学习,不是在像图书馆那样的有氛围的地方, 所以我基本上最多连着学一个小时就会开始坐不住了,最开始下了个番茄钟来培养固定学习时间段,后来我发现不用这玩意我学的更好更久,就没用了。因此这40天内,我大概平均每天花了5个小时在这个项目上面,看书,写代码和写博客记录,时间跨度大概就是这样,供大家参考。
写到这,我也想回顾一下我自大学以来走过的路。我想先分析一点,那就是从进入大学到现在,我是怎么一步一步落到今天这副局面的。我认为我主要犯了2个错误。一是刚上大学的时候,意识不到位。不去涉及CS专业相关的信息,不去关心怎么学,重点学什么,专业前景是什么,加上没能认清大学的本质(关于这一点,我强烈推荐每个有个人规划的大学生都去看看:上交大生存手册),再加上没有利用好假期,导致自己做了一年半的无用功。我现在都记得,在大二下开设操作系统课程的时候,在第一节课上,老师指着ubuntu的图标问我们是什么,我当时是见都没见过。课后让我们写一个shell脚本,我费力安装好ubuntu之后,完全不晓得怎么操作,更别说写shell脚本了,那时候连ls命令都不知道。二是过去一年大部分时间的学习是比较低效率的,学习方法上脱离实践,太专注于纸面上的理解。我记得大二下册的五月的一个晚上,我受到了一个与我同名的,极有自驱力,目标极其清晰的人的影响(现在他已经去了微信部门),这里就称他为X吧,我现在还记得在那天晚上我看他的博客看到了凌晨2点,深有感触。于是我开始纠正过去一年半的错误,着手学习专业相关的技能了,但是我毕竟之前从未认真学习过CS方面的知识和技能,我可以这么说,在大二结束的时候,我只会C语言基础和一点C++皮毛,操作系统,数据库和计算机组成原理能把考试考过,别的就没了,而且我也没有去搜集过怎么学习计算机知识的经验之谈,所以那时我学习计算机知识的方法是相当差的,首当其冲的就是大二暑假留校学习数据结构的时候,当时看的是数据结构与算法C++描述这本书,我居然耗时耗力的去把章节后面的30多道习题做了,而不是选择去刷一些leetcode。这个数据结构的学习花了我很久的时间,而且效果绝对还没有每天刷leetcode的人学到的多。学完了数据结构之后,我就开始看CSAPP了,这里也是犯了一个大忌,我居然在英语水平并不是那么高的情况下, 牺牲效率去看英文原版,这样的行为的结果就是一个月才能看完一章并做完对应的实验。之后我看计算机网络自顶向下的时候也看了英文原版,加上没接触过计算机网络,抓不住重点,第一章就看了大半个月。听起来很好笑对吧,我现在回想起来也觉得很好笑。直到今年年初跟X打了个视频,才意识到这样看英文原版的行为非常不适合我,学到的不仅不比看中文版的多,而且效率还很低。接着就是大三下开学了,那时候身边的人都开始准备考研和实习了,我既不准备考研,也没能力找实习,所以我就开始蹲在图书馆补基础。把CSAPP的bomblab和这之后的2个lab做完了之后,我就开始学习重新操作系统了,花了一个半月的时间把哈工大李志军的OS课程听完了,并完成了所有实验。这其中其实也做了无用功,那就是我每看一章就写一章的笔记,哪怕不是搞的很清楚,也要写,现在看来写这些笔记确实没什么用。OS学完了之后,我就开始重新看计算机网络自顶向下,一路看到了网络层,把前三章的所有课后实验完成了,最后还去把CS144给写了,当然啦,因为自个没怎么学过C++,完成CS144的时候还是遇到了一些麻烦的。学计网的时候也是,爱记笔记,虽然也重视实践了,但是总的来说记笔记还是拉低了效率。计网学了之后,我就开始学习网络编程了,开始看起了TCP/IP网络编程这本书,这样大三上就过去了。在六月份的时候自己还是很想找一个暑期实习,于是我还是凭着上半年学过的知识和写的小玩具在我们学院院长开设的小公司里面获得了实习岗位,在大三暑假我就开始实习生涯了。实习期间,我去把grpc的框架学了,搭建了一个简单的grpc后端服务,这期间确实是意识到自己C++知识太欠缺了,于是八月份把C++ Primer过了一遍,网络编程的学习也在继续,暑假七八月份把TCP/IP网络编程看完了并完成了所有实践和把linux高性能编程这本书看了个七七八八,实例也大部分都写了。九月份看了程序员的自我修养—链接装载与库这本书,也正是在看这本书的中途,我彻底意识到了这样边看书,边在笔记中重述书的内容的方式是极其偏离实践的,从那时候开始我便认定了learning by doing这个学习方法。然后到了十月份,其实在九月份的时候我就意识到这份实习给我带来是提升和体验十分有限,而且还占据了我的学习时间,于是十月份我就准备抓紧搞完交代的项目后办理离职,最后也是在十月底的时候离职了,离开了待了七八年的重庆来到了浙江宁波,开始了闭关修炼之路,这个小型操作系统也是我闭关修炼完成的第一个项目。
如果有看官看到这,肯定有疑问,我现在一个本该是大四的人了,还在这样一个阶段,不就是一个基本完蛋吗。确实是这样的,所以我才会在段落开头写“这副局面”,为了挽救这看似不可逆转的局面,我做了很多人不会做的事情,那就是休学一年。我先是在八月份留校实习期间找到辅导员探讨这件事的可行性,获得辅导员的同意之后,于九月初向学院提出了休学申请。当然,作为一个已经大四的人,我预想办理休学应该不是一件顺利的事情,但是很幸运的是我们的学院书记是一个很理解学生的人,在我给她交流了自己的想法之后,她还是同意了。之后学院院长也来找我谈过话,毕竟我是在他那实习,在交流之后,他也理解了我的做法,值得一提的是,他在谈话的第二天居然把我叫去跟客户谈话,现在我也不知道为什么。
实话说,我这一路走来是极其曲折的,现在总算是走上了正轨,今年这个小公司实习的经历也让我彻底认清自己是不会太愿意在一个小地方从事一份特别不起眼的工作的。在宁波呆的这些日子也让我确定我将来想定居的地方就是经济发达的地区,最好就是沿海这一带。但是,我也知道现在的我离自己的目标还差的很远很远,与那些真正厉害的人也差的很远很远,还要很努力很努力才能追上人家的脚步。
最后,贴一张刚写完文件系统时的桌面照片吧。